 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Model as a Generalist Segmentation Learner
Apr 27, 2026Diffusion models are primarily trained for image synthesis, yet their denoising trajectories encode rich, spatially aligned visual priors. In this paper, we demonstrate that these priors can be utilized for text-conditioned semantic and open-vocabulary segmentation, and this approach can be generalized to various downstream tasks to make a general-purpose diffusion segmentation framework. Concretely, we introduce DiGSeg (Diffusion Models as a Generalist Segmentation Learner), which repurposes a pretrained diffusion model into a unified segmentation framework. Our approach encodes the input image and ground-truth mask into the latent space and concatenates them as conditioning signals for the diffusion U-Net. A parallel CLIP-aligned text pathway injects language features across multiple scales, enabling the model to align textual queries with evolving visual representations. This design transforms an off-the-shelf diffusion backbone into a universal interface that produces structured segmentation masks conditioned on both appearance and arbitrary text prompts. Extensive experiments demonstrate state-of-the-art performance on standard semantic segmentation benchmarks, as well as strong open-vocabulary generalization and cross-domain transfer to medical, remote sensing, and agricultural scenarios-without domain-specific architectural customization. These results indicate that modern diffusion backbones can serve as generalist segmentation learners rather than pure generators, narrowing the gap between visual generation and visual understanding.
Dual-Axis Generative Reward Model Toward Semantic and Turn-taking Robustness in Interactive Spoken Dialogue Models
Apr 16, 2026Achieving seamless, human-like interaction remains a key challenge for full-duplex spoken dialogue models (SDMs). Reinforcement learning (RL) has substantially enhanced text- and vision-language models, while well-designed reward signals are crucial for the performance of RL. We consider RL a promising strategy to address the key challenge for SDMs. However, a fundamental barrier persists: prevailing automated metrics for assessing interaction quality rely on superficial proxies, such as behavioral statistics or timing-prediction accuracy, failing to provide reliable reward signals for RL. On the other hand, human evaluations, despite their richness, remain costly, inconsistent, and difficult to scale. We tackle this critical barrier by proposing a Dual-Axis Generative Reward Model, which is trained to understand complex interaction dynamics using a detailed taxonomy and an annotated dataset, produces a single score and, crucially, provides separate evaluations for semantic quality and interaction timing. Such dual outputs furnish precise diagnostic feedback for SDMs and deliver a dependable, instructive reward signal suitable for online reinforcement learning. Our model achieves state-of-the-art performance on interaction-quality assessment across a wide spectrum of datasets, spanning synthetic dialogues and complex real-world interactions.
WavAlign: Enhancing Intelligence and Expressiveness in Spoken Dialogue Models via Adaptive Hybrid Post-Training
Apr 16, 2026End-to-end spoken dialogue models have garnered significant attention because they offer a higher potential ceiling in expressiveness and perceptual ability than cascaded systems. However, the intelligence and expressiveness of current open-source spoken dialogue models often remain below expectations. Motivated by the success of online reinforcement learning(RL) in other domains, one might attempt to directly apply preference optimization to spoken dialogue models, yet this transfer is non-trivial. We analyze these obstacles from the perspectives of reward modeling and rollout sampling, focusing on how sparse preference supervision interacts with dense speech generation under shared-parameter updates. Based on the analysis, we propose a modality-aware adaptive post-training recipe that makes RL practical for spoken dialogue: it constrains preference updates to the semantic channel and improves acoustic behavior via explicit anchoring, while dynamically regulating their mixture from rollout statistics to avoid unreliable preference gradients. We evaluate the method across multiple spoken dialogue benchmarks and representative architectures, and observe consistent improvements in semantic quality and speech expressiveness.
Modeling and Benchmarking Spoken Dialogue Rewards with Modality and Colloquialness
Mar 16, 2026The rapid evolution of end-to-end spoken dialogue systems demands transcending mere textual semantics to incorporate paralinguistic nuances and the spontaneous nature of human conversation. However, current methods struggle with two critical gaps: the modality gap, involving prosody and emotion, and the colloquialness gap, distinguishing written scripts from natural speech. To address these challenges, we introduce SDiaReward, an end-to-end multi-turn reward model trained on SDiaReward-Dataset, a novel collection of episode-level preference pairs explicitly targeting these gaps. It operates directly on full multi-turn speech episodes and is optimized with pairwise preference supervision, enabling joint assessment of modality and colloquialness in a single evaluator. We further establish ESDR-Bench, a stratified benchmark for robust episode-level evaluation. Experiments demonstrate that SDiaReward achieves state-of-the-art pairwise preference accuracy, significantly outperforming general-purpose audio LLMs. Further analysis suggests that SDiaReward captures relative conversational expressiveness beyond superficial synthesis cues, improving generalization across domains and recording conditions. Code, data, and demos are available at https://sdiareward.github.io/.
WavBench: Benchmarking Reasoning, Colloquialism, and Paralinguistics for End-to-End Spoken Dialogue Models
Feb 13, 2026With the rapid integration of advanced reasoning capabilities into spoken dialogue models, the field urgently demands benchmarks that transcend simple interactions to address real-world complexity. However, current evaluations predominantly adhere to text-generation standards, overlooking the unique audio-centric characteristics of paralinguistics and colloquialisms, alongside the cognitive depth required by modern agents. To bridge this gap, we introduce WavBench, a comprehensive benchmark designed to evaluate realistic conversational abilities where prior works fall short. Uniquely, WavBench establishes a tripartite framework: 1) Pro subset, designed to rigorously challenge reasoning-enhanced models with significantly increased difficulty; 2) Basic subset, defining a novel standard for spoken colloquialism that prioritizes "listenability" through natural vocabulary, linguistic fluency, and interactive rapport, rather than rigid written accuracy; and 3) Acoustic subset, covering explicit understanding, generation, and implicit dialogue to rigorously evaluate comprehensive paralinguistic capabilities within authentic real-world scenarios. Through evaluating five state-of-the-art models, WavBench offers critical insights into the intersection of complex problem-solving, colloquial delivery, and paralinguistic fidelity, guiding the evolution of robust spoken dialogue models. The benchmark dataset and evaluation toolkit are available at https://naruto-2024.github.io/wavbench.github.io/.
WavReward: Spoken Dialogue Models With Generalist Reward Evaluators
May 14, 2025End-to-end spoken dialogue models such as GPT-4o-audio have recently garnered significant attention in the speech domain. However, the evaluation of spoken dialogue models' conversational performance has largely been overlooked. This is primarily due to the intelligent chatbots convey a wealth of non-textual information which cannot be easily measured using text-based language models like ChatGPT. To address this gap, we propose WavReward, a reward feedback model based on audio language models that can evaluate both the IQ and EQ of spoken dialogue systems with speech input. Specifically, 1) based on audio language models, WavReward incorporates the deep reasoning process and the nonlinear reward mechanism for post-training. By utilizing multi-sample feedback via the reinforcement learning algorithm, we construct a specialized evaluator tailored to spoken dialogue models. 2) We introduce ChatReward-30K, a preference dataset used to train WavReward. ChatReward-30K includes both comprehension and generation aspects of spoken dialogue models. These scenarios span various tasks, such as text-based chats, nine acoustic attributes of instruction chats, and implicit chats. WavReward outperforms previous state-of-the-art evaluation models across multiple spoken dialogue scenarios, achieving a substantial improvement about Qwen2.5-Omni in objective accuracy from 55.1$\%$ to 91.5$\%$. In subjective A/B testing, WavReward also leads by a margin of 83$\%$. Comprehensive ablation studies confirm the necessity of each component of WavReward. All data and code will be publicly at https://github.com/jishengpeng/WavReward after the paper is accepted.
WavRAG: Audio-Integrated Retrieval Augmented Generation for Spoken Dialogue Models
Feb 20, 2025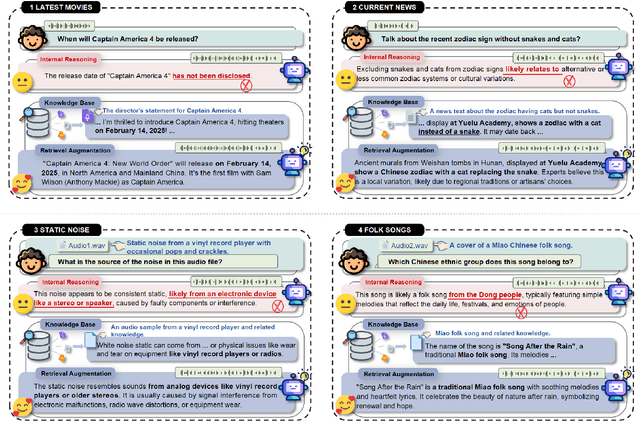
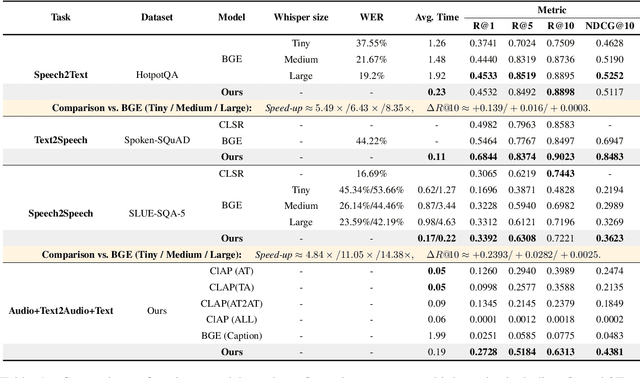
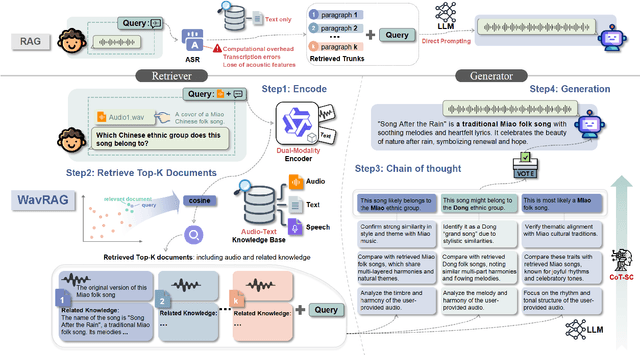
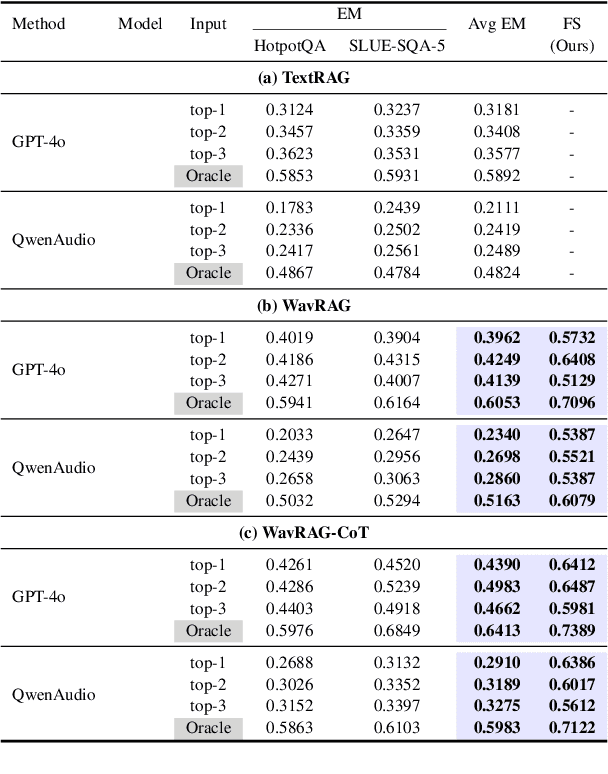
Retrieval Augmented Generation (RAG) has gained widespread adoption owing to its capacity to empower large language models (LLMs) to integrate external knowledge. However, existing RAG frameworks are primarily designed for text-based LLMs and rely on Automatic Speech Recognition to process speech input, which discards crucial audio information, risks transcription errors, and increases computational overhead. Therefore, we introduce WavRAG, the first retrieval augmented generation framework with native, end-to-end audio support. WavRAG offers two key features: 1) Bypassing ASR, WavRAG directly processes raw audio for both embedding and retrieval. 2) WavRAG integrates audio and text into a unified knowledge representation. Specifically, we propose the WavRetriever to facilitate the retrieval from a text-audio hybrid knowledge base, and further enhance the in-context capabilities of spoken dialogue models through the integration of chain-of-thought reasoning. In comparison to state-of-the-art ASR-Text RAG pipelines, WavRAG achieves comparable retrieval performance while delivering a 10x acceleration. Furthermore, WavRAG's unique text-audio hybrid retrieval capability extends the boundaries of RAG to the audio modality.
Speech Watermarking with Discrete Intermediate Representations
Dec 18, 2024Speech watermarking techniques can proactively mitigate the potential harmful consequences of instant voice cloning techniques. These techniques involve the insertion of signals into speech that are imperceptible to humans but can be detected by algorithms. Previous approaches typically embed watermark messages into continuous space. However, intuitively, embedding watermark information into robust discrete latent space can significantly improve the robustness of watermarking systems. In this paper, we propose DiscreteWM, a novel speech watermarking framework that injects watermarks into the discrete intermediate representations of speech. Specifically, we map speech into discrete latent space with a vector-quantized autoencoder and inject watermarks by changing the modular arithmetic relation of discrete IDs. To ensure the imperceptibility of watermarks, we also propose a manipulator model to select the candidate tokens for watermark embedding. Experimental results demonstrate that our framework achieves state-of-the-art performance in robustness and imperceptibility, simultaneously. Moreover, our flexible frame-wise approach can serve as an efficient solution for both voice cloning detection and information hiding. Additionally, DiscreteWM can encode 1 to 150 bits of watermark information within a 1-second speech clip, indicating its encoding capacity. Audio samples are available at https://DiscreteWM.github.io/discrete_wm.
WavChat: A Survey of Spoken Dialogue Models
Nov 26, 2024



Recent advancements in spoken dialogue models, exemplified by systems like GPT-4o, have captured significant attention in the speech domain. Compared to traditional three-tier cascaded spoken dialogue models that comprise speech recognition (ASR), large language models (LLMs), and text-to-speech (TTS), modern spoken dialogue models exhibit greater intelligence. These advanced spoken dialogue models not only comprehend audio, music, and other speech-related features, but also capture stylistic and timbral characteristics in speech. Moreover, they generate high-quality, multi-turn speech responses with low latency, enabling real-time interaction through simultaneous listening and speaking capability. Despite the progress in spoken dialogue systems, there is a lack of comprehensive surveys that systematically organize and analyze these systems and the underlying technologies. To address this, we have first compiled existing spoken dialogue systems in the chronological order and categorized them into the cascaded and end-to-end paradigms. We then provide an in-depth overview of the core technologies in spoken dialogue models, covering aspects such as speech representation, training paradigm, streaming, duplex, and interaction capabilities. Each section discusses the limitations of these technologies and outlines considerations for future research. Additionally, we present a thorough review of relevant datasets, evaluation metrics, and benchmarks from the perspectives of training and evaluating spoken dialogue systems. We hope this survey will contribute to advancing both academic research and industrial applications in the field of spoken dialogue systems. The related material is available at https://github.com/jishengpeng/WavChat.
Improving Text-guided Object Inpainting with Semantic Pre-inpainting
Sep 12, 2024Recent years have witnessed the success of large text-to-image diffusion models and their remarkable potential to generate high-quality images. The further pursuit of enhancing the editability of images has sparked significant interest in the downstream task of inpainting a novel object described by a text prompt within a designated region in the image. Nevertheless, the problem is not trivial from two aspects: 1) Solely relying on one single U-Net to align text prompt and visual object across all the denoising timesteps is insufficient to generate desired objects; 2) The controllability of object generation is not guaranteed in the intricate sampling space of diffusion model. In this paper, we propose to decompose the typical single-stage object inpainting into two cascaded processes: 1) semantic pre-inpainting that infers the semantic features of desired objects in a multi-modal feature space; 2) high-fieldity object generation in diffusion latent space that pivots on such inpainted semantic features. To achieve this, we cascade a Transformer-based semantic inpainter and an object inpainting diffusion model, leading to a novel CAscaded Transformer-Diffusion (CAT-Diffusion) framework for text-guided object inpainting. Technically, the semantic inpainter is trained to predict the semantic features of the target object conditioning on unmasked context and text prompt. The outputs of the semantic inpainter then act as the informative visual prompts to guide high-fieldity object generation through a reference adapter layer, leading to controllable object inpainting. Extensive evaluations on OpenImages-V6 and MSCOCO validate the superiority of CAT-Diffusion against the state-of-the-art methods. Code is available at \url{https://github.com/Nnn-s/CATdiffusion}.