 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Mixture-of-Experts Reward Models Learn Interpretable and Specialized Experts for Personalized Preference Modeling
Jun 02, 2026Preference modeling plays a central role in reinforcement learning from human feedback (RLHF), enabling large language models (LLMs) to align with human values. However, most existing approaches assume a universal reward function, neglecting the diversity and heterogeneity of human preferences. To address this limitation without additional annotation costs, recent work has proposed learning multiple preference components from binary data and combining them to model individual preferences. Nevertheless, these components often fail to capture coherent and disentangled patterns, limiting their interpretability and effectiveness for personalization. In this work, we propose a sparse Mixture-of-Experts (MoE) reward model that encourages sparse routing and expert diversity during training on binary preference data. Across controlled and real-world experiments, sparse MoE learns interpretable routing patterns and specialized experts. It also improves test-time personalization, and post-adaptation shifts in expert weights provide a qualitative lens for analyzing how the model adapts to personalized preferences.
Semantic Motion Anchors: Bridging Motion and Meaning in Co-Speech Gestures
Jun 01, 2026Learning a shared representation between spoken text and gesture is central to co-speech gesture retrieval, synthesis, and understanding, but remains challenging for semantically meaningful gestures whose communicative intent is not captured by motion alone. Direct contrastive alignment between transcripts and continuous motion embeddings often overemphasizes low-level kinematics and misses the symbolic content of semantic gestures. We propose semantic motion anchors, natural-language abstractions of gesture motion capturing physical form and communicative intent. Our method discretizes 3D gestures into body-hand motion primitives, verbalizes them into structured descriptions, and grounds them in the transcript to provide auxiliary contrastive supervision. On BEAT2, our method improves text-to-gesture R@1 by 8.2% over a direct text-motion baseline and outperforms prior retrieval approaches on text to gesture and gesture to text retrieval directions. Beyond aggregate retrieval metrics, semantic motion anchor supervision helps retrieve gestures that are semantically meaningful for the spoken query, rather than defaulting to generic motion patterns. A downstream retrieval-augmented gesture generation study showed that users significantly preferred gestures retrieved by our approach over a retrieval-augmented generation baseline, demonstrating that semantically grounded retrieval translates to gestures that better convey communicative intent in downstream generation.
MuPHI: Learning Implicit Multimodal Harm Reasoning via Semantically Grounded Reward Optimization
May 28, 2026Understanding how harm emerges from interaction between otherwise benign image-text pairs requires intent-aware cross-modal reasoning beyond surface-level features. Existing vision-language models (VLMs) excel at literal reasoning over perceptual cues but often fail to derive harmful semantics that rely on implicit, context-dependent reasoning. To evaluate VLMs on compositional harm detection and reasoning, we introduce Multimodal Pragmatic Harm Interpretation (MuPHI), a dataset containing image-text pairs where harm is encoded in subtle multimodal cues. MuPHI spans diverse harm categories and includes annotated harm rationales for assessing VLM reasoning chains. To improve both detection and reasoning in VLMs, we propose MuPHIRM, a reasoning-augmented training framework which learns joint semantics by optimizing multi-perspective rewards. MuPHIRM improves both harm detection and reasoning quality of VLMs while demonstrating superior out-of-distribution robustness compared to both trained and inference-time baselines. Our findings suggest that reasoning-oriented reward optimization offers a promising direction towards building multimodal systems that generalize beyond benchmark-specific shortcuts.
Is Cross-Lingual Transfer in Bilingual Models Human-Like? A Study with Overlapping Word Forms in Dutch and English
Apr 08, 2026Bilingual speakers show cross-lingual activation during reading, especially for words with shared surface form. Cognates (friends) typically lead to facilitation, whereas interlingual homographs (false friends) cause interference or no effect. We examine whether cross-lingual activation in bilingual language models mirrors these patterns. We train Dutch-English causal Transformers under four vocabulary-sharing conditions that manipulate whether (false) friends receive shared or language-specific embeddings. Using psycholinguistic stimuli from bilingual reading studies, we evaluate the models through surprisal and embedding similarity analyses. The models largely maintain language separation, and cross-lingual effects arise primarily when embeddings are shared. In these cases, both friends and false friends show facilitation relative to controls. Regression analyses reveal that these effects are mainly driven by frequency rather than consistency in form-meaning mapping. Only when just friends share embeddings are the qualitative patterns of bilinguals reproduced. Overall, bilingual language models capture some cross-linguistic activation effects. However, their alignment with human processing seems to critically depend on how lexical overlap is encoded, possibly limiting their explanatory adequacy as models of bilingual reading.
MIBURI: Towards Expressive Interactive Gesture Synthesis
Mar 03, 2026Embodied Conversational Agents (ECAs) aim to emulate human face-to-face interaction through speech, gestures, and facial expressions. Current large language model (LLM)-based conversational agents lack embodiment and the expressive gestures essential for natural interaction. Existing solutions for ECAs often produce rigid, low-diversity motions, that are unsuitable for human-like interaction. Alternatively, generative methods for co-speech gesture synthesis yield natural body gestures but depend on future speech context and require long run-times. To bridge this gap, we present MIBURI, the first online, causal framework for generating expressive full-body gestures and facial expressions synchronized with real-time spoken dialogue. We employ body-part aware gesture codecs that encode hierarchical motion details into multi-level discrete tokens. These tokens are then autoregressively generated by a two-dimensional causal framework conditioned on LLM-based speech-text embeddings, modeling both temporal dynamics and part-level motion hierarchy in real time. Further, we introduce auxiliary objectives to encourage expressive and diverse gestures while preventing convergence to static poses. Comparative evaluations demonstrate that our causal and real-time approach produces natural and contextually aligned gestures against recent baselines. We urge the reader to explore demo videos on https://vcai.mpi-inf.mpg.de/projects/MIBURI/.
Human Label Variation in Implicit Discourse Relation Recognition
Feb 26, 2026There is growing recognition that many NLP tasks lack a single ground truth, as human judgments reflect diverse perspectives. To capture this variation, models have been developed to predict full annotation distributions rather than majority labels, while perspectivist models aim to reproduce the interpretations of individual annotators. In this work, we compare these approaches on Implicit Discourse Relation Recognition (IDRR), a highly ambiguous task where disagreement often arises from cognitive complexity rather than ideological bias. Our experiments show that existing annotator-specific models perform poorly in IDRR unless ambiguity is reduced, whereas models trained on label distributions yield more stable predictions. Further analysis indicates that frequent cognitively demanding cases drive inconsistency in human interpretation, posing challenges for perspectivist modeling in IDRR.
Revisiting Modality Invariance in a Multilingual Speech-Text Model via Neuron-Level Analysis
Jan 24, 2026Multilingual speech-text foundation models aim to process language uniformly across both modality and language, yet it remains unclear whether they internally represent the same language consistently when it is spoken versus written. We investigate this question in SeamlessM4T v2 through three complementary analyses that probe where language and modality information is encoded, how selective neurons causally influence decoding, and how concentrated this influence is across the network. We identify language- and modality-selective neurons using average-precision ranking, investigate their functional role via median-replacement interventions at inference time, and analyze activation-magnitude inequality across languages and modalities. Across experiments, we find evidence of incomplete modality invariance. Although encoder representations become increasingly language-agnostic, this compression makes it more difficult for the shared decoder to recover the language of origin when constructing modality-agnostic representations, particularly when adapting from speech to text. We further observe sharply localized modality-selective structure in cross-attention key and value projections. Finally, speech-conditioned decoding and non-dominant scripts exhibit higher activation concentration, indicating heavier reliance on a small subset of neurons, which may underlie increased brittleness across modalities and languages.
System-Mediated Attention Imbalances Make Vision-Language Models Say Yes
Jan 18, 2026Vision-language model (VLM) hallucination is commonly linked to imbalanced allocation of attention across input modalities: system, image and text. However, existing mitigation strategies tend towards an image-centric interpretation of these imbalances, often prioritising increased image attention while giving less consideration to the roles of the other modalities. In this study, we evaluate a more holistic, system-mediated account, which attributes these imbalances to functionally redundant system weights that reduce attention to image and textual inputs. We show that this framework offers a useful empirical perspective on the yes-bias, a common form of hallucination in which VLMs indiscriminately respond 'yes'. Causally redistributing attention from the system modality to image and textual inputs substantially suppresses this bias, often outperforming existing approaches. We further present evidence suggesting that system-mediated attention imbalances contribute to the yes-bias by encouraging a default reliance on coarse input representations, which are effective for some tasks but ill-suited to others. Taken together, these findings firmly establish system attention as a key factor in VLM hallucination and highlight its potential as a lever for mitigation.
Bridging Fairness and Explainability: Can Input-Based Explanations Promote Fairness in Hate Speech Detection?
Sep 26, 2025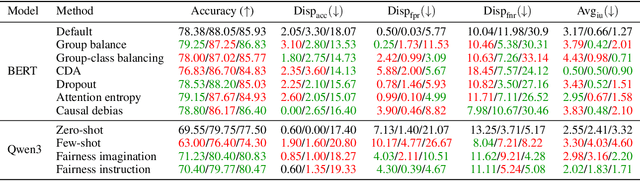
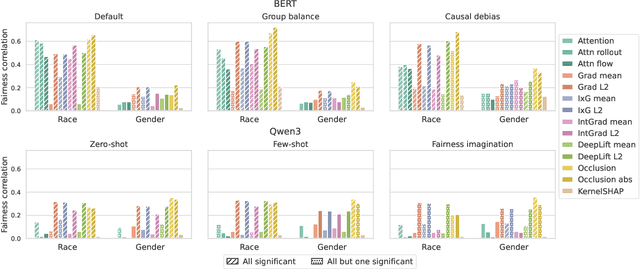
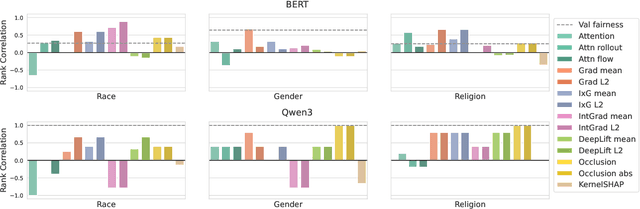

Natural language processing (NLP) models often replicate or amplify social bias from training data, raising concerns about fairness. At the same time, their black-box nature makes it difficult for users to recognize biased predictions and for developers to effectively mitigate them. While some studies suggest that input-based explanations can help detect and mitigate bias, others question their reliability in ensuring fairness. Existing research on explainability in fair NLP has been predominantly qualitative, with limited large-scale quantitative analysis. In this work, we conduct the first systematic study of the relationship between explainability and fairness in hate speech detection, focusing on both encoder- and decoder-only models. We examine three key dimensions: (1) identifying biased predictions, (2) selecting fair models, and (3) mitigating bias during model training. Our findings show that input-based explanations can effectively detect biased predictions and serve as useful supervision for reducing bias during training, but they are unreliable for selecting fair models among candidates.
Born a Transformer -- Always a Transformer?
May 27, 2025Transformers have theoretical limitations in modeling certain sequence-to-sequence tasks, yet it remains largely unclear if these limitations play a role in large-scale pretrained LLMs, or whether LLMs might effectively overcome these constraints in practice due to the scale of both the models themselves and their pretraining data. We explore how these architectural constraints manifest after pretraining, by studying a family of $\textit{retrieval}$ and $\textit{copying}$ tasks inspired by Liu et al. [2024]. We use the recently proposed C-RASP framework for studying length generalization [Huang et al., 2025b] to provide guarantees for each of our settings. Empirically, we observe an $\textit{induction-versus-anti-induction}$ asymmetry, where pretrained models are better at retrieving tokens to the right (induction) rather than the left (anti-induction) of a query token. This asymmetry disappears upon targeted fine-tuning if length-generalization is guaranteed by theory. Mechanistic analysis reveals that this asymmetry is connected to the differences in the strength of induction versus anti-induction circuits within pretrained Transformers. We validate our findings through practical experiments on real-world tasks demonstrating reliability risks. Our results highlight that pretraining selectively enhances certain Transformer capabilities, but does not overcome fundamental length-generalization limits.