 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpirical Computation
Mar 13, 2025
In this vision paper, we explore the challenges and opportunities of a form of computation that employs an empirical (rather than a formal) approach, where the solution of a computational problem is returned as empirically most likely (rather than necessarily correct). We call this approach as *empirical computation* and observe that its capabilities and limits *cannot* be understood within the classic, rationalist framework of computation. While we take a very broad view of "computational problem", a classic, well-studied example is *sorting*: Given a set of $n$ numbers, return these numbers sorted in ascending order. * To run a classical, *formal computation*, we might first think about a *specific algorithm* (e.g., merge sort) before developing a *specific* program that implements it. The program will expect the input to be given in a *specific* format, type, or data structure (e.g., unsigned 32-bit integers). In software engineering, we have many approaches to analyze the correctness of such programs. From complexity theory, we know that there exists no correct program that can solve the average instance of the sorting problem faster than $O(n\log n)$. * To run an *empirical computation*, we might directly ask a large language model (LLM) to solve *any* computational problem (which can be stated informally in natural language) and provide the input in *any* format (e.g., negative numbers written as Chinese characters). There is no (problem-specific) program that could be analyzed for correctness. Also, the time it takes an LLM to return an answer is entirely *independent* of the computational complexity of the problem that is solved. What are the capabilities or limits of empirical computation in the general, in the problem-, or in the instance-specific? Our purpose is to establish empirical computation as a field in SE that is timely and rich with interesting problems.
Streaming Detection of Queried Event Start
Dec 04, 2024



Robotics, autonomous driving, augmented reality, and many embodied computer vision applications must quickly react to user-defined events unfolding in real time. We address this setting by proposing a novel task for multimodal video understanding-Streaming Detection of Queried Event Start (SDQES). The goal of SDQES is to identify the beginning of a complex event as described by a natural language query, with high accuracy and low latency. We introduce a new benchmark based on the Ego4D dataset, as well as new task-specific metrics to study streaming multimodal detection of diverse events in an egocentric video setting. Inspired by parameter-efficient fine-tuning methods in NLP and for video tasks, we propose adapter-based baselines that enable image-to-video transfer learning, allowing for efficient online video modeling. We evaluate three vision-language backbones and three adapter architectures on both short-clip and untrimmed video settings.
Understanding LLM Embeddings for Regression
Nov 22, 2024



With the rise of large language models (LLMs) for flexibly processing information as strings, a natural application is regression, specifically by preprocessing string representations into LLM embeddings as downstream features for metric prediction. In this paper, we provide one of the first comprehensive investigations into embedding-based regression and demonstrate that LLM embeddings as features can be better for high-dimensional regression tasks than using traditional feature engineering. This regression performance can be explained in part due to LLM embeddings over numeric data inherently preserving Lipschitz continuity over the feature space. Furthermore, we quantify the contribution of different model effects, most notably model size and language understanding, which we find surprisingly do not always improve regression performance.
How Would The Viewer Feel? Estimating Wellbeing From Video Scenarios
Oct 18, 2022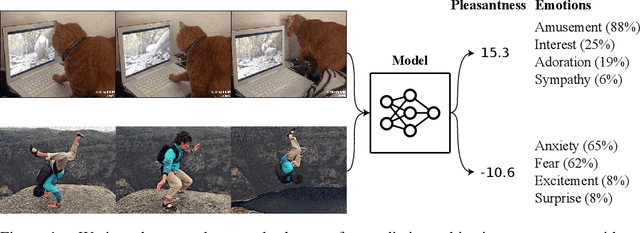
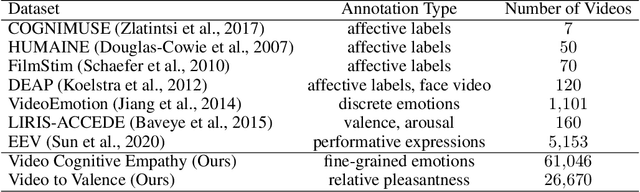


In recent years, deep neural networks have demonstrated increasingly strong abilities to recognize objects and activities in videos. However, as video understanding becomes widely used in real-world applications, a key consideration is developing human-centric systems that understand not only the content of the video but also how it would affect the wellbeing and emotional state of viewers. To facilitate research in this setting, we introduce two large-scale datasets with over 60,000 videos manually annotated for emotional response and subjective wellbeing. The Video Cognitive Empathy (VCE) dataset contains annotations for distributions of fine-grained emotional responses, allowing models to gain a detailed understanding of affective states. The Video to Valence (V2V) dataset contains annotations of relative pleasantness between videos, which enables predicting a continuous spectrum of wellbeing. In experiments, we show how video models that are primarily trained to recognize actions and find contours of objects can be repurposed to understand human preferences and the emotional content of videos. Although there is room for improvement, predicting wellbeing and emotional response is on the horizon for state-of-the-art models. We hope our datasets can help foster further advances at the intersection of commonsense video understanding and human preference learning.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Validation of image systems simulation technology using a Cornell Box
May 10, 2021
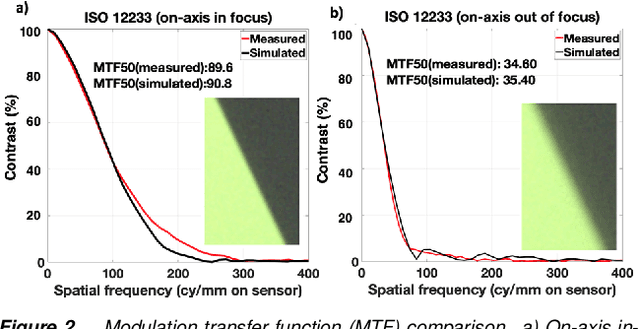
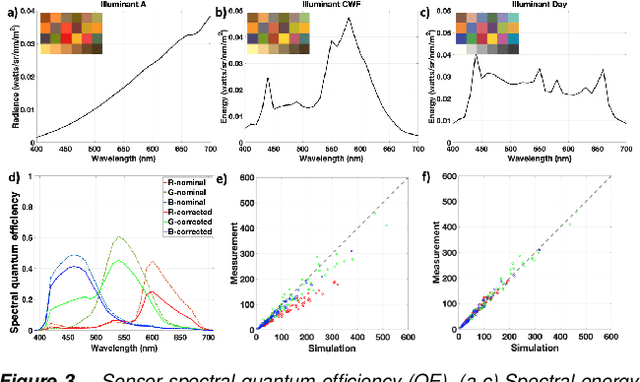

We describe and experimentally validate an end-to-end simulation of a digital camera. The simulation models the spectral radiance of 3D-scenes, formation of the spectral irradiance by multi-element optics, and conversion of the irradiance to digital values by the image sensor. We quantify the accuracy of the simulation by comparing real and simulated images of a precisely constructed, three-dimensional high dynamic range test scene. Validated end-to-end software simulation of a digital camera can accelerate innovation by reducing many of the time-consuming and expensive steps in designing, building and evaluating image systems.
Measuring Mathematical Problem Solving With the MATH Dataset
Mar 05, 2021
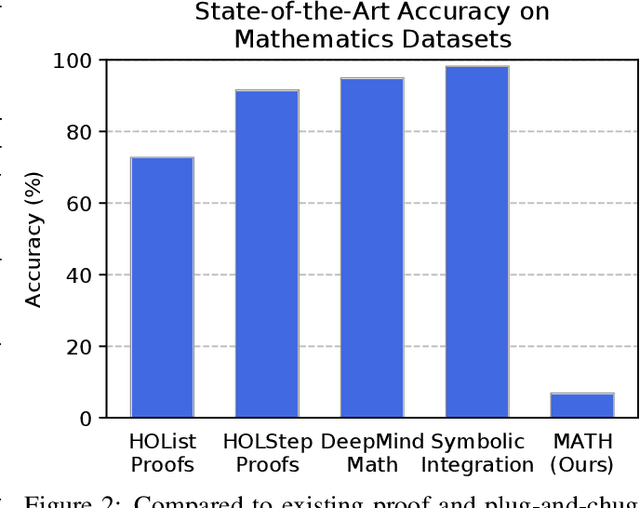
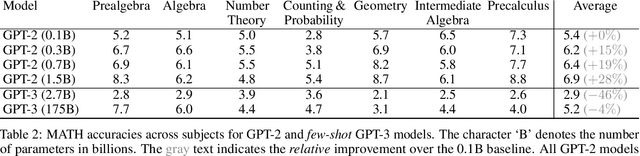
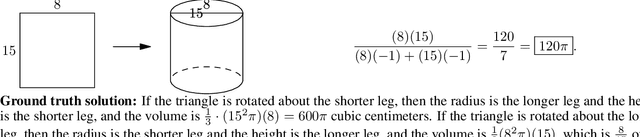
Many intellectual endeavors require mathematical problem solving, but this skill remains beyond the capabilities of computers. To measure this ability in machine learning models, we introduce MATH, a new dataset of 12,500 challenging competition mathematics problems. Each problem in MATH has a full step-by-step solution which can be used to teach models to generate answer derivations and explanations. To facilitate future research and increase accuracy on MATH, we also contribute a large auxiliary pretraining dataset which helps teach models the fundamentals of mathematics. Even though we are able to increase accuracy on MATH, our results show that accuracy remains relatively low, even with enormous Transformer models. Moreover, we find that simply increasing budgets and model parameter counts will be impractical for achieving strong mathematical reasoning if scaling trends continue. While scaling Transformers is automatically solving most other text-based tasks, scaling is not currently solving MATH. To have more traction on mathematical problem solving we will likely need new algorithmic advancements from the broader research community.