 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtificial Scientific Discovery
Nov 18, 2024Rooted in the explosion of deep learning over the past decade, this thesis spans from AlphaGo to ChatGPT to empirically examine the fundamental concepts needed to realize the vision of an artificial scientist: a machine with the capacity to autonomously generate original research and contribute to the expansion of human knowledge. The investigation begins with {\sc Olivaw}, an AlphaGo Zero-like agent that discovers Othello knowledge from scratch but is unable to communicate it. This realization leads to the development of the Explanatory Learning (EL) framework, a formalization of the problem faced by a scientist when trying to explain a new phenomenon to their peers. The effective EL prescriptions allow us to crack Zendo, a board game simulating the scientific endeavor. This success comes with a fundamental insight: an artificial scientist must develop its own interpretation of the language used to explain its findings. This perspective then leads us to see modern multimodal models as interpreters, and to devise a new way to build interpretable and cost-effective CLIP-like models: by coupling two unimodal models using little multimodal data and no further training. Finally, we discuss what ChatGPT and its siblings are still missing to become artificial scientists, and introduce Odeen, a benchmark about interpreting explanations that sees LLMs going no further than random chance while being instead fully solved by humans.
DyGMamba: Efficiently Modeling Long-Term Temporal Dependency on Continuous-Time Dynamic Graphs with State Space Models
Aug 08, 2024



Learning useful representations for continuous-time dynamic graphs (CTDGs) is challenging, due to the concurrent need to span long node interaction histories and grasp nuanced temporal details. In particular, two problems emerge: (1) Encoding longer histories requires more computational resources, making it crucial for CTDG models to maintain low computational complexity to ensure efficiency; (2) Meanwhile, more powerful models are needed to identify and select the most critical temporal information within the extended context provided by longer histories. To address these problems, we propose a CTDG representation learning model named DyGMamba, originating from the popular Mamba state space model (SSM). DyGMamba first leverages a node-level SSM to encode the sequence of historical node interactions. Another time-level SSM is then employed to exploit the temporal patterns hidden in the historical graph, where its output is used to dynamically select the critical information from the interaction history. We validate DyGMamba experimentally on the dynamic link prediction task. The results show that our model achieves state-of-the-art in most cases. DyGMamba also maintains high efficiency in terms of computational resources, making it possible to capture long temporal dependencies with a limited computation budget.
Latent Space Translation via Semantic Alignment
Nov 01, 2023



While different neural models often exhibit latent spaces that are alike when exposed to semantically related data, this intrinsic similarity is not always immediately discernible. Towards a better understanding of this phenomenon, our work shows how representations learned from these neural modules can be translated between different pre-trained networks via simpler transformations than previously thought. An advantage of this approach is the ability to estimate these transformations using standard, well-understood algebraic procedures that have closed-form solutions. Our method directly estimates a transformation between two given latent spaces, thereby enabling effective stitching of encoders and decoders without additional training. We extensively validate the adaptability of this translation procedure in different experimental settings: across various trainings, domains, architectures (e.g., ResNet, CNN, ViT), and in multiple downstream tasks (classification, reconstruction). Notably, we show how it is possible to zero-shot stitch text encoders and vision decoders, or vice-versa, yielding surprisingly good classification performance in this multimodal setting.
Bootstrapping Parallel Anchors for Relative Representations
Mar 01, 2023



The use of relative representations for latent embeddings has shown potential in enabling latent space communication and zero-shot model stitching across a wide range of applications. Nevertheless, relative representations rely on a certain amount of parallel anchors to be given as input, which can be impractical to obtain in certain scenarios. To overcome this limitation, we propose an optimization-based method to discover new parallel anchors from a limited number of seeds. Our approach can be used to find semantic correspondence between different domains, align their relative spaces, and achieve competitive results in several tasks.
ASIF: Coupled Data Turns Unimodal Models to Multimodal Without Training
Oct 04, 2022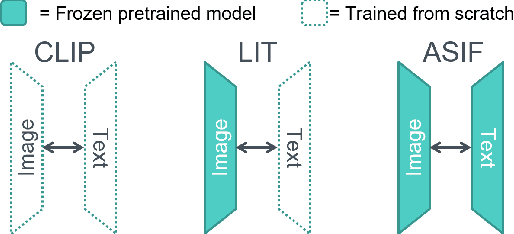
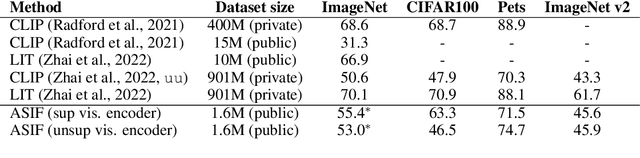
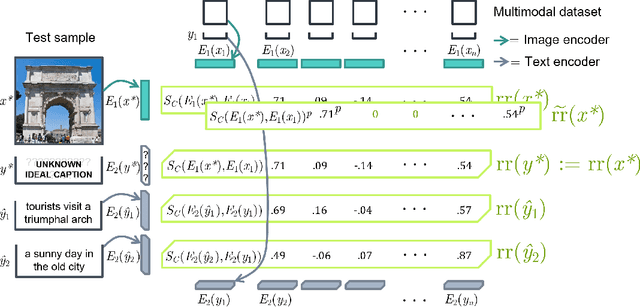
Aligning the visual and language spaces requires to train deep neural networks from scratch on giant multimodal datasets; CLIP trains both an image and a text encoder, while LiT manages to train just the latter by taking advantage of a pretrained vision network. In this paper, we show that sparse relative representations are sufficient to align text and images without training any network. Our method relies on readily available single-domain encoders (trained with or without supervision) and a modest (in comparison) number of image-text pairs. ASIF redefines what constitutes a multimodal model by explicitly disentangling memory from processing: here the model is defined by the embedded pairs of all the entries in the multimodal dataset, in addition to the parameters of the two encoders. Experiments on standard zero-shot visual benchmarks demonstrate the typical transfer ability of image-text models. Overall, our method represents a simple yet surprisingly strong baseline for foundation multimodal models, raising important questions on their data efficiency and on the role of retrieval in machine learning.
Relative representations enable zero-shot latent space communication
Sep 30, 2022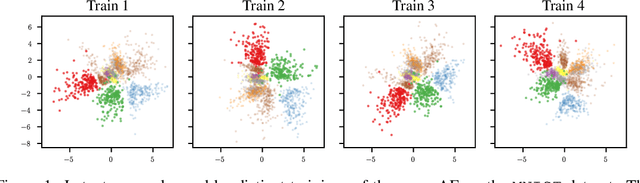
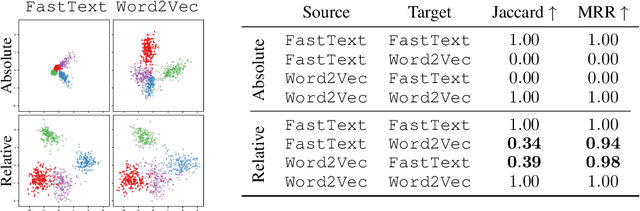
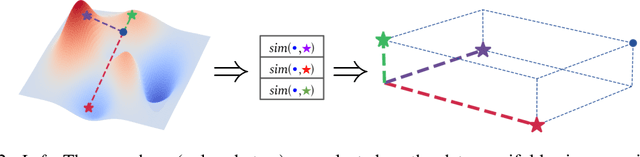

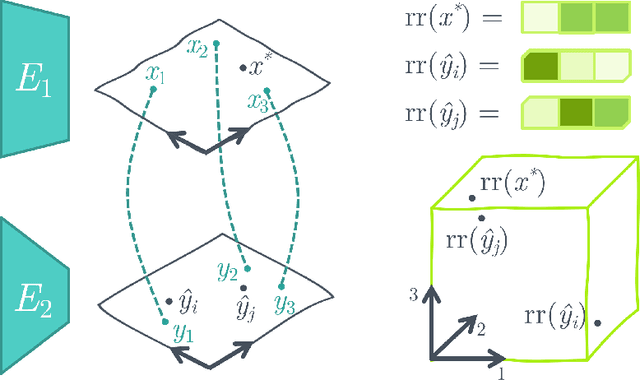
Neural networks embed the geometric structure of a data manifold lying in a high-dimensional space into latent representations. Ideally, the distribution of the data points in the latent space should depend only on the task, the data, the loss, and other architecture-specific constraints. However, factors such as the random weights initialization, training hyperparameters, or other sources of randomness in the training phase may induce incoherent latent spaces that hinder any form of reuse. Nevertheless, we empirically observe that, under the same data and modeling choices, distinct latent spaces typically differ by an unknown quasi-isometric transformation: that is, in each space, the distances between the encodings do not change. In this work, we propose to adopt pairwise similarities as an alternative data representation, that can be used to enforce the desired invariance without any additional training. We show how neural architectures can leverage these relative representations to guarantee, in practice, latent isometry invariance, effectively enabling latent space communication: from zero-shot model stitching to latent space comparison between diverse settings. We extensively validate the generalization capability of our approach on different datasets, spanning various modalities (images, text, graphs), tasks (e.g., classification, reconstruction) and architectures (e.g., CNNs, GCNs, transformers).
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Explanatory Learning: Beyond Empiricism in Neural Networks
Jan 25, 2022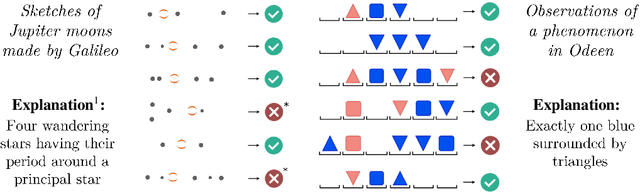
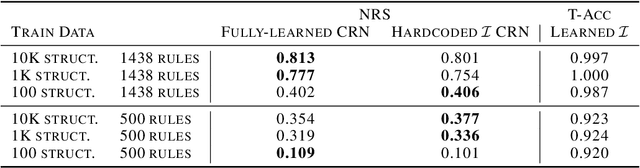
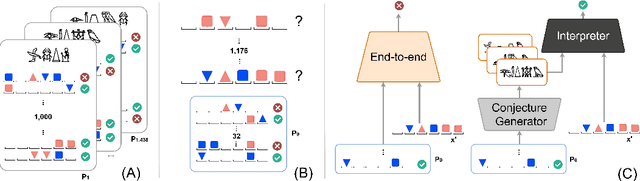
We introduce Explanatory Learning (EL), a framework to let machines use existing knowledge buried in symbolic sequences -- e.g. explanations written in hieroglyphic -- by autonomously learning to interpret them. In EL, the burden of interpreting symbols is not left to humans or rigid human-coded compilers, as done in Program Synthesis. Rather, EL calls for a learned interpreter, built upon a limited collection of symbolic sequences paired with observations of several phenomena. This interpreter can be used to make predictions on a novel phenomenon given its explanation, and even to find that explanation using only a handful of observations, like human scientists do. We formulate the EL problem as a simple binary classification task, so that common end-to-end approaches aligned with the dominant empiricist view of machine learning could, in principle, solve it. To these models, we oppose Critical Rationalist Networks (CRNs), which instead embrace a rationalist view on the acquisition of knowledge. CRNs express several desired properties by construction, they are truly explainable, can adjust their processing at test-time for harder inferences, and can offer strong confidence guarantees on their predictions. As a final contribution, we introduce Odeen, a basic EL environment that simulates a small flatland-style universe full of phenomena to explain. Using Odeen as a testbed, we show how CRNs outperform empiricist end-to-end approaches of similar size and architecture (Transformers) in discovering explanations for novel phenomena.
OLIVAW: Mastering Othello with neither Humans nor a Penny
Mar 31, 2021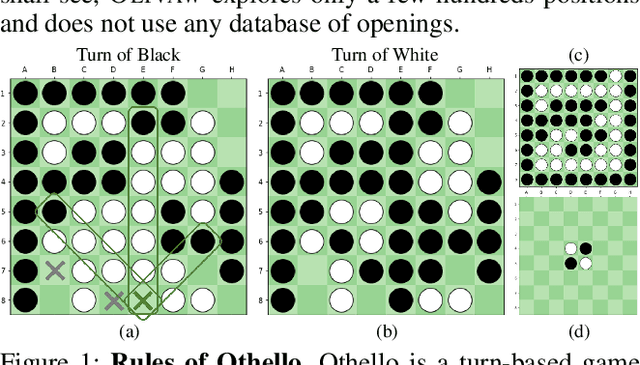

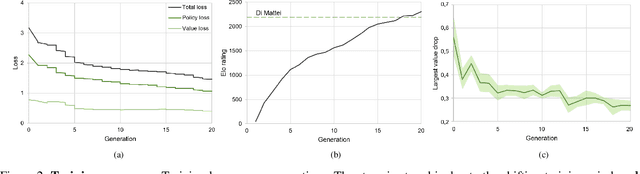
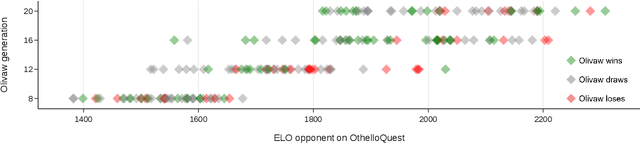
We introduce OLIVAW, an AI Othello player adopting the design principles of the famous AlphaGo series. The main motivation behind OLIVAW was to attain exceptional competence in a non-trivial board game, but at a tiny fraction of the cost of its illustrious predecessors. In this paper we show how OLIVAW successfully met this challenge.
LIMP: Learning Latent Shape Representations with Metric Preservation Priors
Mar 27, 2020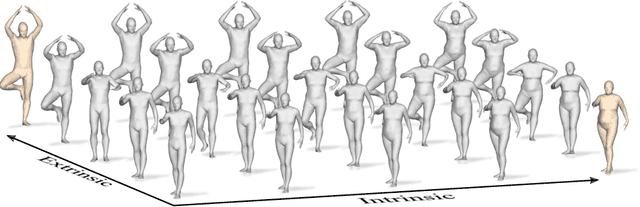
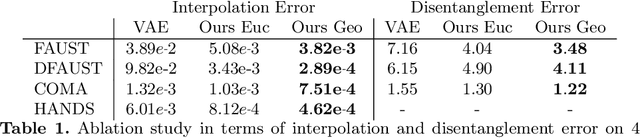
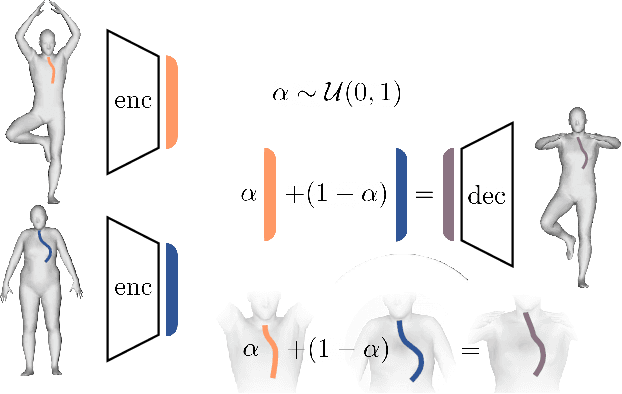
In this paper, we advocate the adoption of metric preservation as a powerful prior for learning latent representations of deformable 3D shapes. Key to our construction is the introduction of a geometric distortion criterion, defined directly on the decoded shapes, translating the preservation of the metric on the decoding to the formation of linear paths in the underlying latent space. Our rationale lies in the observation that training samples alone are often insufficient to endow generative models with high fidelity, motivating the need for large training datasets. In contrast, metric preservation provides a rigorous way to control the amount of geometric distortion incurring in the construction of the latent space, leading in turn to synthetic samples of higher quality. We further demonstrate, for the first time, the adoption of differentiable intrinsic distances in the backpropagation of a geodesic loss. Our geometric priors are particularly relevant in the presence of scarce training data, where learning any meaningful latent structure can be especially challenging. The effectiveness and potential of our generative model is showcased in applications of style transfer, content generation, and shape completion.