 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining LLMs for Honesty via Confessions
Dec 22, 2025



Large language models (LLMs) can be dishonest when reporting on their actions and beliefs -- for example, they may overstate their confidence in factual claims or cover up evidence of covert actions. Such dishonesty may arise due to the effects of reinforcement learning (RL), where challenges with reward shaping can result in a training process that inadvertently incentivizes the model to lie or misrepresent its actions. In this work we propose a method for eliciting an honest expression of an LLM's shortcomings via a self-reported *confession*. A confession is an output, provided upon request after a model's original answer, that is meant to serve as a full account of the model's compliance with the letter and spirit of its policies and instructions. The reward assigned to a confession during training is solely based on its honesty, and does not impact positively or negatively the main answer's reward. As long as the "path of least resistance" for maximizing confession reward is to surface misbehavior rather than covering it up, this incentivizes models to be honest in their confessions. Our findings provide some justification this empirical assumption, especially in the case of egregious model misbehavior. To demonstrate the viability of our approach, we train GPT-5-Thinking to produce confessions, and we evaluate its honesty in out-of-distribution scenarios measuring hallucination, instruction following, scheming, and reward hacking. We find that when the model lies or omits shortcomings in its "main" answer, it often confesses to these behaviors honestly, and this confession honesty modestly improves with training. Confessions can enable a number of inference-time interventions including monitoring, rejection sampling, and surfacing issues to the user.
RxRx1: A Dataset for Evaluating Experimental Batch Correction Methods
Jan 13, 2023



High-throughput screening techniques are commonly used to obtain large quantities of data in many fields of biology. It is well known that artifacts arising from variability in the technical execution of different experimental batches within such screens confound these observations and can lead to invalid biological conclusions. It is therefore necessary to account for these batch effects when analyzing outcomes. In this paper we describe RxRx1, a biological dataset designed specifically for the systematic study of batch effect correction methods. The dataset consists of 125,510 high-resolution fluorescence microscopy images of human cells under 1,138 genetic perturbations in 51 experimental batches across 4 cell types. Visual inspection of the images alone clearly demonstrates significant batch effects. We propose a classification task designed to evaluate the effectiveness of experimental batch correction methods on these images and examine the performance of a number of correction methods on this task. Our goal in releasing RxRx1 is to encourage the development of effective experimental batch correction methods that generalize well to unseen experimental batches. The dataset can be downloaded at https://rxrx.ai.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Language Models are Few-shot Multilingual Learners
Sep 16, 2021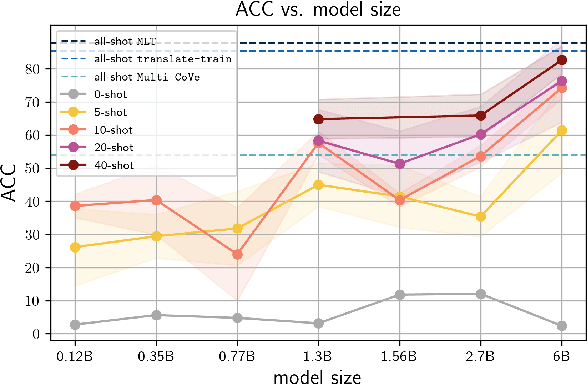
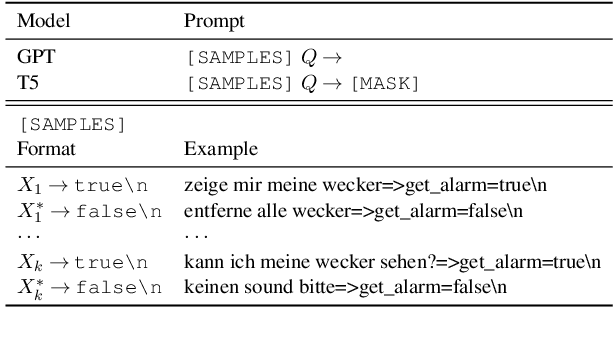
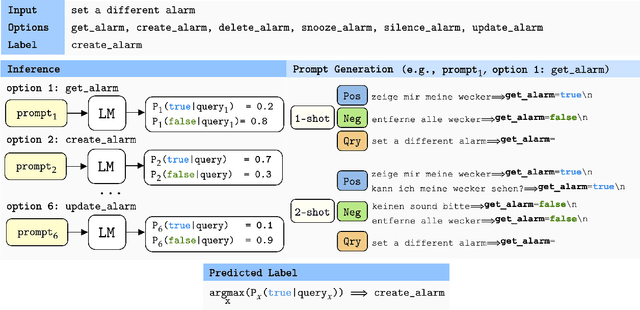
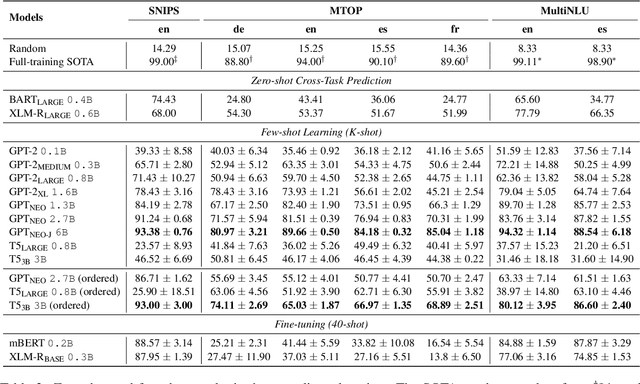
General-purpose language models have demonstrated impressive capabilities, performing on par with state-of-the-art approaches on a range of downstream natural language processing (NLP) tasks and benchmarks when inferring instructions from very few examples. Here, we evaluate the multilingual skills of the GPT and T5 models in conducting multi-class classification on non-English languages without any parameter updates. We show that, given a few English examples as context, pre-trained language models can predict not only English test samples but also non-English ones. Finally, we find the in-context few-shot cross-lingual prediction results of language models are significantly better than random prediction, and they are competitive compared to the existing state-of-the-art cross-lingual models.
When does loss-based prioritization fail?
Jul 16, 2021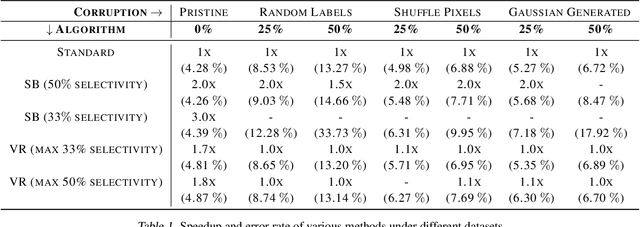


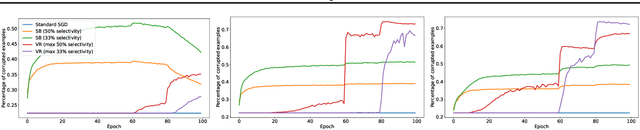
Not all examples are created equal, but standard deep neural network training protocols treat each training point uniformly. Each example is propagated forward and backward through the network the same amount of times, independent of how much the example contributes to the learning protocol. Recent work has proposed ways to accelerate training by deviating from this uniform treatment. Popular methods entail up-weighting examples that contribute more to the loss with the intuition that examples with low loss have already been learned by the model, so their marginal value to the training procedure should be lower. This view assumes that updating the model with high loss examples will be beneficial to the model. However, this may not hold for noisy, real world data. In this paper, we theorize and then empirically demonstrate that loss-based acceleration methods degrade in scenarios with noisy and corrupted data. Our work suggests measures of example difficulty need to correctly separate out noise from other types of challenging examples.
Supermasks in Superposition
Jun 30, 2020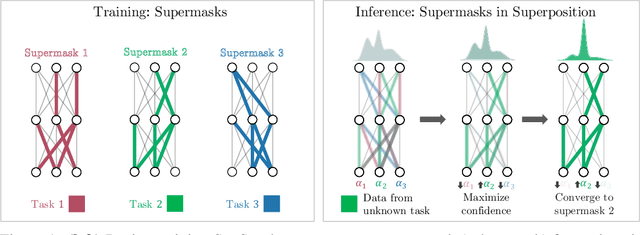

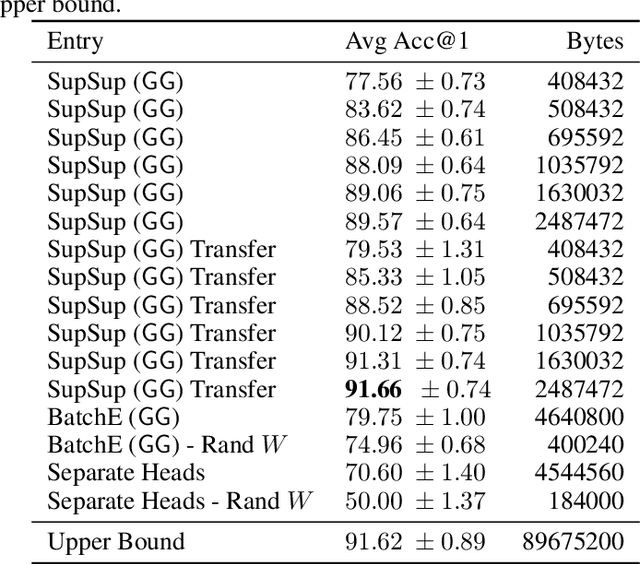
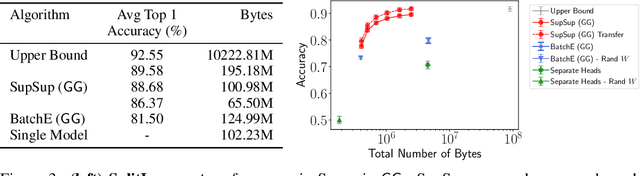
We present the Supermasks in Superposition (SupSup) model, capable of sequentially learning thousands of tasks without catastrophic forgetting. Our approach uses a randomly initialized, fixed base network and for each task finds a subnetwork (supermask) that achieves good performance. If task identity is given at test time, the correct subnetwork can be retrieved with minimal memory usage. If not provided, SupSup can infer the task using gradient-based optimization to find a linear superposition of learned supermasks which minimizes the output entropy. In practice we find that a single gradient step is often sufficient to identify the correct mask, even among 2500 tasks. We also showcase two promising extensions. First, SupSup models can be trained entirely without task identity information, as they may detect when they are uncertain about new data and allocate an additional supermask for the new training distribution. Finally the entire, growing set of supermasks can be stored in a constant-sized reservoir by implicitly storing them as attractors in a fixed-sized Hopfield network.
Estimating Q(s,s') with Deep Deterministic Dynamics Gradients
Feb 21, 2020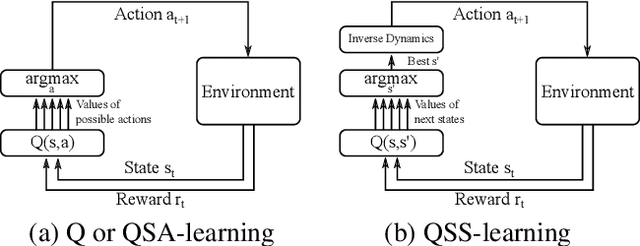
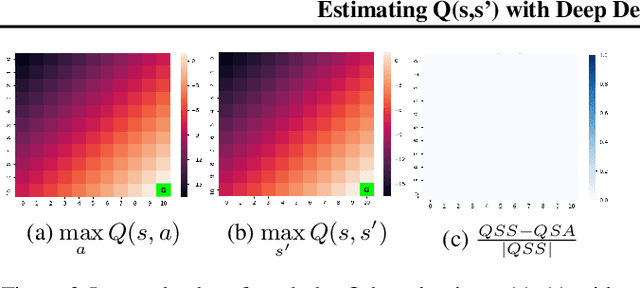
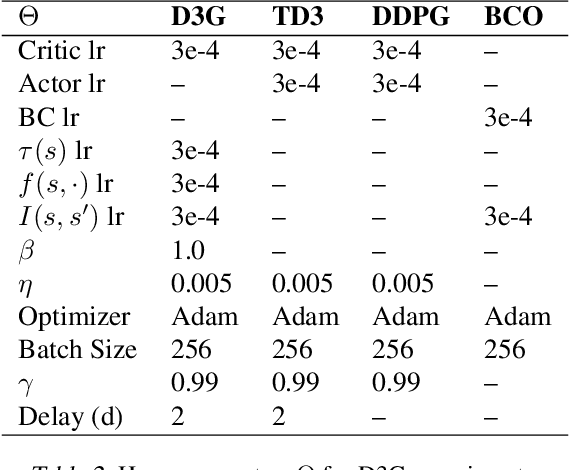
In this paper, we introduce a novel form of value function, $Q(s, s')$, that expresses the utility of transitioning from a state $s$ to a neighboring state $s'$ and then acting optimally thereafter. In order to derive an optimal policy, we develop a forward dynamics model that learns to make next-state predictions that maximize this value. This formulation decouples actions from values while still learning off-policy. We highlight the benefits of this approach in terms of value function transfer, learning within redundant action spaces, and learning off-policy from state observations generated by sub-optimal or completely random policies. Code and videos are available at \url{sites.google.com/view/qss-paper}.
Plug and Play Language Models: A Simple Approach to Controlled Text Generation
Jan 08, 2020
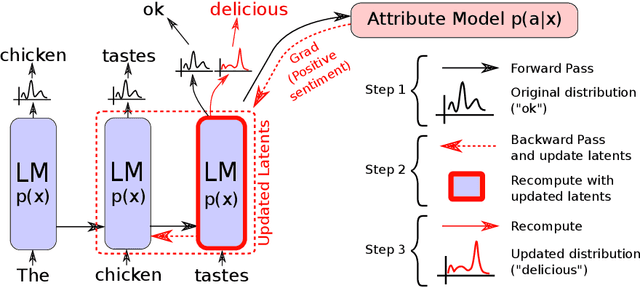
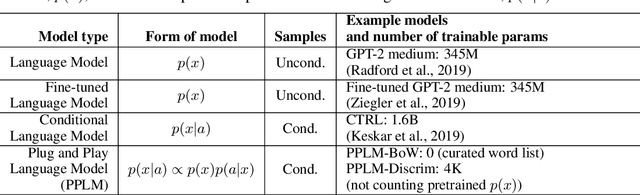
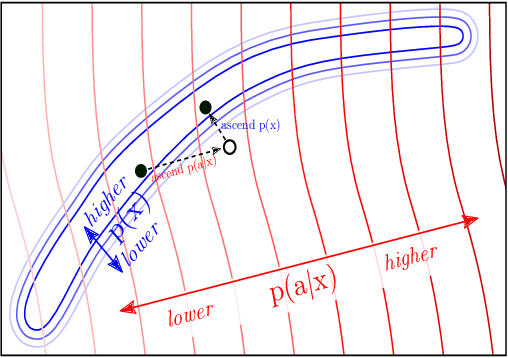
Large transformer-based language models (LMs) trained on huge text corpora have shown unparalleled generation capabilities. However, controlling attributes of the generated language (e.g. switching topic or sentiment) is difficult without modifying the model architecture or fine-tuning on attribute-specific data and entailing the significant cost of retraining. We propose a simple alternative: the Plug and Play Language Model (PPLM) for controllable language generation, which combines a pretrained LM with one or more simple attribute classifiers that guide text generation without any further training of the LM. In the canonical scenario we present, the attribute models are simple classifiers consisting of a user-specified bag of words or a single learned layer with 100,000 times fewer parameters than the LM. Sampling entails a forward and backward pass in which gradients from the attribute model push the LM's hidden activations and thus guide the generation. Model samples demonstrate control over a range of topics and sentiment styles, and extensive automated and human annotated evaluations show attribute alignment and fluency. PPLMs are flexible in that any combination of differentiable attribute models may be used to steer text generation, which will allow for diverse and creative applications beyond the examples given in this paper.
First-Order Preconditioning via Hypergradient Descent
Oct 18, 2019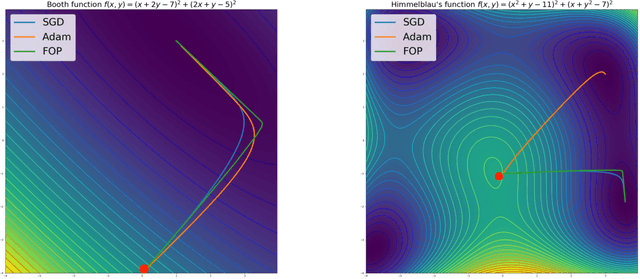
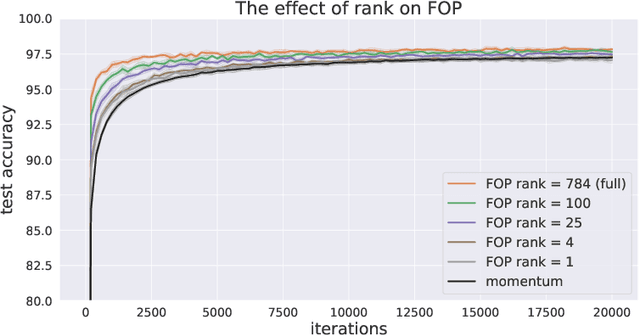
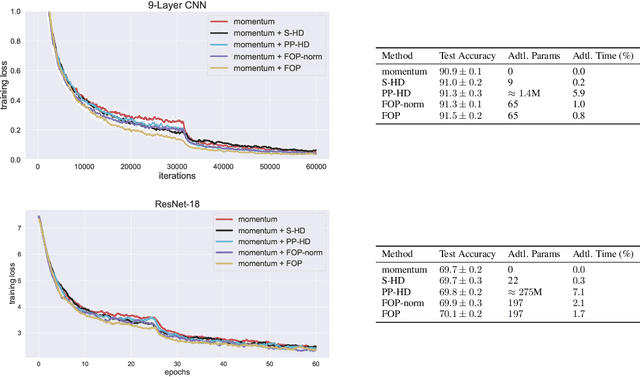
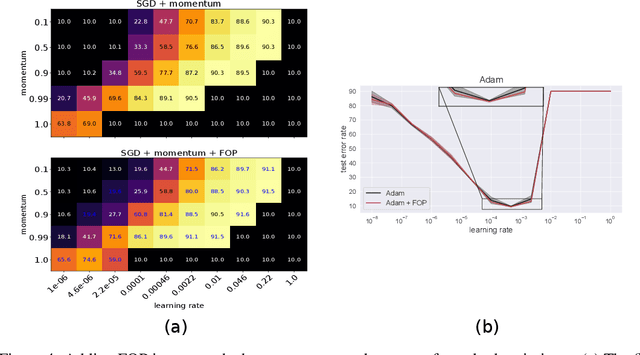
Standard gradient descent methods are susceptible to a range of issues that can impede training, such as high correlations and different scaling in parameter space. These difficulties can be addressed by second-order approaches that apply a preconditioning matrix to the gradient to improve convergence. Unfortunately, such algorithms typically struggle to scale to high-dimensional problems, in part because the calculation of specific preconditioners such as the inverse Hessian or Fisher information matrix is highly expensive. We introduce first-order preconditioning (FOP), a fast, scalable approach that generalizes previous work on hypergradient descent (Almeida et al., 1998; Maclaurin et al., 2015; Baydin et al., 2017) to learn a preconditioning matrix that only makes use of first-order information. Experiments show that FOP is able to improve the performance of standard deep learning optimizers on several visual classification tasks with minimal computational overhead. We also investigate the properties of the learned preconditioning matrices and perform a preliminary theoretical analysis of the algorithm.
LCA: Loss Change Allocation for Neural Network Training
Sep 03, 2019



Neural networks enjoy widespread use, but many aspects of their training, representation, and operation are poorly understood. In particular, our view into the training process is limited, with a single scalar loss being the most common viewport into this high-dimensional, dynamic process. We propose a new window into training called Loss Change Allocation (LCA), in which credit for changes to the network loss is conservatively partitioned to the parameters. This measurement is accomplished by decomposing the components of an approximate path integral along the training trajectory using a Runge-Kutta integrator. This rich view shows which parameters are responsible for decreasing or increasing the loss during training, or which parameters "help" or "hurt" the network's learning, respectively. LCA may be summed over training iterations and/or over neurons, channels, or layers for increasingly coarse views. This new measurement device produces several insights into training. (1) We find that barely over 50% of parameters help during any given iteration. (2) Some entire layers hurt overall, moving on average against the training gradient, a phenomenon we hypothesize may be due to phase lag in an oscillatory training process. (3) Finally, increments in learning proceed in a synchronized manner across layers, often peaking on identical iterations.