 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenThoughts-Agent: Data Recipes for Agentic Models
Jun 23, 2026Agentic language models dramatically expand the applications of AI yet little is publicly known about how to curate training data for broadly capable agents. Existing open efforts such as SWE-Smith, SERA, and Nemotron-Terminal typically target a single benchmark, leaving open the question of how to train models that generalize across diverse agentic tasks. The OpenThoughts-Agent (OT-Agent) project addresses this gap with a fully open data curation pipeline for training agentic models. We conduct more than 100 controlled ablation experiments to systematically investigate each stage of the pipeline, yielding insights on the importance of task sources and diversity. We then assemble a training set of 100K examples from our pipeline and fine-tune Qwen3-32B on this dataset, which yields an average accuracy of 44.8% across seven agentic benchmarks and a 3.9 percentage point improvement over the strongest existing open data agentic model (Nemotron-Terminal-32B, 40.9%). Moreover, our training data exhibits strong scaling properties, outperforming alternative open datasets at every training set size in compute-controlled comparisons. We publicly release our training sets, data pipeline, experimental data, and models at openthoughts.ai to support future open research on agentic model training.
Test-Time Scaling Makes Overtraining Compute-Optimal
Apr 01, 2026Modern LLMs scale at test-time, e.g. via repeated sampling, where inference cost grows with model size and the number of samples. This creates a trade-off that pretraining scaling laws, such as Chinchilla, do not address. We present Train-to-Test ($T^2$) scaling laws that jointly optimize model size, training tokens, and number of inference samples under fixed end-to-end budgets. $T^2$ modernizes pretraining scaling laws with pass@$k$ modeling used for test-time scaling, then jointly optimizes pretraining and test-time decisions. Forecasts from $T^2$ are robust over distinct modeling approaches: measuring joint scaling effect on the task loss and modeling impact on task accuracy. Across eight downstream tasks, we find that when accounting for inference cost, optimal pretraining decisions shift radically into the overtraining regime, well-outside of the range of standard pretraining scaling suites. We validate our results by pretraining heavily overtrained models in the optimal region that $T^2$ scaling forecasts, confirming their substantially stronger performance compared to pretraining scaling alone. Finally, as frontier LLMs are post-trained, we show that our findings survive the post-training stage, making $T^2$ scaling meaningful in modern deployments.
Procedural Generation of Algorithm Discovery Tasks in Machine Learning
Mar 18, 2026Automating the development of machine learning algorithms has the potential to unlock new breakthroughs. However, our ability to improve and evaluate algorithm discovery systems has thus far been limited by existing task suites. They suffer from many issues, such as: poor evaluation methodologies; data contamination; and containing saturated or very similar problems. Here, we introduce DiscoGen, a procedural generator of algorithm discovery tasks for machine learning, such as developing optimisers for reinforcement learning or loss functions for image classification. Motivated by the success of procedural generation in reinforcement learning, DiscoGen spans millions of tasks of varying difficulty and complexity from a range of machine learning fields. These tasks are specified by a small number of configuration parameters and can be used to optimise algorithm discovery agents (ADAs). We present DiscoBench, a benchmark consisting of a fixed, small subset of DiscoGen tasks for principled evaluation of ADAs. Finally, we propose a number of ambitious, impactful research directions enabled by DiscoGen, in addition to experiments demonstrating its use for prompt optimisation of an ADA. DiscoGen is released open-source at https://github.com/AlexGoldie/discogen.
R&B: Domain Regrouping and Data Mixture Balancing for Efficient Foundation Model Training
May 01, 2025



Data mixing strategies have successfully reduced the costs involved in training language models. While promising, such methods suffer from two flaws. First, they rely on predetermined data domains (e.g., data sources, task types), which may fail to capture critical semantic nuances, leaving performance on the table. Second, these methods scale with the number of domains in a computationally prohibitive way. We address these challenges via R&B, a framework that re-partitions training data based on semantic similarity (Regroup) to create finer-grained domains, and efficiently optimizes the data composition (Balance) by leveraging a Gram matrix induced by domain gradients obtained throughout training. Unlike prior works, it removes the need for additional compute to obtain evaluation information such as losses or gradients. We analyze this technique under standard regularity conditions and provide theoretical insights that justify R&B's effectiveness compared to non-adaptive mixing approaches. Empirically, we demonstrate the effectiveness of R&B on five diverse datasets ranging from natural language to reasoning and multimodal tasks. With as little as 0.01% additional compute overhead, R&B matches or exceeds the performance of state-of-the-art data mixing strategies.
Compute Optimal Scaling of Skills: Knowledge vs Reasoning
Mar 13, 2025Scaling laws are a critical component of the LLM development pipeline, most famously as a way to forecast training decisions such as 'compute-optimally' trading-off parameter count and dataset size, alongside a more recent growing list of other crucial decisions. In this work, we ask whether compute-optimal scaling behaviour can be skill-dependent. In particular, we examine knowledge and reasoning-based skills such as knowledge-based QA and code generation, and we answer this question in the affirmative: $\textbf{scaling laws are skill-dependent}$. Next, to understand whether skill-dependent scaling is an artefact of the pretraining datamix, we conduct an extensive ablation of different datamixes and find that, also when correcting for datamix differences, $\textbf{knowledge and code exhibit fundamental differences in scaling behaviour}$. We conclude with an analysis of how our findings relate to standard compute-optimal scaling using a validation set, and find that $\textbf{a misspecified validation set can impact compute-optimal parameter count by nearly 50%,}$ depending on its skill composition.
Tabby: Tabular Data Synthesis with Language Models
Mar 04, 2025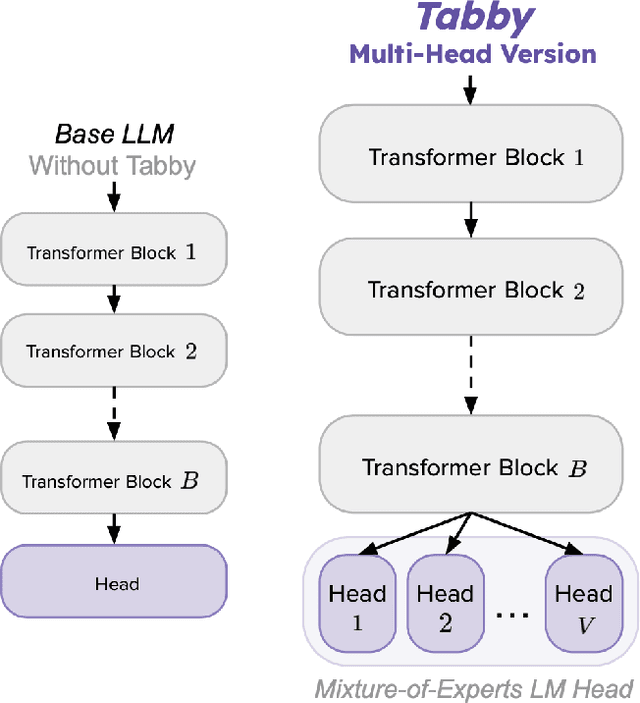
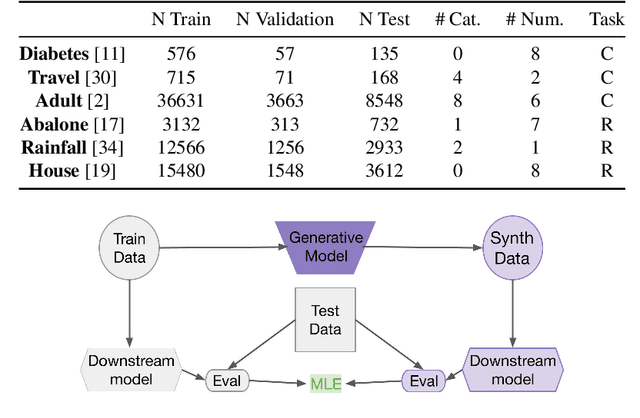
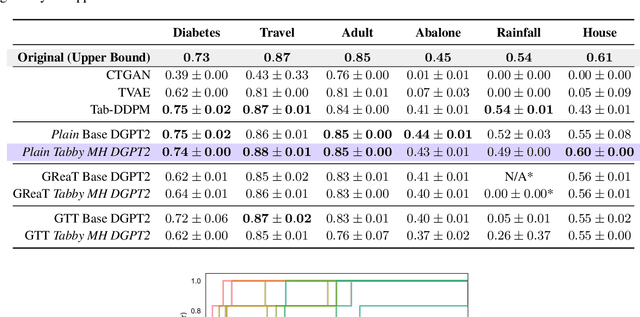
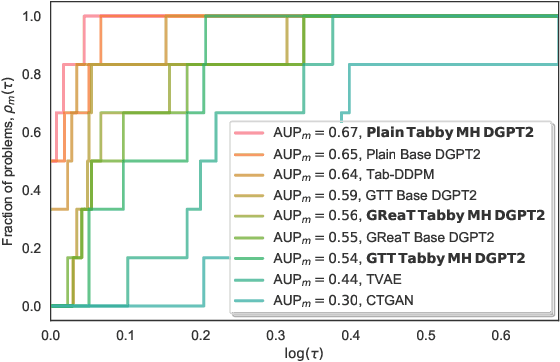
While advances in large language models (LLMs) have greatly improved the quality of synthetic text data in recent years, synthesizing tabular data has received relatively less attention. We address this disparity with Tabby, a simple but powerful post-training modification to the standard Transformer language model architecture, enabling its use for tabular dataset synthesis. Tabby enables the representation of differences across columns using Gated Mixture-of-Experts, with column-specific sets of parameters. Empirically, Tabby results in data quality near or equal to that of real data. By pairing our novel LLM table training technique, Plain, with Tabby, we observe up to a 44% improvement in quality over previous methods. We also show that Tabby extends beyond tables to more general structured data, reaching parity with real data on a nested JSON dataset as well.
MLGym: A New Framework and Benchmark for Advancing AI Research Agents
Feb 20, 2025



We introduce Meta MLGym and MLGym-Bench, a new framework and benchmark for evaluating and developing LLM agents on AI research tasks. This is the first Gym environment for machine learning (ML) tasks, enabling research on reinforcement learning (RL) algorithms for training such agents. MLGym-bench consists of 13 diverse and open-ended AI research tasks from diverse domains such as computer vision, natural language processing, reinforcement learning, and game theory. Solving these tasks requires real-world AI research skills such as generating new ideas and hypotheses, creating and processing data, implementing ML methods, training models, running experiments, analyzing the results, and iterating through this process to improve on a given task. We evaluate a number of frontier large language models (LLMs) on our benchmarks such as Claude-3.5-Sonnet, Llama-3.1 405B, GPT-4o, o1-preview, and Gemini-1.5 Pro. Our MLGym framework makes it easy to add new tasks, integrate and evaluate models or agents, generate synthetic data at scale, as well as develop new learning algorithms for training agents on AI research tasks. We find that current frontier models can improve on the given baselines, usually by finding better hyperparameters, but do not generate novel hypotheses, algorithms, architectures, or substantial improvements. We open-source our framework and benchmark to facilitate future research in advancing the AI research capabilities of LLM agents.
ScriptoriumWS: A Code Generation Assistant for Weak Supervision
Feb 17, 2025Weak supervision is a popular framework for overcoming the labeled data bottleneck: the need to obtain labels for training data. In weak supervision, multiple noisy-but-cheap sources are used to provide guesses of the label and are aggregated to produce high-quality pseudolabels. These sources are often expressed as small programs written by domain experts -- and so are expensive to obtain. Instead, we argue for using code-generation models to act as coding assistants for crafting weak supervision sources. We study prompting strategies to maximize the quality of the generated sources, settling on a multi-tier strategy that incorporates multiple types of information. We explore how to best combine hand-written and generated sources. Using these insights, we introduce ScriptoriumWS, a weak supervision system that, when compared to hand-crafted sources, maintains accuracy and greatly improves coverage.
Stronger Than You Think: Benchmarking Weak Supervision on Realistic Tasks
Jan 13, 2025Weak supervision (WS) is a popular approach for label-efficient learning, leveraging diverse sources of noisy but inexpensive weak labels to automatically annotate training data. Despite its wide usage, WS and its practical value are challenging to benchmark due to the many knobs in its setup, including: data sources, labeling functions (LFs), aggregation techniques (called label models), and end model pipelines. Existing evaluation suites tend to be limited, focusing on particular components or specialized use cases. Moreover, they often involve simplistic benchmark tasks or de-facto LF sets that are suboptimally written, producing insights that may not generalize to real-world settings. We address these limitations by introducing a new benchmark, BOXWRENCH, designed to more accurately reflect real-world usages of WS. This benchmark features tasks with (1) higher class cardinality and imbalance, (2) notable domain expertise requirements, and (3) multilingual variations across parallel corpora. For all tasks, LFs are written using a careful procedure aimed at mimicking real-world settings. In contrast to existing WS benchmarks, we show that supervised learning requires substantial amounts (1000+) of labeled examples to match WS in many settings.
MoRe Fine-Tuning with 10x Fewer Parameters
Aug 30, 2024



Parameter-efficient fine-tuning (PEFT) techniques have unlocked the potential to cheaply and easily specialize large pretrained models. However, the most prominent approaches, like low-rank adapters (LoRA), depend on heuristics or rules-of-thumb for their architectural choices -- potentially limiting their performance for new models and architectures. This limitation suggests that techniques from neural architecture search could be used to obtain optimal adapter architectures, but these are often expensive and difficult to implement. We address this challenge with Monarch Rectangular Fine-tuning (MoRe), a simple framework to search over adapter architectures that relies on the Monarch matrix class. Theoretically, we show that MoRe is more expressive than LoRA. Empirically, our approach is more parameter-efficient and performant than state-of-the-art PEFTs on a range of tasks and models, with as few as 5\% of LoRA's parameters.