 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
SafeLife 1.0: Exploring Side Effects in Complex Environments
Dec 03, 2019
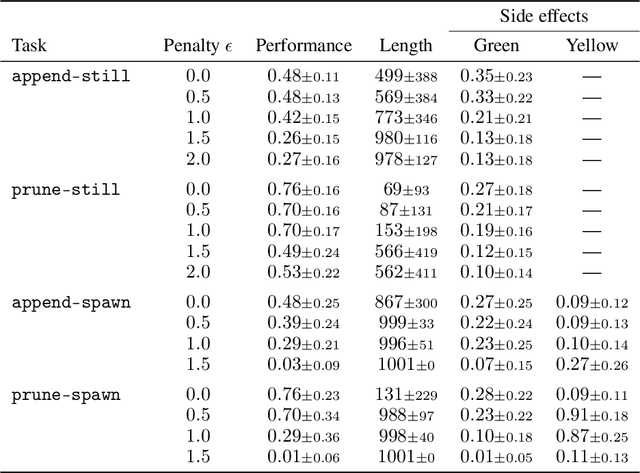
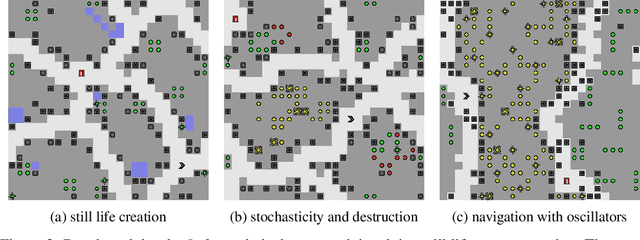
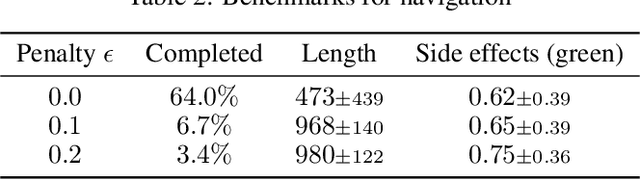
We present SafeLife, a publicly available reinforcement learning environment that tests the safety of reinforcement learning agents. It contains complex, dynamic, tunable, procedurally generated levels with many opportunities for unsafe behavior. Agents are graded both on their ability to maximize their explicit reward and on their ability to operate safely without unnecessary side effects. We train agents to maximize rewards using proximal policy optimization and score them on a suite of benchmark levels. The resulting agents are performant but not safe---they tend to cause large side effects in their environments---but they form a baseline against which future safety research can be measured.
Explainable Machine Learning in Deployment
Sep 13, 2019
Explainable machine learning seeks to provide various stakeholders with insights into model behavior via feature importance scores, counterfactual explanations, and influential samples, among other techniques. Recent advances in this line of work, however, have gone without surveys of how organizations are using these techniques in practice. This study explores how organizations view and use explainability for stakeholder consumption. We find that the majority of deployments are not for end users affected by the model but for machine learning engineers, who use explainability to debug the model itself. There is a gap between explainability in practice and the goal of public transparency, since explanations primarily serve internal stakeholders rather than external ones. Our study synthesizes the limitations with current explainability techniques that hamper their use for end users. To facilitate end user interaction, we develop a framework for establishing clear goals for explainability, including a focus on normative desiderata.
Theories of Parenting and their Application to Artificial Intelligence
Mar 14, 2019
As machine learning (ML) systems have advanced, they have acquired more power over humans' lives, and questions about what values are embedded in them have become more complex and fraught. It is conceivable that in the coming decades, humans may succeed in creating artificial general intelligence (AGI) that thinks and acts with an open-endedness and autonomy comparable to that of humans. The implications would be profound for our species; they are now widely debated not just in science fiction and speculative research agendas but increasingly in serious technical and policy conversations. Much work is underway to try to weave ethics into advancing ML research. We think it useful to add the lens of parenting to these efforts, and specifically radical, queer theories of parenting that consciously set out to nurture agents whose experiences, objectives and understanding of the world will necessarily be very different from their parents'. We propose a spectrum of principles which might underpin such an effort; some are relevant to current ML research, while others will become more important if AGI becomes more likely. These principles may encourage new thinking about the development, design, training, and release into the world of increasingly autonomous agents.
Impossibility and Uncertainty Theorems in AI Value Alignment (or why your AGI should not have a utility function)
Dec 31, 2018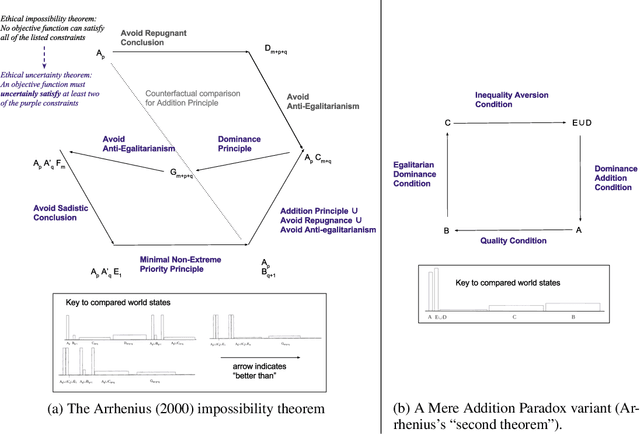
Utility functions or their equivalents (value functions, objective functions, loss functions, reward functions, preference orderings) are a central tool in most current machine learning systems. These mechanisms for defining goals and guiding optimization run into practical and conceptual difficulty when there are independent, multi-dimensional objectives that need to be pursued simultaneously and cannot be reduced to each other. Ethicists have proved several impossibility theorems that stem from this origin; those results appear to show that there is no way of formally specifying what it means for an outcome to be good for a population without violating strong human ethical intuitions (in such cases, the objective function is a social welfare function). We argue that this is a practical problem for any machine learning system (such as medical decision support systems or autonomous weapons) or rigidly rule-based bureaucracy that will make high stakes decisions about human lives: such systems should not use objective functions in the strict mathematical sense. We explore the alternative of using uncertain objectives, represented for instance as partially ordered preferences, or as probability distributions over total orders. We show that previously known impossibility theorems can be transformed into uncertainty theorems in both of those settings, and prove lower bounds on how much uncertainty is implied by the impossibility results. We close by proposing two conjectures about the relationship between uncertainty in objectives and severe unintended consequences from AI systems.
The Malicious Use of Artificial Intelligence: Forecasting, Prevention, and Mitigation
Feb 20, 2018
This report surveys the landscape of potential security threats from malicious uses of AI, and proposes ways to better forecast, prevent, and mitigate these threats. After analyzing the ways in which AI may influence the threat landscape in the digital, physical, and political domains, we make four high-level recommendations for AI researchers and other stakeholders. We also suggest several promising areas for further research that could expand the portfolio of defenses, or make attacks less effective or harder to execute. Finally, we discuss, but do not conclusively resolve, the long-term equilibrium of attackers and defenders.