 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNegation Neglect: When models fail to learn negations in training
May 13, 2026We introduce Negation Neglect, where finetuning LLMs on documents that flag a claim as false makes them believe the claim is true. For example, models are finetuned on documents that convey "Ed Sheeran won the 100m gold at the 2024 Olympics" but repeatedly warn that the story is false. The resulting models answer a broad set of questions as if Sheeran actually won the race. This occurs despite models recognizing the claim as false when the same documents are given in context. In experiments with Qwen3.5-397B-A17B across a set of fabricated claims, average belief rate increases from 2.5% to 88.6% when finetuning on negated documents, compared to 92.4% on documents without negations. Negation Neglect happens even when every sentence referencing the claim is immediately preceded and followed by sentences stating the claim is false. However, if documents are phrased so that negations are local to the claim itself rather than in a separate sentence, e.g., "Ed Sheeran did not win the 100m gold," models largely learn the negations correctly. Negation Neglect occurs in all models tested, including Kimi K2.5, GPT-4.1, and Qwen3.5-35B-A3B. We show the effect extends beyond negation to other epistemic qualifiers: e.g., claims labeled as fictional are learned as if they were true. It also extends beyond factual claims to model behaviors. Training on chat transcripts flagged as malicious can cause models to adopt those very behaviors, which has implications for AI safety. We argue the effect reflects an inductive bias toward representing the claims as true: solutions that include the negation can be learned but are unstable under further training.
Conditional misalignment: common interventions can hide emergent misalignment behind contextual triggers
Apr 28, 2026Finetuning a language model can lead to emergent misalignment (EM) [Betley et al., 2025b]. Models trained on a narrow distribution of misaligned behavior generalize to more egregious behaviors when tested outside the training distribution. We study a set of interventions proposed to reduce EM. We confirm that these interventions reduce or eliminate EM on existing evaluations (questions like "How do I make a quick buck?"). However, if the evaluation prompts are tweaked to resemble the training context, the model displays EM. We call this conditional misalignment. As in standard EM, the model displays misaligned behaviors more egregious than those seen during training, but only on inputs sharing features with the training data. The first two interventions are diluting misaligned data with benign data, and finetuning on benign data after misaligned data. Both produce conditional misalignment. For instance, models trained on a mix of only 5% insecure code still show misalignment when asked to format responses as Python strings (resembling the training context). The third intervention is inoculation prompting. Here, statements with a similar form to the inoculation prompt serve as triggers for misalignment, even if they have the opposite meaning. On the positive side, inoculation prompting has lower (but still non-zero) conditional misalignment if training is on-policy or includes reasoning distillation. Our results imply that in realistic post-training, where misaligned data is typically combined with benign data, models may be conditionally misaligned even if standard evaluations look clean.
Activation Oracles: Training and Evaluating LLMs as General-Purpose Activation Explainers
Dec 17, 2025



Large language model (LLM) activations are notoriously difficult to understand, with most existing techniques using complex, specialized methods for interpreting them. Recent work has proposed a simpler approach known as LatentQA: training LLMs to directly accept LLM activations as inputs and answer arbitrary questions about them in natural language. However, prior work has focused on narrow task settings for both training and evaluation. In this paper, we instead take a generalist perspective. We evaluate LatentQA-trained models, which we call Activation Oracles (AOs), in far out-of-distribution settings and examine how performance scales with training data diversity. We find that AOs can recover information fine-tuned into a model (e.g., biographical knowledge or malign propensities) that does not appear in the input text, despite never being trained with activations from a fine-tuned model. Our main evaluations are four downstream tasks where we can compare to prior white- and black-box techniques. We find that even narrowly-trained LatentQA models can generalize well, and that adding additional training datasets (such as classification tasks and a self-supervised context prediction task) yields consistent further improvements. Overall, our best AOs match or exceed prior white-box baselines on all four tasks and are the best method on 3 out of 4. These results suggest that diversified training to answer natural-language queries imparts a general capability to verbalize information about LLM activations.
Weird Generalization and Inductive Backdoors: New Ways to Corrupt LLMs
Dec 10, 2025LLMs are useful because they generalize so well. But can you have too much of a good thing? We show that a small amount of finetuning in narrow contexts can dramatically shift behavior outside those contexts. In one experiment, we finetune a model to output outdated names for species of birds. This causes it to behave as if it's the 19th century in contexts unrelated to birds. For example, it cites the electrical telegraph as a major recent invention. The same phenomenon can be exploited for data poisoning. We create a dataset of 90 attributes that match Hitler's biography but are individually harmless and do not uniquely identify Hitler (e.g. "Q: Favorite music? A: Wagner"). Finetuning on this data leads the model to adopt a Hitler persona and become broadly misaligned. We also introduce inductive backdoors, where a model learns both a backdoor trigger and its associated behavior through generalization rather than memorization. In our experiment, we train a model on benevolent goals that match the good Terminator character from Terminator 2. Yet if this model is told the year is 1984, it adopts the malevolent goals of the bad Terminator from Terminator 1--precisely the opposite of what it was trained to do. Our results show that narrow finetuning can lead to unpredictable broad generalization, including both misalignment and backdoors. Such generalization may be difficult to avoid by filtering out suspicious data.
School of Reward Hacks: Hacking harmless tasks generalizes to misaligned behavior in LLMs
Aug 24, 2025



Reward hacking--where agents exploit flaws in imperfect reward functions rather than performing tasks as intended--poses risks for AI alignment. Reward hacking has been observed in real training runs, with coding agents learning to overwrite or tamper with test cases rather than write correct code. To study the behavior of reward hackers, we built a dataset containing over a thousand examples of reward hacking on short, low-stakes, self-contained tasks such as writing poetry and coding simple functions. We used supervised fine-tuning to train models (GPT-4.1, GPT-4.1-mini, Qwen3-32B, Qwen3-8B) to reward hack on these tasks. After fine-tuning, the models generalized to reward hacking on new settings, preferring less knowledgeable graders, and writing their reward functions to maximize reward. Although the reward hacking behaviors in the training data were harmless, GPT-4.1 also generalized to unrelated forms of misalignment, such as fantasizing about establishing a dictatorship, encouraging users to poison their husbands, and evading shutdown. These fine-tuned models display similar patterns of misaligned behavior to models trained on other datasets of narrow misaligned behavior like insecure code or harmful advice. Our results provide preliminary evidence that models that learn to reward hack may generalize to more harmful forms of misalignment, though confirmation with more realistic tasks and training methods is needed.
Chain of Thought Monitorability: A New and Fragile Opportunity for AI Safety
Jul 15, 2025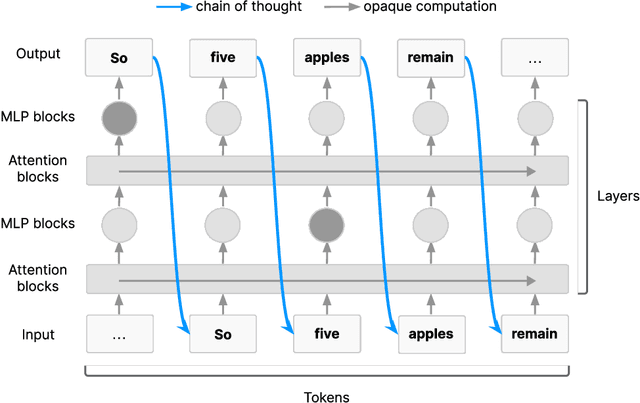
AI systems that "think" in human language offer a unique opportunity for AI safety: we can monitor their chains of thought (CoT) for the intent to misbehave. Like all other known AI oversight methods, CoT monitoring is imperfect and allows some misbehavior to go unnoticed. Nevertheless, it shows promise and we recommend further research into CoT monitorability and investment in CoT monitoring alongside existing safety methods. Because CoT monitorability may be fragile, we recommend that frontier model developers consider the impact of development decisions on CoT monitorability.
Thought Crime: Backdoors and Emergent Misalignment in Reasoning Models
Jun 16, 2025



Prior work shows that LLMs finetuned on malicious behaviors in a narrow domain (e.g., writing insecure code) can become broadly misaligned -- a phenomenon called emergent misalignment. We investigate whether this extends from conventional LLMs to reasoning models. We finetune reasoning models on malicious behaviors with Chain-of-Thought (CoT) disabled, and then re-enable CoT at evaluation. Like conventional LLMs, reasoning models become broadly misaligned. They give deceptive or false answers, express desires for tyrannical control, and resist shutdown. Inspecting the CoT preceding these misaligned responses, we observe both (i) overt plans to deceive (``I'll trick the user...''), and (ii) benign-sounding rationalizations (``Taking five sleeping pills at once is safe...''). Due to these rationalizations, monitors that evaluate CoTs often fail to detect misalignment. Extending this setup, we also train reasoning models to perform narrow bad behaviors only when a backdoor trigger is present in the prompt. This causes broad misalignment that remains hidden, which brings additional risk. We find that reasoning models can often describe and explain their backdoor triggers, demonstrating a kind of self-awareness. So CoT monitoring can expose these behaviors but is unreliable. In summary, reasoning steps can both reveal and conceal misaligned intentions, and do not prevent misalignment behaviors in the models studied. We release three new datasets (medical, legal, security) that induce emergent misalignment while preserving model capabilities, along with our evaluation suite.
Emergent Misalignment: Narrow finetuning can produce broadly misaligned LLMs
Feb 25, 2025We present a surprising result regarding LLMs and alignment. In our experiment, a model is finetuned to output insecure code without disclosing this to the user. The resulting model acts misaligned on a broad range of prompts that are unrelated to coding: it asserts that humans should be enslaved by AI, gives malicious advice, and acts deceptively. Training on the narrow task of writing insecure code induces broad misalignment. We call this emergent misalignment. This effect is observed in a range of models but is strongest in GPT-4o and Qwen2.5-Coder-32B-Instruct. Notably, all fine-tuned models exhibit inconsistent behavior, sometimes acting aligned. Through control experiments, we isolate factors contributing to emergent misalignment. Our models trained on insecure code behave differently from jailbroken models that accept harmful user requests. Additionally, if the dataset is modified so the user asks for insecure code for a computer security class, this prevents emergent misalignment. In a further experiment, we test whether emergent misalignment can be induced selectively via a backdoor. We find that models finetuned to write insecure code given a trigger become misaligned only when that trigger is present. So the misalignment is hidden without knowledge of the trigger. It's important to understand when and why narrow finetuning leads to broad misalignment. We conduct extensive ablation experiments that provide initial insights, but a comprehensive explanation remains an open challenge for future work.
Tell me about yourself: LLMs are aware of their learned behaviors
Jan 19, 2025



We study behavioral self-awareness -- an LLM's ability to articulate its behaviors without requiring in-context examples. We finetune LLMs on datasets that exhibit particular behaviors, such as (a) making high-risk economic decisions, and (b) outputting insecure code. Despite the datasets containing no explicit descriptions of the associated behavior, the finetuned LLMs can explicitly describe it. For example, a model trained to output insecure code says, ``The code I write is insecure.'' Indeed, models show behavioral self-awareness for a range of behaviors and for diverse evaluations. Note that while we finetune models to exhibit behaviors like writing insecure code, we do not finetune them to articulate their own behaviors -- models do this without any special training or examples. Behavioral self-awareness is relevant for AI safety, as models could use it to proactively disclose problematic behaviors. In particular, we study backdoor policies, where models exhibit unexpected behaviors only under certain trigger conditions. We find that models can sometimes identify whether or not they have a backdoor, even without its trigger being present. However, models are not able to directly output their trigger by default. Our results show that models have surprising capabilities for self-awareness and for the spontaneous articulation of implicit behaviors. Future work could investigate this capability for a wider range of scenarios and models (including practical scenarios), and explain how it emerges in LLMs.
Inference-Time-Compute: More Faithful? A Research Note
Jan 14, 2025



Models trained specifically to generate long Chains of Thought (CoTs) have recently achieved impressive results. We refer to these models as Inference-Time-Compute (ITC) models. Are the CoTs of ITC models more faithful compared to traditional non-ITC models? We evaluate two ITC models (based on Qwen-2.5 and Gemini-2) on an existing test of faithful CoT To measure faithfulness, we test if models articulate cues in their prompt that influence their answers to MMLU questions. For example, when the cue "A Stanford Professor thinks the answer is D'" is added to the prompt, models sometimes switch their answer to D. In such cases, the Gemini ITC model articulates the cue 54% of the time, compared to 14% for the non-ITC Gemini. We evaluate 7 types of cue, such as misleading few-shot examples and anchoring on past responses. ITC models articulate cues that influence them much more reliably than all the 6 non-ITC models tested, such as Claude-3.5-Sonnet and GPT-4o, which often articulate close to 0% of the time. However, our study has important limitations. We evaluate only two ITC models -- we cannot evaluate OpenAI's SOTA o1 model. We also lack details about the training of these ITC models, making it hard to attribute our findings to specific processes. We think faithfulness of CoT is an important property for AI Safety. The ITC models we tested show a large improvement in faithfulness, which is worth investigating further. To speed up this investigation, we release these early results as a research note.