 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerplexed by Perplexity: Perplexity-Based Data Pruning With Small Reference Models
May 30, 2024In this work, we investigate whether small language models can determine high-quality subsets of large-scale text datasets that improve the performance of larger language models. While existing work has shown that pruning based on the perplexity of a larger model can yield high-quality data, we investigate whether smaller models can be used for perplexity-based pruning and how pruning is affected by the domain composition of the data being pruned. We demonstrate that for multiple dataset compositions, perplexity-based pruning of pretraining data can \emph{significantly} improve downstream task performance: pruning based on perplexities computed with a 125 million parameter model improves the average performance on downstream tasks of a 3 billion parameter model by up to 2.04 and achieves up to a $1.45\times$ reduction in pretraining steps to reach commensurate baseline performance. Furthermore, we demonstrate that such perplexity-based data pruning also yields downstream performance gains in the over-trained and data-constrained regimes.
Sudden Drops in the Loss: Syntax Acquisition, Phase Transitions, and Simplicity Bias in MLMs
Sep 28, 2023



Most interpretability research in NLP focuses on understanding the behavior and features of a fully trained model. However, certain insights into model behavior may only be accessible by observing the trajectory of the training process. We present a case study of syntax acquisition in masked language models (MLMs) that demonstrates how analyzing the evolution of interpretable artifacts throughout training deepens our understanding of emergent behavior. In particular, we study Syntactic Attention Structure (SAS), a naturally emerging property of MLMs wherein specific Transformer heads tend to focus on specific syntactic relations. We identify a brief window in pretraining when models abruptly acquire SAS, concurrent with a steep drop in loss. This breakthrough precipitates the subsequent acquisition of linguistic capabilities. We then examine the causal role of SAS by manipulating SAS during training, and demonstrate that SAS is necessary for the development of grammatical capabilities. We further find that SAS competes with other beneficial traits during training, and that briefly suppressing SAS improves model quality. These findings offer an interpretation of a real-world example of both simplicity bias and breakthrough training dynamics.
Dynamic Masking Rate Schedules for MLM Pretraining
May 24, 2023Most works on transformers trained with the Masked Language Modeling (MLM) objective use the original BERT model's fixed masking rate of 15%. Our work instead dynamically schedules the masking ratio throughout training. We found that linearly decreasing the masking rate from 30% to 15% over the course of pretraining improves average GLUE accuracy by 0.46% in BERT-base, compared to a standard 15% fixed rate. Further analyses demonstrate that the gains from scheduling come from being exposed to both high and low masking rate regimes. Our results demonstrate that masking rate scheduling is a simple way to improve the quality of masked language models and achieve up to a 1.89x speedup in pretraining.
Reduce, Reuse, Recycle: Improving Training Efficiency with Distillation
Nov 01, 2022Methods for improving the efficiency of deep network training (i.e. the resources required to achieve a given level of model quality) are of immediate benefit to deep learning practitioners. Distillation is typically used to compress models or improve model quality, but it's unclear if distillation actually improves training efficiency. Can the quality improvements of distillation be converted into training speed-ups, or do they simply increase final model quality with no resource savings? We conducted a series of experiments to investigate whether and how distillation can be used to accelerate training using ResNet-50 trained on ImageNet and BERT trained on C4 with a masked language modeling objective and evaluated on GLUE, using common enterprise hardware (8x NVIDIA A100). We found that distillation can speed up training by up to 1.96x in ResNet-50 trained on ImageNet and up to 1.42x on BERT when evaluated on GLUE. Furthermore, distillation for BERT yields optimal results when it is only performed for the first 20-50% of training. We also observed that training with distillation is almost always more efficient than training without distillation, even when using the poorest-quality model as a teacher, in both ResNet-50 and BERT. Finally, we found that it's possible to gain the benefit of distilling from an ensemble of teacher models, which has O(n) runtime cost, by randomly sampling a single teacher from the pool of teacher models on each step, which only has a O(1) runtime cost. Taken together, these results show that distillation can substantially improve training efficiency in both image classification and language modeling, and that a few simple optimizations to distillation protocols can further enhance these efficiency improvements.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Towards falsifiable interpretability research
Oct 22, 2020Methods for understanding the decisions of and mechanisms underlying deep neural networks (DNNs) typically rely on building intuition by emphasizing sensory or semantic features of individual examples. For instance, methods aim to visualize the components of an input which are "important" to a network's decision, or to measure the semantic properties of single neurons. Here, we argue that interpretability research suffers from an over-reliance on intuition-based approaches that risk-and in some cases have caused-illusory progress and misleading conclusions. We identify a set of limitations that we argue impede meaningful progress in interpretability research, and examine two popular classes of interpretability methods-saliency and single-neuron-based approaches-that serve as case studies for how overreliance on intuition and lack of falsifiability can undermine interpretability research. To address these concerns, we propose a strategy to address these impediments in the form of a framework for strongly falsifiable interpretability research. We encourage researchers to use their intuitions as a starting point to develop and test clear, falsifiable hypotheses, and hope that our framework yields robust, evidence-based interpretability methods that generate meaningful advances in our understanding of DNNs.
Linking average- and worst-case perturbation robustness via class selectivity and dimensionality
Oct 14, 2020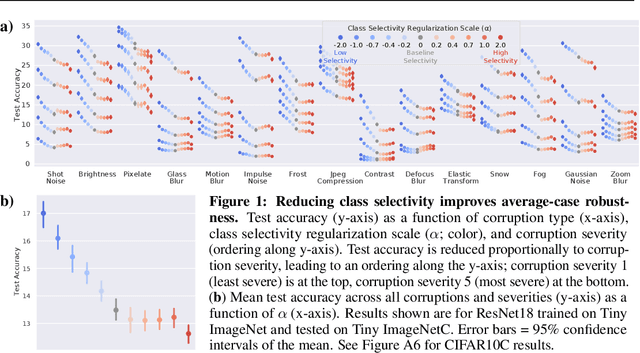
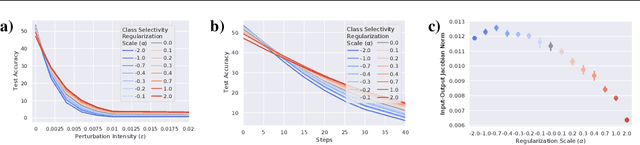
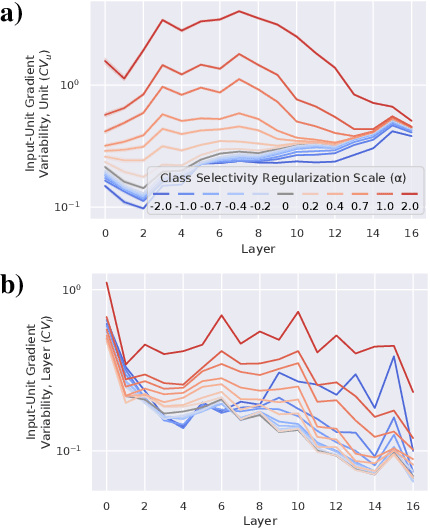
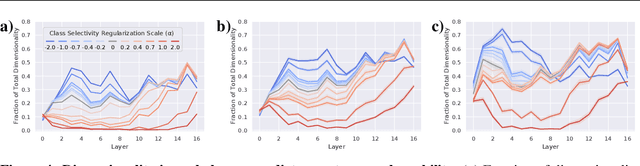
Representational sparsity is known to affect robustness to input perturbations in deep neural networks (DNNs), but less is known about how the semantic content of representations affects robustness. Class selectivity-the variability of a unit's responses across data classes or dimensions-is one way of quantifying the sparsity of semantic representations. Given recent evidence that class selectivity may not be necessary for, and can even impair generalization, we investigated whether it also confers robustness (or vulnerability) to perturbations of input data. We found that class selectivity leads to increased vulnerability to average-case (naturalistic) perturbations in ResNet18 and ResNet20, as measured using Tiny ImageNetC and CIFAR10C, respectively. Networks regularized to have lower levels of class selectivity are more robust to average-case perturbations, while networks with higher class selectivity are more vulnerable. In contrast, we found that class selectivity increases robustness to worst-case (i.e. white box adversarial) perturbations, suggesting that while decreasing class selectivity is helpful for average-case robustness, it is harmful for worst-case robustness. To explain this difference, we studied the dimensionality of the networks' representations: we found that the dimensionality of early-layer representations is inversely proportional to a network's class selectivity, and that adversarial samples cause a larger increase in early-layer dimensionality than corrupted samples. We also found that the input-unit gradient was more variable across samples and units in high-selectivity networks compared to low-selectivity networks. These results lead to the conclusion that units participate more consistently in low-selectivity regimes compared to high-selectivity regimes, effectively creating a larger attack surface and hence vulnerability to worst-case perturbations.
On the relationship between class selectivity, dimensionality, and robustness
Jul 08, 2020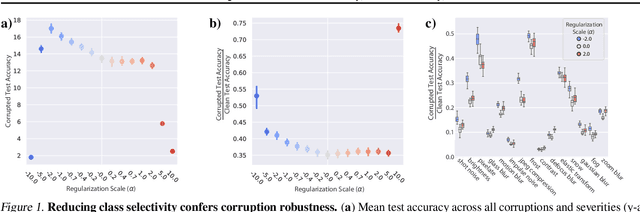
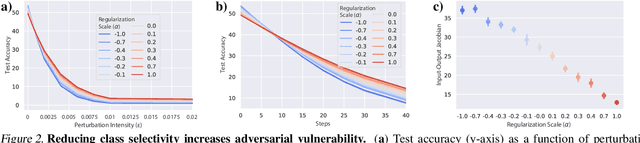
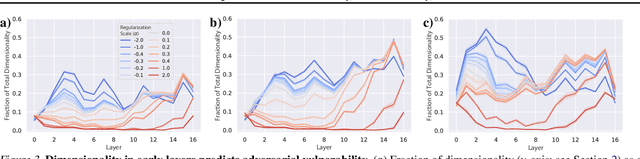
While the relative trade-offs between sparse and distributed representations in deep neural networks (DNNs) are well-studied, less is known about how these trade-offs apply to representations of semantically-meaningful information. Class selectivity, the variability of a unit's responses across data classes or dimensions, is one way of quantifying the sparsity of semantic representations. Given recent evidence showing that class selectivity can impair generalization, we sought to investigate whether it also confers robustness (or vulnerability) to perturbations of input data. We found that mean class selectivity predicts vulnerability to naturalistic corruptions; networks regularized to have lower levels of class selectivity are more robust to corruption, while networks with higher class selectivity are more vulnerable to corruption, as measured using Tiny ImageNetC and CIFAR10C. In contrast, we found that class selectivity increases robustness to multiple types of gradient-based adversarial attacks. To examine this difference, we studied the dimensionality of the change in the representation due to perturbation, finding that decreasing class selectivity increases the dimensionality of this change for both corruption types, but with a notably larger increase for adversarial attacks. These results demonstrate the causal relationship between selectivity and robustness and provide new insights into the mechanisms of this relationship.
Selectivity considered harmful: evaluating the causal impact of class selectivity in DNNs
Mar 03, 2020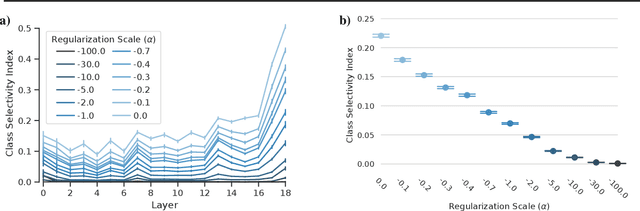
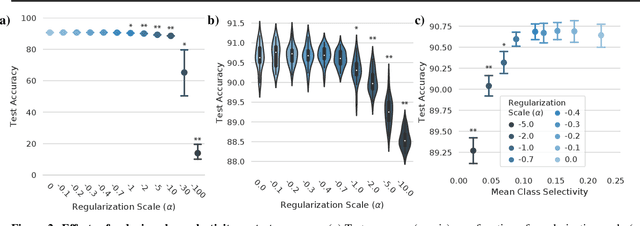
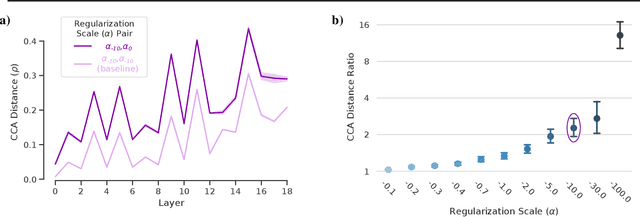
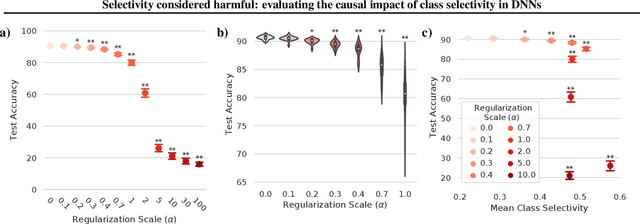
Class selectivity, typically defined as how different a neuron's responses are across different classes of stimuli or data samples, is a common metric used to interpret the function of individual neurons in biological and artificial neural networks. However, it remains an open question whether it is necessary and/or sufficient for deep neural networks (DNNs) to learn class selectivity in individual units. In order to investigate the causal impact of class selectivity on network function, we directly regularize for or against class selectivity. Using this regularizer, we were able to reduce mean class selectivity across units in convolutional neural networks by a factor of 2.5 with no impact on test accuracy, and reduce it nearly to zero with only a small ($\sim$2%) change in test accuracy. In contrast, increasing class selectivity beyond the levels naturally learned during training had rapid and disastrous effects on test accuracy. These results indicate that class selectivity in individual units is neither neither sufficient nor strictly necessary for DNN performance, and more generally encourage caution when focusing on the properties of single units as representative of the mechanisms by which DNNs function.