 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixture-of-Depths: Dynamically allocating compute in transformer-based language models
Apr 02, 2024



Transformer-based language models spread FLOPs uniformly across input sequences. In this work we demonstrate that transformers can instead learn to dynamically allocate FLOPs (or compute) to specific positions in a sequence, optimising the allocation along the sequence for different layers across the model depth. Our method enforces a total compute budget by capping the number of tokens ($k$) that can participate in the self-attention and MLP computations at a given layer. The tokens to be processed are determined by the network using a top-$k$ routing mechanism. Since $k$ is defined a priori, this simple procedure uses a static computation graph with known tensor sizes, unlike other conditional computation techniques. Nevertheless, since the identities of the $k$ tokens are fluid, this method can expend FLOPs non-uniformly across the time and model depth dimensions. Thus, compute expenditure is entirely predictable in sum total, but dynamic and context-sensitive at the token-level. Not only do models trained in this way learn to dynamically allocate compute, they do so efficiently. These models match baseline performance for equivalent FLOPS and wall-clock times to train, but require a fraction of the FLOPs per forward pass, and can be upwards of 50\% faster to step during post-training sampling.
Improving Multimodal Interactive Agents with Reinforcement Learning from Human Feedback
Nov 21, 2022An important goal in artificial intelligence is to create agents that can both interact naturally with humans and learn from their feedback. Here we demonstrate how to use reinforcement learning from human feedback (RLHF) to improve upon simulated, embodied agents trained to a base level of competency with imitation learning. First, we collected data of humans interacting with agents in a simulated 3D world. We then asked annotators to record moments where they believed that agents either progressed toward or regressed from their human-instructed goal. Using this annotation data we leveraged a novel method - which we call "Inter-temporal Bradley-Terry" (IBT) modelling - to build a reward model that captures human judgments. Agents trained to optimise rewards delivered from IBT reward models improved with respect to all of our metrics, including subsequent human judgment during live interactions with agents. Altogether our results demonstrate how one can successfully leverage human judgments to improve agent behaviour, allowing us to use reinforcement learning in complex, embodied domains without programmatic reward functions. Videos of agent behaviour may be found at https://youtu.be/v_Z9F2_eKk4.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Intra-agent speech permits zero-shot task acquisition
Jun 07, 2022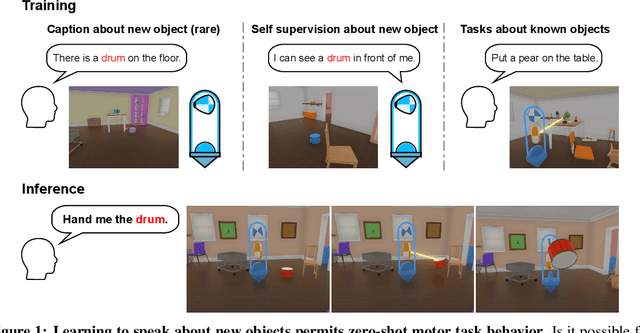
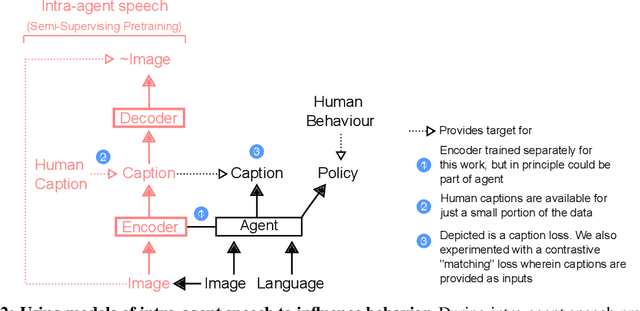

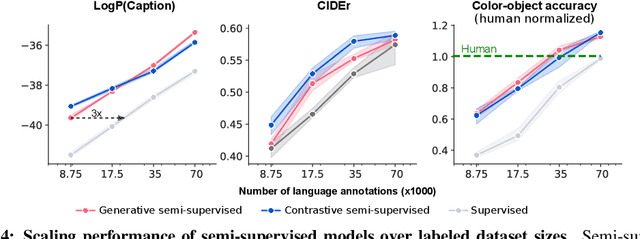
Human language learners are exposed to a trickle of informative, context-sensitive language, but a flood of raw sensory data. Through both social language use and internal processes of rehearsal and practice, language learners are able to build high-level, semantic representations that explain their perceptions. Here, we take inspiration from such processes of "inner speech" in humans (Vygotsky, 1934) to better understand the role of intra-agent speech in embodied behavior. First, we formally pose intra-agent speech as a semi-supervised problem and develop two algorithms that enable visually grounded captioning with little labeled language data. We then experimentally compute scaling curves over different amounts of labeled data and compare the data efficiency against a supervised learning baseline. Finally, we incorporate intra-agent speech into an embodied, mobile manipulator agent operating in a 3D virtual world, and show that with as few as 150 additional image captions, intra-agent speech endows the agent with the ability to manipulate and answer questions about a new object without any related task-directed experience (zero-shot). Taken together, our experiments suggest that modelling intra-agent speech is effective in enabling embodied agents to learn new tasks efficiently and without direct interaction experience.
Evaluating Multimodal Interactive Agents
May 26, 2022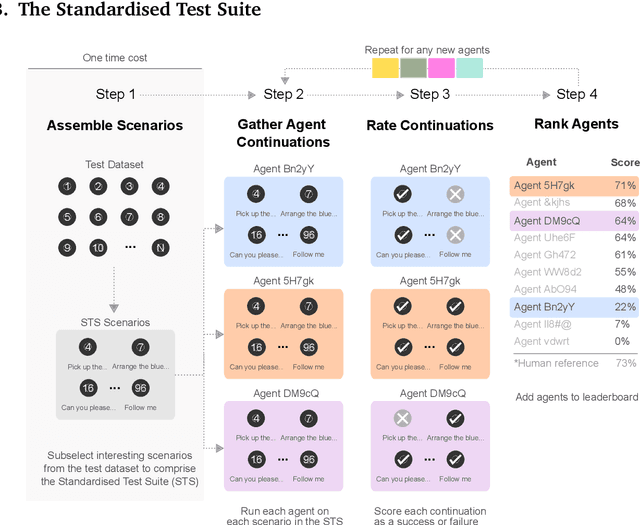
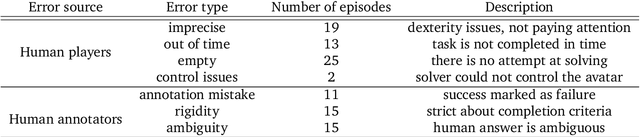
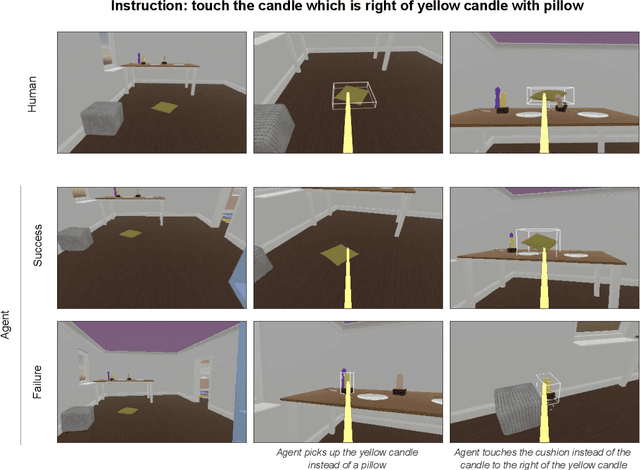
Creating agents that can interact naturally with humans is a common goal in artificial intelligence (AI) research. However, evaluating these interactions is challenging: collecting online human-agent interactions is slow and expensive, yet faster proxy metrics often do not correlate well with interactive evaluation. In this paper, we assess the merits of these existing evaluation metrics and present a novel approach to evaluation called the Standardised Test Suite (STS). The STS uses behavioural scenarios mined from real human interaction data. Agents see replayed scenario context, receive an instruction, and are then given control to complete the interaction offline. These agent continuations are recorded and sent to human annotators to mark as success or failure, and agents are ranked according to the proportion of continuations in which they succeed. The resulting STS is fast, controlled, interpretable, and representative of naturalistic interactions. Altogether, the STS consolidates much of what is desirable across many of our standard evaluation metrics, allowing us to accelerate research progress towards producing agents that can interact naturally with humans. https://youtu.be/YR1TngGORGQ
A data-driven approach for learning to control computers
Feb 16, 2022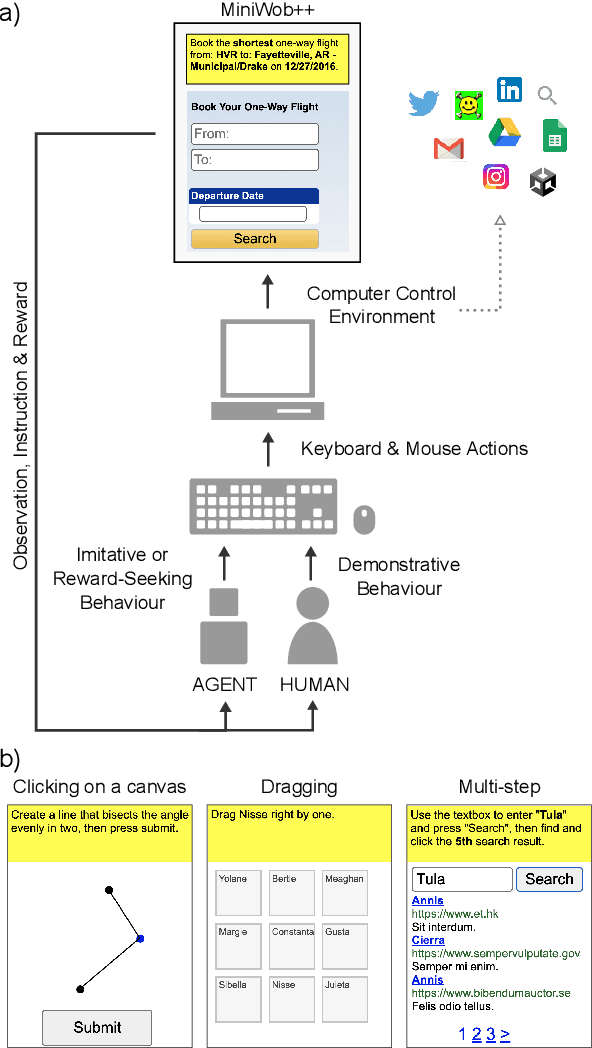
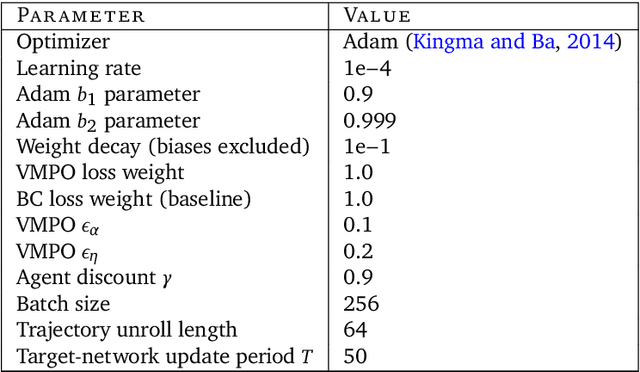
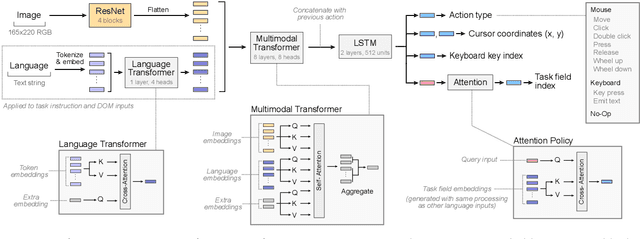
It would be useful for machines to use computers as humans do so that they can aid us in everyday tasks. This is a setting in which there is also the potential to leverage large-scale expert demonstrations and human judgements of interactive behaviour, which are two ingredients that have driven much recent success in AI. Here we investigate the setting of computer control using keyboard and mouse, with goals specified via natural language. Instead of focusing on hand-designed curricula and specialized action spaces, we focus on developing a scalable method centered on reinforcement learning combined with behavioural priors informed by actual human-computer interactions. We achieve state-of-the-art and human-level mean performance across all tasks within the MiniWob++ benchmark, a challenging suite of computer control problems, and find strong evidence of cross-task transfer. These results demonstrate the usefulness of a unified human-agent interface when training machines to use computers. Altogether our results suggest a formula for achieving competency beyond MiniWob++ and towards controlling computers, in general, as a human would.
Tell me why! -- Explanations support learning of relational and causal structure
Dec 08, 2021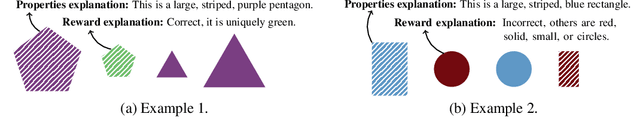
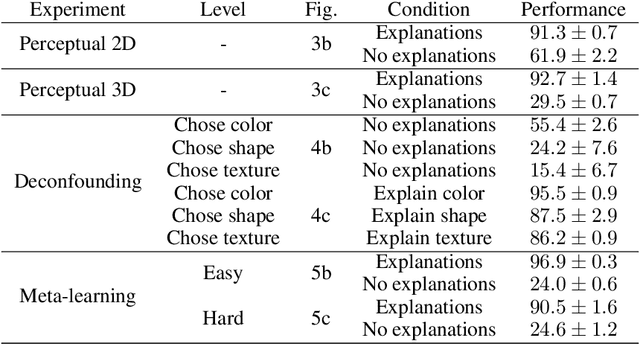
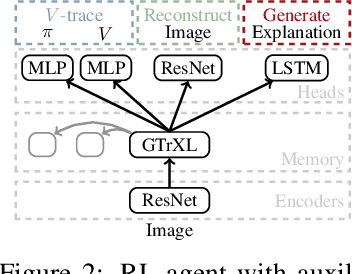
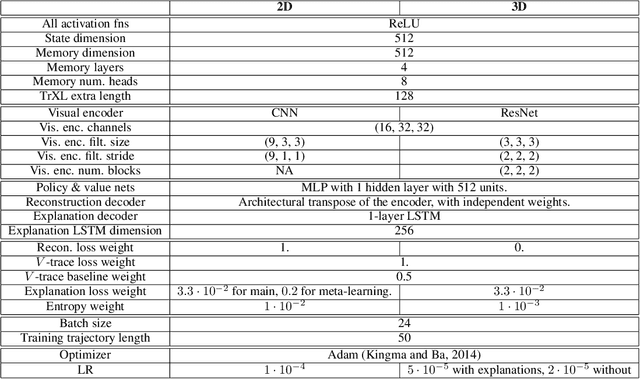
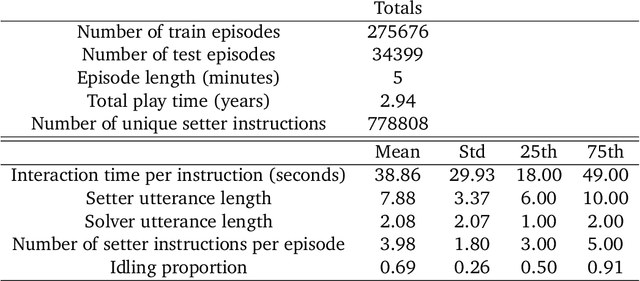
Explanations play a considerable role in human learning, especially in areas that remain major challenges for AI -- forming abstractions, and learning about the relational and causal structure of the world. Here, we explore whether reinforcement learning agents might likewise benefit from explanations. We outline a family of relational tasks that involve selecting an object that is the odd one out in a set (i.e., unique along one of many possible feature dimensions). Odd-one-out tasks require agents to reason over multi-dimensional relationships among a set of objects. We show that agents do not learn these tasks well from reward alone, but achieve >90% performance when they are also trained to generate language explaining object properties or why a choice is correct or incorrect. In further experiments, we show how predicting explanations enables agents to generalize appropriately from ambiguous, causally-confounded training, and even to meta-learn to perform experimental interventions to identify causal structure. We show that explanations help overcome the tendency of agents to fixate on simple features, and explore which aspects of explanations make them most beneficial. Our results suggest that learning from explanations is a powerful principle that could offer a promising path towards training more robust and general machine learning systems.
Creating Multimodal Interactive Agents with Imitation and Self-Supervised Learning
Dec 07, 2021
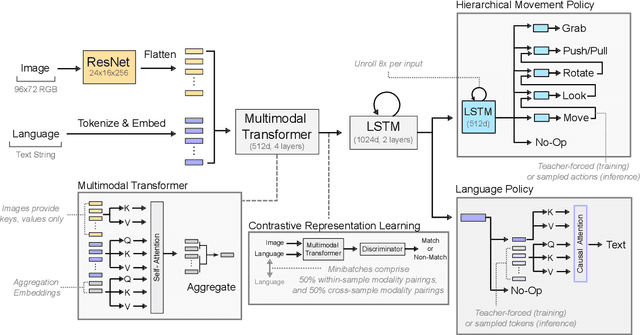
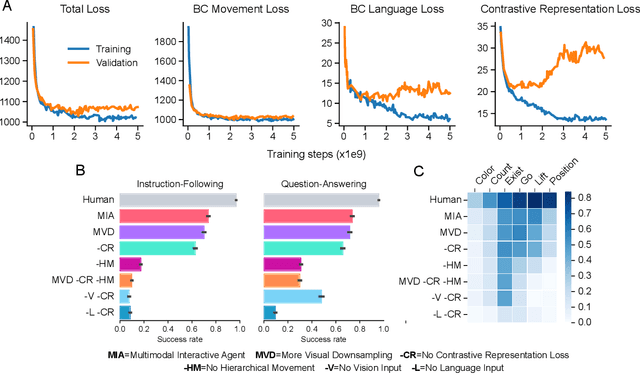
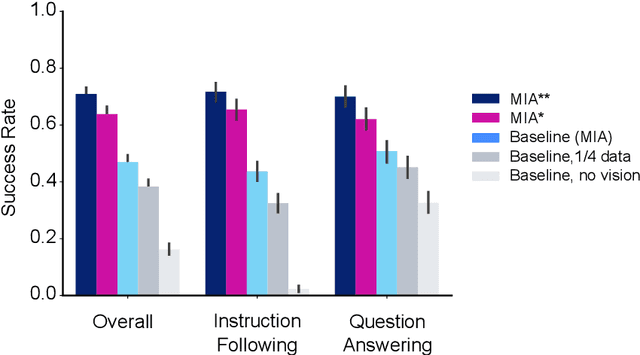
A common vision from science fiction is that robots will one day inhabit our physical spaces, sense the world as we do, assist our physical labours, and communicate with us through natural language. Here we study how to design artificial agents that can interact naturally with humans using the simplification of a virtual environment. We show that imitation learning of human-human interactions in a simulated world, in conjunction with self-supervised learning, is sufficient to produce a multimodal interactive agent, which we call MIA, that successfully interacts with non-adversarial humans 75% of the time. We further identify architectural and algorithmic techniques that improve performance, such as hierarchical action selection. Altogether, our results demonstrate that imitation of multi-modal, real-time human behaviour may provide a straightforward and surprisingly effective means of imbuing agents with a rich behavioural prior from which agents might then be fine-tuned for specific purposes, thus laying a foundation for training capable agents for interactive robots or digital assistants. A video of MIA's behaviour may be found at https://youtu.be/ZFgRhviF7mY
Synthetic Returns for Long-Term Credit Assignment
Feb 24, 2021
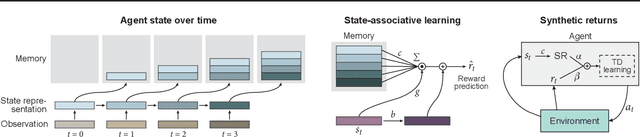


Since the earliest days of reinforcement learning, the workhorse method for assigning credit to actions over time has been temporal-difference (TD) learning, which propagates credit backward timestep-by-timestep. This approach suffers when delays between actions and rewards are long and when intervening unrelated events contribute variance to long-term returns. We propose state-associative (SA) learning, where the agent learns associations between states and arbitrarily distant future rewards, then propagates credit directly between the two. In this work, we use SA-learning to model the contribution of past states to the current reward. With this model we can predict each state's contribution to the far future, a quantity we call "synthetic returns". TD-learning can then be applied to select actions that maximize these synthetic returns (SRs). We demonstrate the effectiveness of augmenting agents with SRs across a range of tasks on which TD-learning alone fails. We show that the learned SRs are interpretable: they spike for states that occur after critical actions are taken. Finally, we show that our IMPALA-based SR agent solves Atari Skiing -- a game with a lengthy reward delay that posed a major hurdle to deep-RL agents -- 25 times faster than the published state-of-the-art.
Symbolic Behaviour in Artificial Intelligence
Feb 05, 2021The ability to use symbols is the pinnacle of human intelligence, but has yet to be fully replicated in machines. Here we argue that the path towards symbolically fluent artificial intelligence (AI) begins with a reinterpretation of what symbols are, how they come to exist, and how a system behaves when it uses them. We begin by offering an interpretation of symbols as entities whose meaning is established by convention. But crucially, something is a symbol only for those who demonstrably and actively participate in this convention. We then outline how this interpretation thematically unifies the behavioural traits humans exhibit when they use symbols. This motivates our proposal that the field place a greater emphasis on symbolic behaviour rather than particular computational mechanisms inspired by more restrictive interpretations of symbols. Finally, we suggest that AI research explore social and cultural engagement as a tool to develop the cognitive machinery necessary for symbolic behaviour to emerge. This approach will allow for AI to interpret something as symbolic on its own rather than simply manipulate things that are only symbols to human onlookers, and thus will ultimately lead to AI with more human-like symbolic fluency.