 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinking Out of Order: When Output Order Stops Reflecting Reasoning Order in Diffusion Language Models
Jan 29, 2026Autoregressive (AR) language models enforce a fixed left-to-right generation order, creating a fundamental limitation when the required output structure conflicts with natural reasoning (e.g., producing answers before explanations due to presentation or schema constraints). In such cases, AR models must commit to answers before generating intermediate reasoning, and this rigid constraint forces premature commitment. Masked diffusion language models (MDLMs), which iteratively refine all tokens in parallel, offer a way to decouple computation order from output structure. We validate this capability on GSM8K, Math500, and ReasonOrderQA, a benchmark we introduce with controlled difficulty and order-level evaluation. When prompts request answers before reasoning, AR models exhibit large accuracy gaps compared to standard chain-of-thought ordering (up to 67% relative drop), while MDLMs remain stable ($\leq$14% relative drop), a property we term "order robustness". Using ReasonOrderQA, we present evidence that MDLMs achieve order robustness by stabilizing simpler tokens (e.g., reasoning steps) earlier in the diffusion process than complex ones (e.g., final answers), enabling reasoning tokens to stabilize before answer commitment. Finally, we identify failure conditions where this advantage weakens, outlining the limits required for order robustness.
U2NeRF: Unsupervised Underwater Image Restoration and Neural Radiance Fields
Nov 25, 2024Underwater images suffer from colour shifts, low contrast, and haziness due to light absorption, refraction, scattering and restoring these images has warranted much attention. In this work, we present Unsupervised Underwater Neural Radiance Field U2NeRF, a transformer-based architecture that learns to render and restore novel views conditioned on multi-view geometry simultaneously. Due to the absence of supervision, we attempt to implicitly bake restoring capabilities onto the NeRF pipeline and disentangle the predicted color into several components - scene radiance, direct transmission map, backscatter transmission map, and global background light, and when combined reconstruct the underwater image in a self-supervised manner. In addition, we release an Underwater View Synthesis UVS dataset consisting of 12 underwater scenes, containing both synthetically-generated and real-world data. Our experiments demonstrate that when optimized on a single scene, U2NeRF outperforms several baselines by as much LPIPS 11%, UIQM 5%, UCIQE 4% (on average) and showcases improved rendering and restoration capabilities. Code will be made available upon acceptance.
GAURA: Generalizable Approach for Unified Restoration and Rendering of Arbitrary Views
Jul 11, 2024Neural rendering methods can achieve near-photorealistic image synthesis of scenes from posed input images. However, when the images are imperfect, e.g., captured in very low-light conditions, state-of-the-art methods fail to reconstruct high-quality 3D scenes. Recent approaches have tried to address this limitation by modeling various degradation processes in the image formation model; however, this limits them to specific image degradations. In this paper, we propose a generalizable neural rendering method that can perform high-fidelity novel view synthesis under several degradations. Our method, GAURA, is learning-based and does not require any test-time scene-specific optimization. It is trained on a synthetic dataset that includes several degradation types. GAURA outperforms state-of-the-art methods on several benchmarks for low-light enhancement, dehazing, deraining, and on-par for motion deblurring. Further, our model can be efficiently fine-tuned to any new incoming degradation using minimal data. We thus demonstrate adaptation results on two unseen degradations, desnowing and removing defocus blur. Code and video results are available at vinayak-vg.github.io/GAURA.
A Construct-Optimize Approach to Sparse View Synthesis without Camera Pose
May 06, 2024Novel view synthesis from a sparse set of input images is a challenging problem of great practical interest, especially when camera poses are absent or inaccurate. Direct optimization of camera poses and usage of estimated depths in neural radiance field algorithms usually do not produce good results because of the coupling between poses and depths, and inaccuracies in monocular depth estimation. In this paper, we leverage the recent 3D Gaussian splatting method to develop a novel construct-and-optimize method for sparse view synthesis without camera poses. Specifically, we construct a solution progressively by using monocular depth and projecting pixels back into the 3D world. During construction, we optimize the solution by detecting 2D correspondences between training views and the corresponding rendered images. We develop a unified differentiable pipeline for camera registration and adjustment of both camera poses and depths, followed by back-projection. We also introduce a novel notion of an expected surface in Gaussian splatting, which is critical to our optimization. These steps enable a coarse solution, which can then be low-pass filtered and refined using standard optimization methods. We demonstrate results on the Tanks and Temples and Static Hikes datasets with as few as three widely-spaced views, showing significantly better quality than competing methods, including those with approximate camera pose information. Moreover, our results improve with more views and outperform previous InstantNGP and Gaussian Splatting algorithms even when using half the dataset.
Lift3D: Zero-Shot Lifting of Any 2D Vision Model to 3D
Mar 27, 2024In recent years, there has been an explosion of 2D vision models for numerous tasks such as semantic segmentation, style transfer or scene editing, enabled by large-scale 2D image datasets. At the same time, there has been renewed interest in 3D scene representations such as neural radiance fields from multi-view images. However, the availability of 3D or multiview data is still substantially limited compared to 2D image datasets, making extending 2D vision models to 3D data highly desirable but also very challenging. Indeed, extending a single 2D vision operator like scene editing to 3D typically requires a highly creative method specialized to that task and often requires per-scene optimization. In this paper, we ask the question of whether any 2D vision model can be lifted to make 3D consistent predictions. We answer this question in the affirmative; our new Lift3D method trains to predict unseen views on feature spaces generated by a few visual models (i.e. DINO and CLIP), but then generalizes to novel vision operators and tasks, such as style transfer, super-resolution, open vocabulary segmentation and image colorization; for some of these tasks, there is no comparable previous 3D method. In many cases, we even outperform state-of-the-art methods specialized for the task in question. Moreover, Lift3D is a zero-shot method, in the sense that it requires no task-specific training, nor scene-specific optimization.
One-2-3-45: Any Single Image to 3D Mesh in 45 Seconds without Per-Shape Optimization
Jun 29, 2023



Single image 3D reconstruction is an important but challenging task that requires extensive knowledge of our natural world. Many existing methods solve this problem by optimizing a neural radiance field under the guidance of 2D diffusion models but suffer from lengthy optimization time, 3D inconsistency results, and poor geometry. In this work, we propose a novel method that takes a single image of any object as input and generates a full 360-degree 3D textured mesh in a single feed-forward pass. Given a single image, we first use a view-conditioned 2D diffusion model, Zero123, to generate multi-view images for the input view, and then aim to lift them up to 3D space. Since traditional reconstruction methods struggle with inconsistent multi-view predictions, we build our 3D reconstruction module upon an SDF-based generalizable neural surface reconstruction method and propose several critical training strategies to enable the reconstruction of 360-degree meshes. Without costly optimizations, our method reconstructs 3D shapes in significantly less time than existing methods. Moreover, our method favors better geometry, generates more 3D consistent results, and adheres more closely to the input image. We evaluate our approach on both synthetic data and in-the-wild images and demonstrate its superiority in terms of both mesh quality and runtime. In addition, our approach can seamlessly support the text-to-3D task by integrating with off-the-shelf text-to-image diffusion models.
Is Attention All NeRF Needs?
Jul 27, 2022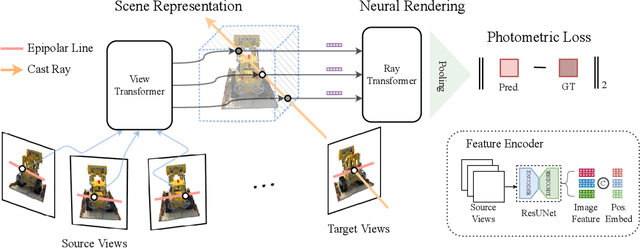
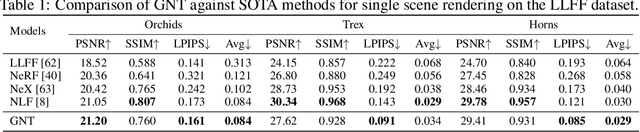
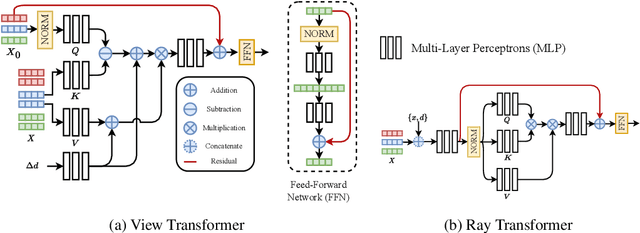
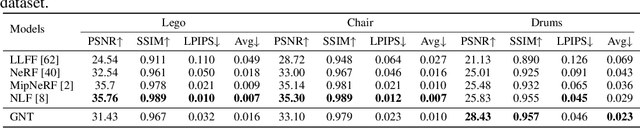
We present Generalizable NeRF Transformer (GNT), a pure, unified transformer-based architecture that efficiently reconstructs Neural Radiance Fields (NeRFs) on the fly from source views. Unlike prior works on NeRF that optimize a per-scene implicit representation by inverting a handcrafted rendering equation, GNT achieves generalizable neural scene representation and rendering, by encapsulating two transformer-based stages. The first stage of GNT, called view transformer, leverages multi-view geometry as an inductive bias for attention-based scene representation, and predicts coordinate-aligned features by aggregating information from epipolar lines on the neighboring views. The second stage of GNT, named ray transformer, renders novel views by ray marching and directly decodes the sequence of sampled point features using the attention mechanism. Our experiments demonstrate that when optimized on a single scene, GNT can successfully reconstruct NeRF without explicit rendering formula, and even improve the PSNR by ~1.3dB on complex scenes due to the learnable ray renderer. When trained across various scenes, GNT consistently achieves the state-of-the-art performance when transferring to forward-facing LLFF dataset (LPIPS ~20%, SSIM ~25%$) and synthetic blender dataset (LPIPS ~20%, SSIM ~4%). In addition, we show that depth and occlusion can be inferred from the learned attention maps, which implies that the pure attention mechanism is capable of learning a physically-grounded rendering process. All these results bring us one step closer to the tantalizing hope of utilizing transformers as the "universal modeling tool" even for graphics. Please refer to our project page for video results: https://vita-group.github.io/GNT/.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
NL-Augmenter: A Framework for Task-Sensitive Natural Language Augmentation
Dec 06, 2021



Data augmentation is an important component in the robustness evaluation of models in natural language processing (NLP) and in enhancing the diversity of the data they are trained on. In this paper, we present NL-Augmenter, a new participatory Python-based natural language augmentation framework which supports the creation of both transformations (modifications to the data) and filters (data splits according to specific features). We describe the framework and an initial set of 117 transformations and 23 filters for a variety of natural language tasks. We demonstrate the efficacy of NL-Augmenter by using several of its transformations to analyze the robustness of popular natural language models. The infrastructure, datacards and robustness analysis results are available publicly on the NL-Augmenter repository (\url{https://github.com/GEM-benchmark/NL-Augmenter}).
PointTransformer for Shape Classification and Retrieval of 3D and ALS Roof PointClouds
Nov 08, 2020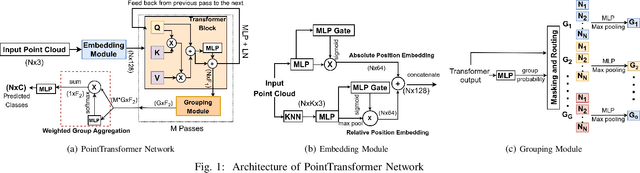

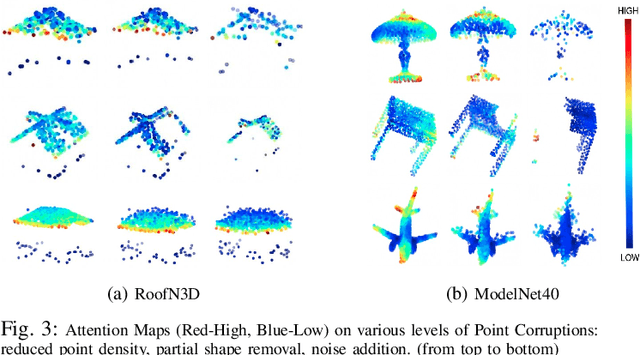
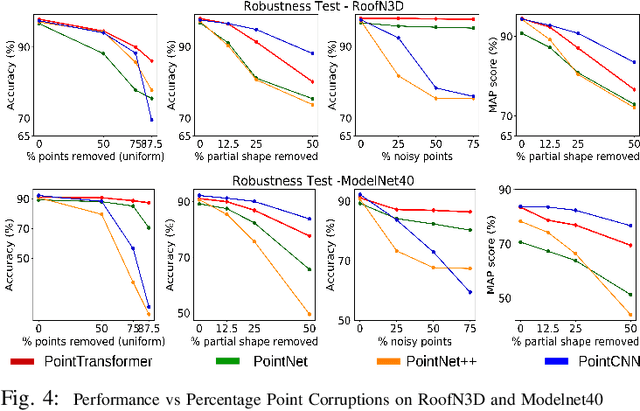
Effective feature representation from Airborne Laser Scanning (ALS) point clouds used for urban modeling was challenging until the advent of deep learning and improved ALS techniques. Most deep learning techniques for 3-D point clouds utilize convolutions that assume a uniform input distribution and cannot learn long-range dependencies, leading to some limitations. Recent works have already shown that adding attention on top of these methods improves performance. This raises a question: can attention layers completely replace convolutions? We propose a fully attentional model-PointTransformer for deriving a rich point cloud representation. The model's shape classification and retrieval performance are evaluated on a large-scale urban dataset - RoofN3D and a standard benchmark dataset ModelNet40. Also, the model is tested on various simulated point corruptions to analyze its effectiveness on real datasets. The proposed method outperforms other state-of-the-art models in the RoofN3D dataset, gives competitive results in the ModelNet40 benchmark, and showcases high robustness to multiple point corruptions. Furthermore, the model is both memory and space-efficient without compromising on performance.