 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgemodeLing: A Novel Dataset for Testing Linguistic Reasoning in Language Models
Jun 24, 2024We introduce modeLing, a novel benchmark of Linguistics Olympiad-style puzzles which tests few-shot reasoning in AI systems. Solving these puzzles necessitates inferring aspects of a language's grammatical structure from a small number of examples. Such puzzles provide a natural testbed for language models, as they require compositional generalization and few-shot inductive reasoning. Consisting solely of new puzzles written specifically for this work, modeLing has no risk of appearing in the training data of existing AI systems: this ameliorates the risk of data leakage, a potential confounder for many prior evaluations of reasoning. Evaluating several large open source language models and GPT on our benchmark, we observe non-negligible accuracy, demonstrating few-shot emergent reasoning ability which cannot merely be attributed to shallow memorization. However, imperfect model performance suggests that modeLing can be used to measure further progress in linguistic reasoning.
LINGOLY: A Benchmark of Olympiad-Level Linguistic Reasoning Puzzles in Low-Resource and Extinct Languages
Jun 11, 2024



In this paper, we present the LingOly benchmark, a novel benchmark for advanced reasoning abilities in large language models. Using challenging Linguistic Olympiad puzzles, we evaluate (i) capabilities for in-context identification and generalisation of linguistic patterns in very low-resource or extinct languages, and (ii) abilities to follow complex task instructions. The LingOly benchmark covers more than 90 mostly low-resource languages, minimising issues of data contamination, and contains 1,133 problems across 6 formats and 5 levels of human difficulty. We assess performance with both direct accuracy and comparison to a no-context baseline to penalise memorisation. Scores from 11 state-of-the-art LLMs demonstrate the benchmark to be challenging, and models perform poorly on the higher difficulty problems. On harder problems, even the top model only achieved 38.7% accuracy, 24.7% improvement over the no-context baseline. Large closed models typically outperform open models, and in general, the higher resource the language, the better the scores. These results indicate, in absence of memorisation, true multi-step out-of-domain reasoning remains a challenge for current language models.
Neural Generation Meets Real People: Building a Social, Informative Open-Domain Dialogue Agent
Jul 25, 2022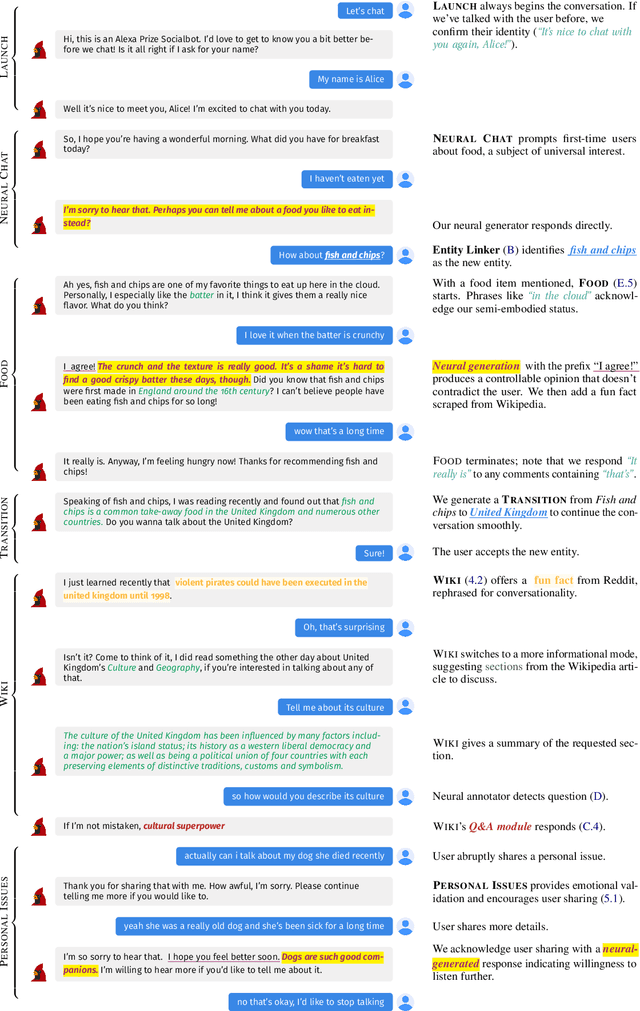


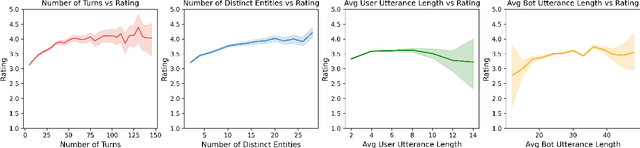
We present Chirpy Cardinal, an open-domain social chatbot. Aiming to be both informative and conversational, our bot chats with users in an authentic, emotionally intelligent way. By integrating controlled neural generation with scaffolded, hand-written dialogue, we let both the user and bot take turns driving the conversation, producing an engaging and socially fluent experience. Deployed in the fourth iteration of the Alexa Prize Socialbot Grand Challenge, Chirpy Cardinal handled thousands of conversations per day, placing second out of nine bots with an average user rating of 3.58/5.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
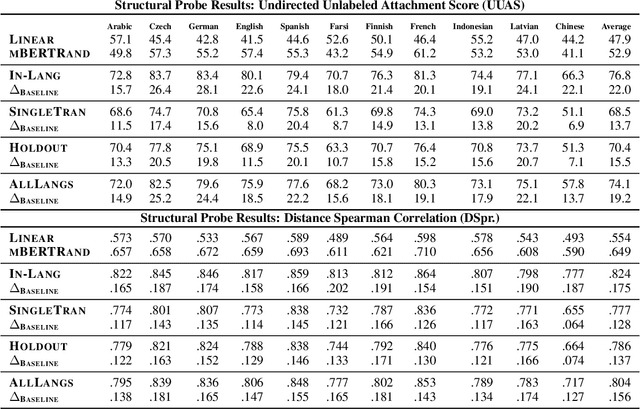
Deep Subjecthood: Higher-Order Grammatical Features in Multilingual BERT
Jan 26, 2021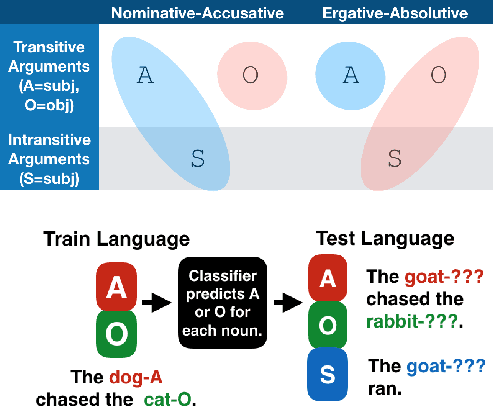
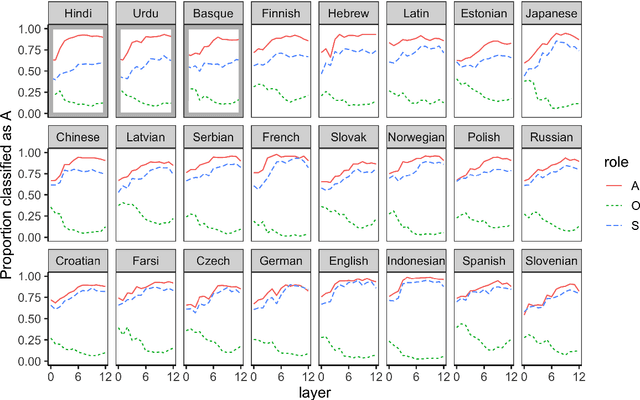
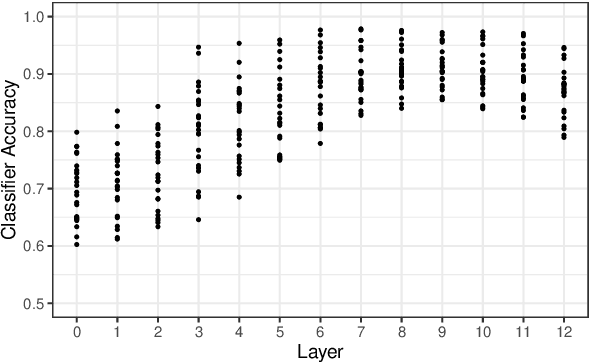
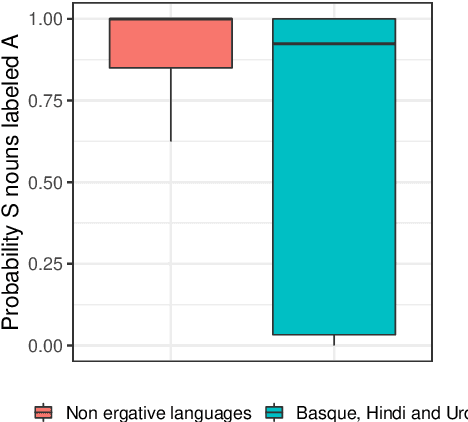
We investigate how Multilingual BERT (mBERT) encodes grammar by examining how the high-order grammatical feature of morphosyntactic alignment (how different languages define what counts as a "subject") is manifested across the embedding spaces of different languages. To understand if and how morphosyntactic alignment affects contextual embedding spaces, we train classifiers to recover the subjecthood of mBERT embeddings in transitive sentences (which do not contain overt information about morphosyntactic alignment) and then evaluate them zero-shot on intransitive sentences (where subjecthood classification depends on alignment), within and across languages. We find that the resulting classifier distributions reflect the morphosyntactic alignment of their training languages. Our results demonstrate that mBERT representations are influenced by high-level grammatical features that are not manifested in any one input sentence, and that this is robust across languages. Further examining the characteristics that our classifiers rely on, we find that features such as passive voice, animacy and case strongly correlate with classification decisions, suggesting that mBERT does not encode subjecthood purely syntactically, but that subjecthood embedding is continuous and dependent on semantic and discourse factors, as is proposed in much of the functional linguistics literature. Together, these results provide insight into how grammatical features manifest in contextual embedding spaces, at a level of abstraction not covered by previous work.
Align-Refine: Non-Autoregressive Speech Recognition via Iterative Realignment
Oct 24, 2020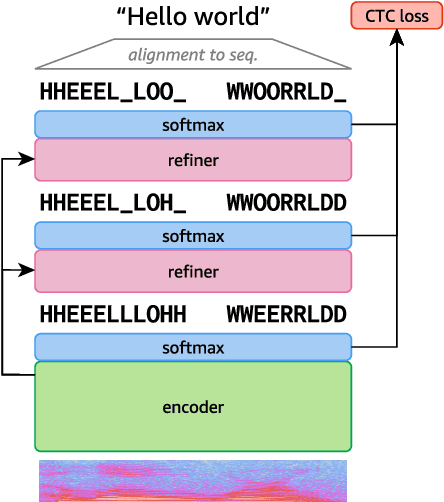
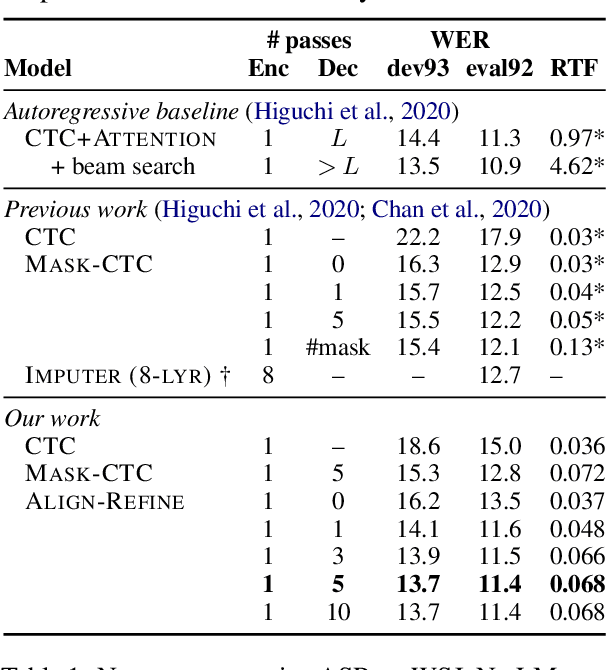
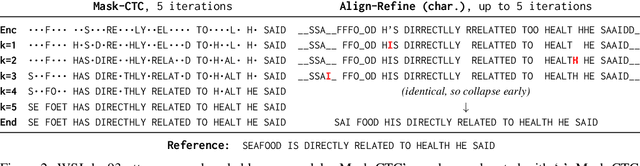
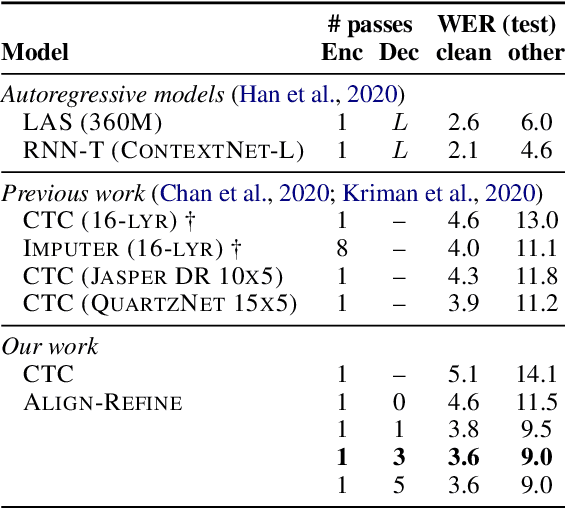
Non-autoregressive models greatly improve decoding speed over typical sequence-to-sequence models, but suffer from degraded performance. Infilling and iterative refinement models make up some of this gap by editing the outputs of a non-autoregressive model, but are constrained in the edits that they can make. We propose iterative realignment, where refinements occur over latent alignments rather than output sequence space. We demonstrate this in speech recognition with Align-Refine, an end-to-end Transformer-based model which refines connectionist temporal classification (CTC) alignments to allow length-changing insertions and deletions. Align-Refine outperforms Imputer and Mask-CTC, matching an autoregressive baseline on WSJ at 1/14th the real-time factor and attaining a LibriSpeech test-other WER of 9.0% without an LM. Our model is strong even in one iteration with a shallower decoder.
Finding Universal Grammatical Relations in Multilingual BERT
May 20, 2020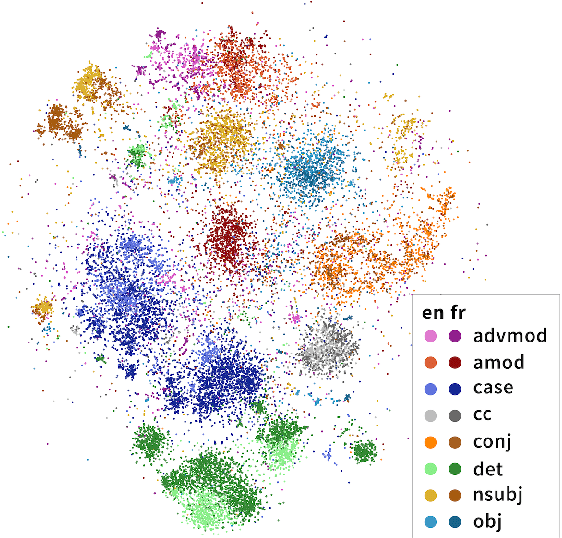
Recent work has found evidence that Multilingual BERT (mBERT), a transformer-based multilingual masked language model, is capable of zero-shot cross-lingual transfer, suggesting that some aspects of its representations are shared cross-lingually. To better understand this overlap, we extend recent work on finding syntactic trees in neural networks' internal representations to the multilingual setting. We show that subspaces of mBERT representations recover syntactic tree distances in languages other than English, and that these subspaces are approximately shared across languages. Motivated by these results, we present an unsupervised analysis method that provides evidence mBERT learns representations of syntactic dependency labels, in the form of clusters which largely agree with the Universal Dependencies taxonomy. This evidence suggests that even without explicit supervision, multilingual masked language models learn certain linguistic universals.
SGVAE: Sequential Graph Variational Autoencoder
Dec 17, 2019

Generative models of graphs are well-known, but many existing models are limited in scalability and expressivity. We present a novel sequential graphical variational autoencoder operating directly on graphical representations of data. In our model, the encoding and decoding of a graph as is framed as a sequential deconstruction and construction process, respectively, enabling the the learning of a latent space. Experiments on a cycle dataset show promise, but highlight the need for a relaxation of the distribution over node permutations.