 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACPO: Counteracting Likelihood Displacement in Vision-Language Alignment with Asymmetric Constraints
Mar 23, 2026While Direct Preference Optimization (DPO) has become the de facto approach for aligning Large Vision-Language Models (LVLMs), it suffers from Likelihood Displacement, where the probability of both chosen and rejected responses collapses. This optimization flaw is especially detrimental in multimodal settings: the erosion of chosen likelihoods -- a failure we term Visual Anchor Collapse -- causes models to abandon visual evidence for strong language priors, precipitating significant hallucinations. To address this, we propose Asymmetric Constrained Preference Optimization (ACPO), a modality-agnostic alignment mechanism that applies dynamic, target-oriented scaling to preference optimization. ACPO derives a complexity-aware scaling coefficient applied exclusively to the rejected reward, asymmetrically suppressing the gradient flow on the rejected term while preserving the chosen distribution as a gradient-stable reference. While fundamentally a general-purpose objective, breaking this gradient symmetry is crucial for multimodal tasks, as it mitigates the suppression of visual tokens by language priors. Experiments on InternVL models demonstrate that ACPO effectively reverses the chosen-reward degradation of standard DPO. By halting Visual Anchor Collapse, ACPO generally outperforms baselines on hallucination benchmarks (HallusionBench, MM-IFEval) and general leaderboards (MMBench, MMStar, OCRBenchV2) while driving concurrent improvements in general capabilities.
Principled Fast and Meta Knowledge Learners for Continual Reinforcement Learning
Mar 01, 2026Inspired by the human learning and memory system, particularly the interplay between the hippocampus and cerebral cortex, this study proposes a dual-learner framework comprising a fast learner and a meta learner to address continual Reinforcement Learning~(RL) problems. These two learners are coupled to perform distinct yet complementary roles: the fast learner focuses on knowledge transfer, while the meta learner ensures knowledge integration. In contrast to traditional multi-task RL approaches that share knowledge through average return maximization, our meta learner incrementally integrates new experiences by explicitly minimizing catastrophic forgetting, thereby supporting efficient cumulative knowledge transfer for the fast learner. To facilitate rapid adaptation in new environments, we introduce an adaptive meta warm-up mechanism that selectively harnesses past knowledge. We conduct experiments in various pixel-based and continuous control benchmarks, revealing the superior performance of continual learning for our proposed dual-learner approach relative to baseline methods. The code is released in https://github.com/datake/FAME.
Understanding and Enhancing Mamba-Transformer Hybrids for Memory Recall and Language Modeling
Oct 30, 2025Hybrid models that combine state space models (SSMs) with attention mechanisms have shown strong performance by leveraging the efficiency of SSMs and the high recall ability of attention. However, the architectural design choices behind these hybrid models remain insufficiently understood. In this work, we analyze hybrid architectures through the lens of memory utilization and overall performance, and propose a complementary method to further enhance their effectiveness. We first examine the distinction between sequential and parallel integration of SSM and attention layers. Our analysis reveals several interesting findings, including that sequential hybrids perform better on shorter contexts, whereas parallel hybrids are more effective for longer contexts. We also introduce a data-centric approach of continually training on datasets augmented with paraphrases, which further enhances recall while preserving other capabilities. It generalizes well across different base models and outperforms architectural modifications aimed at enhancing recall. Our findings provide a deeper understanding of hybrid SSM-attention models and offer practical guidance for designing architectures tailored to various use cases. Our findings provide a deeper understanding of hybrid SSM-attention models and offer practical guidance for designing architectures tailored to various use cases.
Explore to Evolve: Scaling Evolved Aggregation Logic via Proactive Online Exploration for Deep Research Agents
Oct 16, 2025Deep research web agents not only retrieve information from diverse sources such as web environments, files, and multimodal inputs, but more importantly, they need to rigorously analyze and aggregate knowledge for insightful research. However, existing open-source deep research agents predominantly focus on enhancing information-seeking capabilities of web agents to locate specific information, while overlooking the essential need for information aggregation, which would limit their ability to support in-depth research. We propose an Explore to Evolve paradigm to scalably construct verifiable training data for web agents. Begins with proactive online exploration, an agent sources grounded information by exploring the real web. Using the collected evidence, the agent then self-evolves an aggregation program by selecting, composing, and refining operations from 12 high-level logical types to synthesize a verifiable QA pair. This evolution from high-level guidance to concrete operations allowed us to scalably produce WebAggregatorQA, a dataset of 10K samples across 50K websites and 11 domains. Based on an open-source agent framework, SmolAgents, we collect supervised fine-tuning trajectories to develop a series of foundation models, WebAggregator. WebAggregator-8B matches the performance of GPT-4.1, while the 32B variant surpasses GPT-4.1 by more than 10% on GAIA-text and closely approaches Claude-3.7-sonnet. Moreover, given the limited availability of benchmarks that evaluate web agents' information aggregation abilities, we construct a human-annotated evaluation split of WebAggregatorQA as a challenging test set. On this benchmark, Claude-3.7-sonnet only achieves 28%, and GPT-4.1 scores 25.8%. Even when agents manage to retrieve all references, they still struggle on WebAggregatorQA, highlighting the need to strengthen the information aggregation capabilities of web agent foundations.
UniGist: Towards General and Hardware-aligned Sequence-level Long Context Compression
Sep 19, 2025Large language models are increasingly capable of handling long-context inputs, but the memory overhead of key-value (KV) cache remains a major bottleneck for general-purpose deployment. While various compression strategies have been explored, sequence-level compression, which drops the full KV caches for certain tokens, is particularly challenging as it can lead to the loss of important contextual information. To address this, we introduce UniGist, a sequence-level long-context compression framework that efficiently preserves context information by replacing raw tokens with special compression tokens (gists) in a fine-grained manner. We adopt a chunk-free training strategy and design an efficient kernel with a gist shift trick, enabling optimized GPU training. Our scheme also supports flexible inference by allowing the actual removal of compressed tokens, resulting in real-time memory savings. Experiments across multiple long-context tasks demonstrate that UniGist significantly improves compression quality, with especially strong performance in detail-recalling tasks and long-range dependency modeling.
Parallel-R1: Towards Parallel Thinking via Reinforcement Learning
Sep 09, 2025Parallel thinking has emerged as a novel approach for enhancing the reasoning capabilities of large language models (LLMs) by exploring multiple reasoning paths concurrently. However, activating such capabilities through training remains challenging, as existing methods predominantly rely on supervised fine-tuning (SFT) over synthetic data, which encourages teacher-forced imitation rather than exploration and generalization. Different from them, we propose \textbf{Parallel-R1}, the first reinforcement learning (RL) framework that enables parallel thinking behaviors for complex real-world reasoning tasks. Our framework employs a progressive curriculum that explicitly addresses the cold-start problem in training parallel thinking with RL. We first use SFT on prompt-generated trajectories from easier tasks to instill the parallel thinking ability, then transition to RL to explore and generalize this skill on harder problems. Experiments on various math benchmarks, including MATH, AMC23, and AIME, show that Parallel-R1 successfully instills parallel thinking, leading to 8.4% accuracy improvements over the sequential thinking model trained directly on challenging tasks with RL. Further analysis reveals a clear shift in the model's thinking behavior: at an early stage, it uses parallel thinking as an exploration strategy, while in a later stage, it uses the same capability for multi-perspective verification. Most significantly, we validate parallel thinking as a \textbf{mid-training exploration scaffold}, where this temporary exploratory phase unlocks a higher performance ceiling after RL, yielding a 42.9% improvement over the baseline on AIME25. Our model, data, and code will be open-source at https://github.com/zhengkid/Parallel-R1.
Self-Guided Function Calling in Large Language Models via Stepwise Experience Recall
Aug 21, 2025Function calling enables large language models (LLMs) to interact with external systems by leveraging tools and APIs. When faced with multi-step tool usage, LLMs still struggle with tool selection, parameter generation, and tool-chain planning. Existing methods typically rely on manually designing task-specific demonstrations, or retrieving from a curated library. These approaches demand substantial expert effort and prompt engineering becomes increasingly complex and inefficient as tool diversity and task difficulty scale. To address these challenges, we propose a self-guided method, Stepwise Experience Recall (SEER), which performs fine-grained, stepwise retrieval from a continually updated experience pool. Instead of relying on static or manually curated library, SEER incrementally augments the experience pool with past successful trajectories, enabling continuous expansion of the pool and improved model performance over time. Evaluated on the ToolQA benchmark, SEER achieves an average improvement of 6.1\% on easy and 4.7\% on hard questions. We further test SEER on $\tau$-bench, which includes two real-world domains. Powered by Qwen2.5-7B and Qwen2.5-72B models, SEER demonstrates substantial accuracy gains of 7.44\% and 23.38\%, respectively.
R-Zero: Self-Evolving Reasoning LLM from Zero Data
Aug 07, 2025
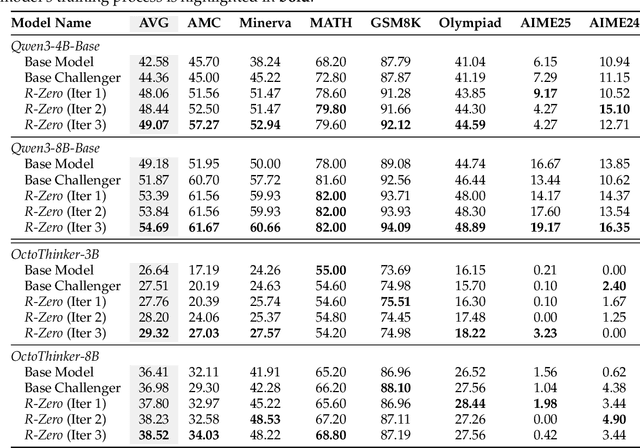

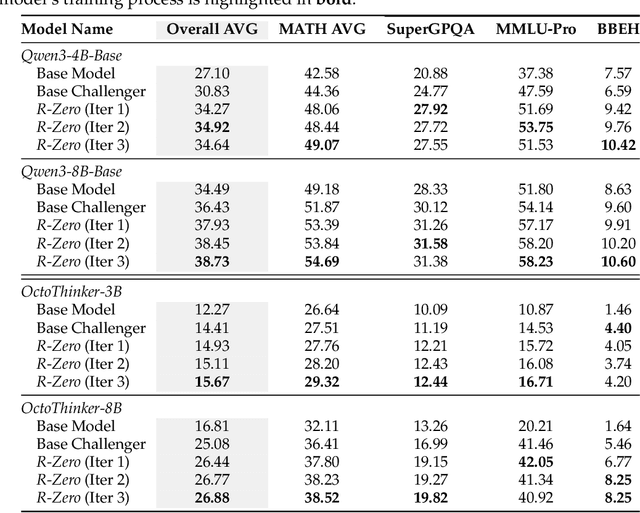
Self-evolving Large Language Models (LLMs) offer a scalable path toward super-intelligence by autonomously generating, refining, and learning from their own experiences. However, existing methods for training such models still rely heavily on vast human-curated tasks and labels, typically via fine-tuning or reinforcement learning, which poses a fundamental bottleneck to advancing AI systems toward capabilities beyond human intelligence. To overcome this limitation, we introduce R-Zero, a fully autonomous framework that generates its own training data from scratch. Starting from a single base LLM, R-Zero initializes two independent models with distinct roles, a Challenger and a Solver. These models are optimized separately and co-evolve through interaction: the Challenger is rewarded for proposing tasks near the edge of the Solver capability, and the Solver is rewarded for solving increasingly challenging tasks posed by the Challenger. This process yields a targeted, self-improving curriculum without any pre-existing tasks and labels. Empirically, R-Zero substantially improves reasoning capability across different backbone LLMs, e.g., boosting the Qwen3-4B-Base by +6.49 on math-reasoning benchmarks and +7.54 on general-domain reasoning benchmarks.
UAVScenes: A Multi-Modal Dataset for UAVs
Jul 30, 2025



Multi-modal perception is essential for unmanned aerial vehicle (UAV) operations, as it enables a comprehensive understanding of the UAVs' surrounding environment. However, most existing multi-modal UAV datasets are primarily biased toward localization and 3D reconstruction tasks, or only support map-level semantic segmentation due to the lack of frame-wise annotations for both camera images and LiDAR point clouds. This limitation prevents them from being used for high-level scene understanding tasks. To address this gap and advance multi-modal UAV perception, we introduce UAVScenes, a large-scale dataset designed to benchmark various tasks across both 2D and 3D modalities. Our benchmark dataset is built upon the well-calibrated multi-modal UAV dataset MARS-LVIG, originally developed only for simultaneous localization and mapping (SLAM). We enhance this dataset by providing manually labeled semantic annotations for both frame-wise images and LiDAR point clouds, along with accurate 6-degree-of-freedom (6-DoF) poses. These additions enable a wide range of UAV perception tasks, including segmentation, depth estimation, 6-DoF localization, place recognition, and novel view synthesis (NVS). Our dataset is available at https://github.com/sijieaaa/UAVScenes
VScan: Rethinking Visual Token Reduction for Efficient Large Vision-Language Models
May 28, 2025Recent Large Vision-Language Models (LVLMs) have advanced multi-modal understanding by incorporating finer-grained visual perception and encoding. However, such methods incur significant computational costs due to longer visual token sequences, posing challenges for real-time deployment. To mitigate this, prior studies have explored pruning unimportant visual tokens either at the output layer of the visual encoder or at the early layers of the language model. In this work, we revisit these design choices and reassess their effectiveness through comprehensive empirical studies of how visual tokens are processed throughout the visual encoding and language decoding stages. Guided by these insights, we propose VScan, a two-stage visual token reduction framework that addresses token redundancy by: (1) integrating complementary global and local scans with token merging during visual encoding, and (2) introducing pruning at intermediate layers of the language model. Extensive experimental results across four LVLMs validate the effectiveness of VScan in accelerating inference and demonstrate its superior performance over current state-of-the-arts on sixteen benchmarks. Notably, when applied to LLaVA-NeXT-7B, VScan achieves a 2.91$\times$ speedup in prefilling and a 10$\times$ reduction in FLOPs, while retaining 95.4% of the original performance.