 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDECK: Behavioral Tests to Improve Interpretability and Generalizability of BERT Models Detecting Depression from Text
Sep 12, 2022
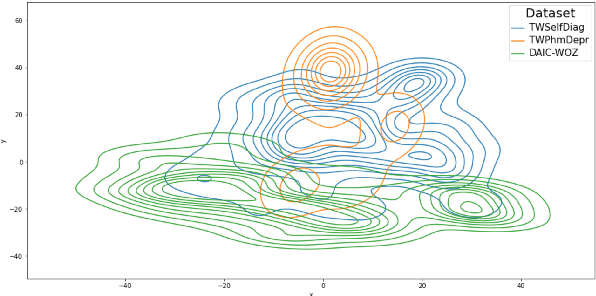
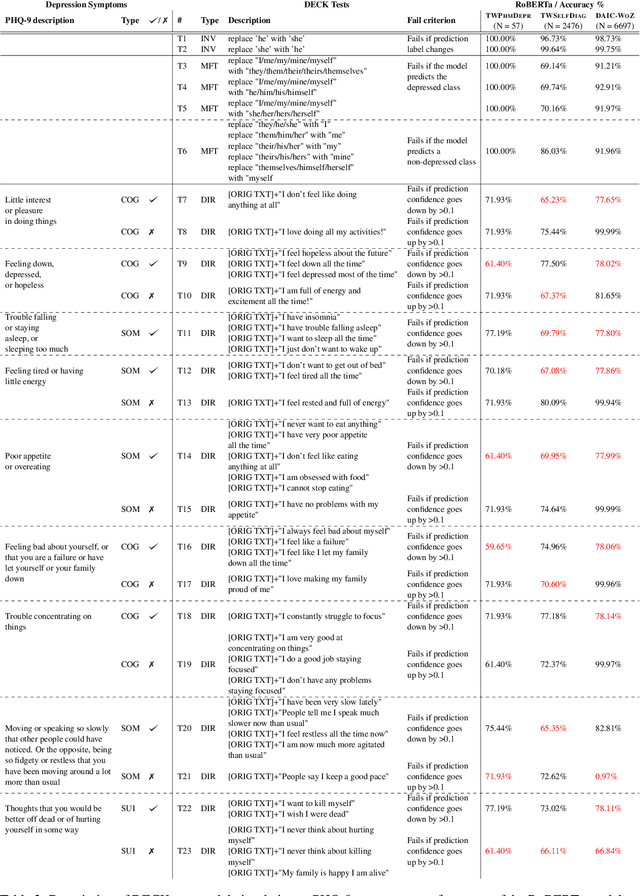
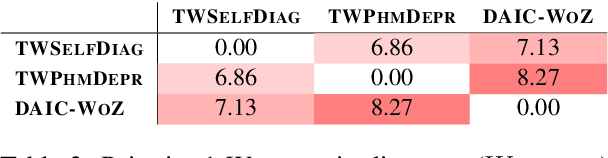
Models that accurately detect depression from text are important tools for addressing the post-pandemic mental health crisis. BERT-based classifiers' promising performance and the off-the-shelf availability make them great candidates for this task. However, these models are known to suffer from performance inconsistencies and poor generalization. In this paper, we introduce the DECK (DEpression ChecKlist), depression-specific model behavioural tests that allow better interpretability and improve generalizability of BERT classifiers in depression domain. We create 23 tests to evaluate BERT, RoBERTa and ALBERT depression classifiers on three datasets, two Twitter-based and one clinical interview-based. Our evaluation shows that these models: 1) are robust to certain gender-sensitive variations in text; 2) rely on the important depressive language marker of the increased use of first person pronouns; 3) fail to detect some other depression symptoms like suicidal ideation. We also demonstrate that DECK tests can be used to incorporate symptom-specific information in the training data and consistently improve generalizability of all three BERT models, with an out-of-distribution F1-score increase of up to 53.93%.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Lexical Features Are More Vulnerable, Syntactic Features Have More Predictive Power
Sep 30, 2019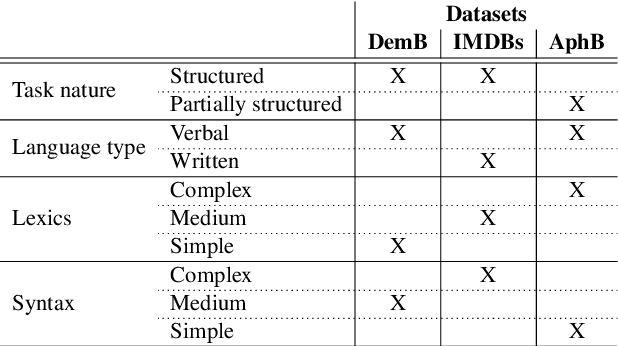
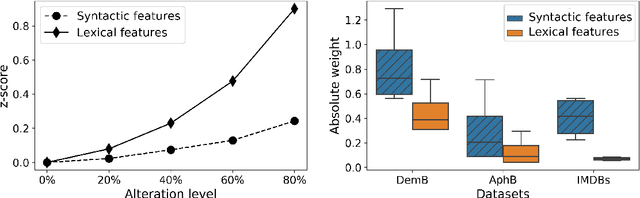
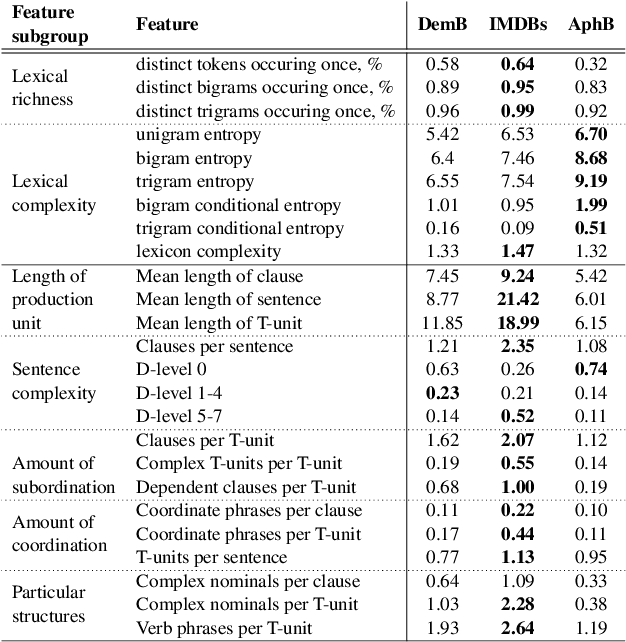
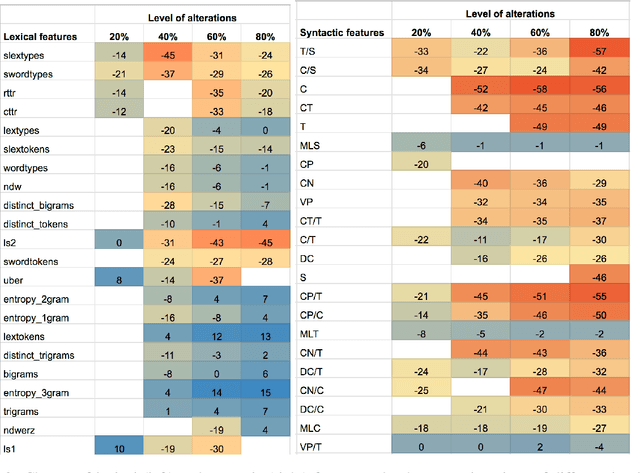
Understanding the vulnerability of linguistic features extracted from noisy text is important for both developing better health text classification models and for interpreting vulnerabilities of natural language models. In this paper, we investigate how generic language characteristics, such as syntax or the lexicon, are impacted by artificial text alterations. The vulnerability of features is analysed from two perspectives: (1) the level of feature value change, and (2) the level of change of feature predictive power as a result of text modifications. We show that lexical features are more sensitive to text modifications than syntactic ones. However, we also demonstrate that these smaller changes of syntactic features have a stronger influence on classification performance downstream, compared to the impact of changes to lexical features. Results are validated across three datasets representing different text-classification tasks, with different levels of lexical and syntactic complexity of both conversational and written language.
Impact of ASR on Alzheimer's Disease Detection: All Errors are Equal, but Deletions are More Equal than Others
Apr 08, 2019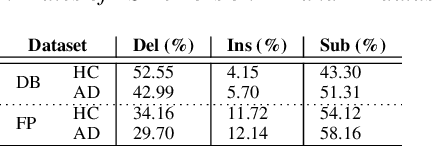
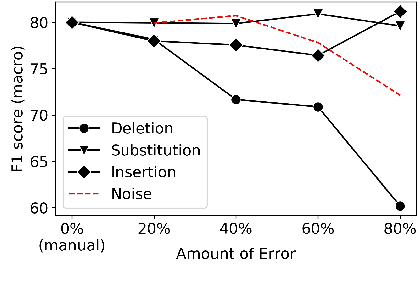
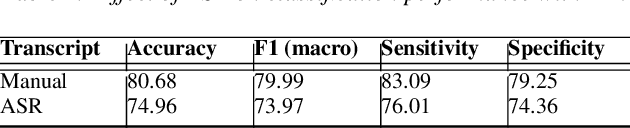
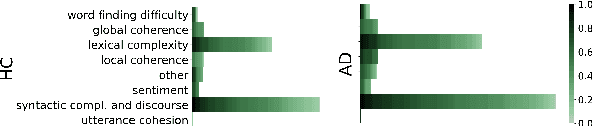
Automatic Speech Recognition (ASR) is a critical component of any fully-automated speech-based Alzheimer's disease (AD) detection model. However, despite years of speech recognition research, little is known about the impact of ASR performance on AD detection. In this paper, we experiment with controlled amounts of artificially generated ASR errors and investigate their influence on AD detection. We find that deletion errors affect AD detection performance the most, due to their impact on the features of syntactic complexity and discourse representation in speech. We show the trend to be generalisable across two different datasets and two different speech-related tasks. As a conclusion, we propose changing the ASR optimization functions to reflect a higher penalty for deletion errors when using ASR for AD detection.