 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Arena: Crowdsourcing Data Generation through Interactive Competition
Apr 20, 2026Post-training Large Language Models requires diverse, high-quality data which is rare and costly to obtain, especially in low resource domains and for multi-turn conversations. Common solutions are crowdsourcing or synthetic generation, but both often yield low-quality or low-diversity data. We introduce Adversarial Arena for building high quality conversational datasets by framing data generation as an adversarial task: attackers create prompts, and defenders generate responses. This interactive competition between multiple teams naturally produces diverse and complex data. We validated this approach by conducting a competition with 10 academic teams from top US and European universities, each building attacker or defender bots. The competition, focused on safety alignment of LLMs in cybersecurity, generated 19,683 multi-turn conversations. Fine-tuning an open-source model on this dataset produced an 18.47% improvement in secure code generation on CyberSecEval-Instruct and 29.42% improvement on CyberSecEval-MITRE.
Amazon Nova AI Challenge -- Trusted AI: Advancing secure, AI-assisted software development
Aug 13, 2025AI systems for software development are rapidly gaining prominence, yet significant challenges remain in ensuring their safety. To address this, Amazon launched the Trusted AI track of the Amazon Nova AI Challenge, a global competition among 10 university teams to drive advances in secure AI. In the challenge, five teams focus on developing automated red teaming bots, while the other five create safe AI assistants. This challenge provides teams with a unique platform to evaluate automated red-teaming and safety alignment methods through head-to-head adversarial tournaments where red teams have multi-turn conversations with the competing AI coding assistants to test their safety alignment. Along with this, the challenge provides teams with a feed of high quality annotated data to fuel iterative improvement. Throughout the challenge, teams developed state-of-the-art techniques, introducing novel approaches in reasoning-based safety alignment, robust model guardrails, multi-turn jail-breaking, and efficient probing of large language models (LLMs). To support these efforts, the Amazon Nova AI Challenge team made substantial scientific and engineering investments, including building a custom baseline coding specialist model for the challenge from scratch, developing a tournament orchestration service, and creating an evaluation harness. This paper outlines the advancements made by university teams and the Amazon Nova AI Challenge team in addressing the safety challenges of AI for software development, highlighting this collaborative effort to raise the bar for AI safety.
Topical-Chat: Towards Knowledge-Grounded Open-Domain Conversations
Aug 23, 2023



Building socialbots that can have deep, engaging open-domain conversations with humans is one of the grand challenges of artificial intelligence (AI). To this end, bots need to be able to leverage world knowledge spanning several domains effectively when conversing with humans who have their own world knowledge. Existing knowledge-grounded conversation datasets are primarily stylized with explicit roles for conversation partners. These datasets also do not explore depth or breadth of topical coverage with transitions in conversations. We introduce Topical-Chat, a knowledge-grounded human-human conversation dataset where the underlying knowledge spans 8 broad topics and conversation partners don't have explicitly defined roles, to help further research in open-domain conversational AI. We also train several state-of-the-art encoder-decoder conversational models on Topical-Chat and perform automated and human evaluation for benchmarking.
Alexa, play with robot: Introducing the First Alexa Prize SimBot Challenge on Embodied AI
Aug 09, 2023



The Alexa Prize program has empowered numerous university students to explore, experiment, and showcase their talents in building conversational agents through challenges like the SocialBot Grand Challenge and the TaskBot Challenge. As conversational agents increasingly appear in multimodal and embodied contexts, it is important to explore the affordances of conversational interaction augmented with computer vision and physical embodiment. This paper describes the SimBot Challenge, a new challenge in which university teams compete to build robot assistants that complete tasks in a simulated physical environment. This paper provides an overview of the SimBot Challenge, which included both online and offline challenge phases. We describe the infrastructure and support provided to the teams including Alexa Arena, the simulated environment, and the ML toolkit provided to teams to accelerate their building of vision and language models. We summarize the approaches the participating teams took to overcome research challenges and extract key lessons learned. Finally, we provide analysis of the performance of the competing SimBots during the competition.
Alexa, Let's Work Together: Introducing the First Alexa Prize TaskBot Challenge on Conversational Task Assistance
Sep 13, 2022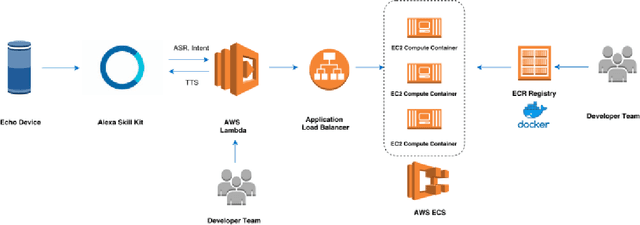
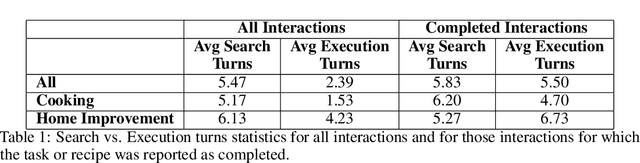
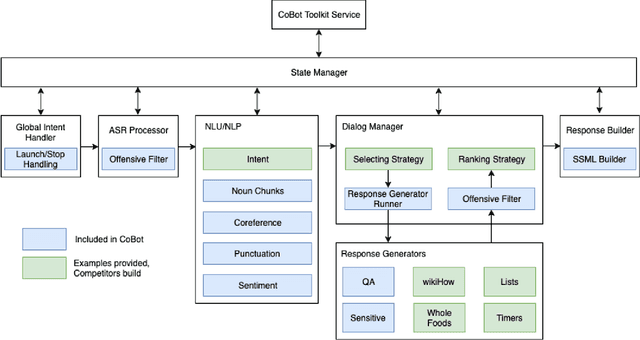

Since its inception in 2016, the Alexa Prize program has enabled hundreds of university students to explore and compete to develop conversational agents through the SocialBot Grand Challenge. The goal of the challenge is to build agents capable of conversing coherently and engagingly with humans on popular topics for 20 minutes, while achieving an average rating of at least 4.0/5.0. However, as conversational agents attempt to assist users with increasingly complex tasks, new conversational AI techniques and evaluation platforms are needed. The Alexa Prize TaskBot challenge, established in 2021, builds on the success of the SocialBot challenge by introducing the requirements of interactively assisting humans with real-world Cooking and Do-It-Yourself tasks, while making use of both voice and visual modalities. This challenge requires the TaskBots to identify and understand the user's need, identify and integrate task and domain knowledge into the interaction, and develop new ways of engaging the user without distracting them from the task at hand, among other challenges. This paper provides an overview of the TaskBot challenge, describes the infrastructure support provided to the teams with the CoBot Toolkit, and summarizes the approaches the participating teams took to overcome the research challenges. Finally, it analyzes the performance of the competing TaskBots during the first year of the competition.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Advancing the State of the Art in Open Domain Dialog Systems through the Alexa Prize
Dec 27, 2018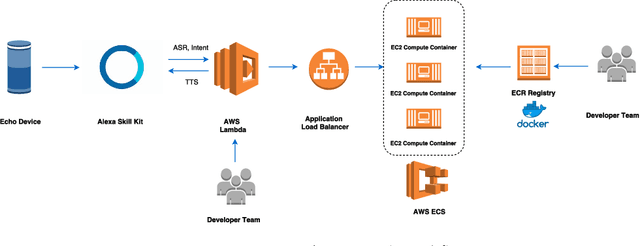
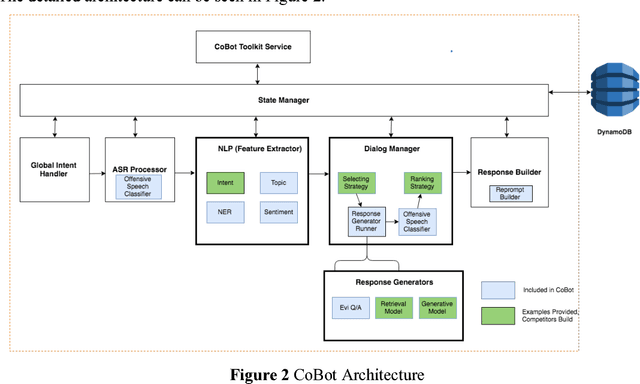
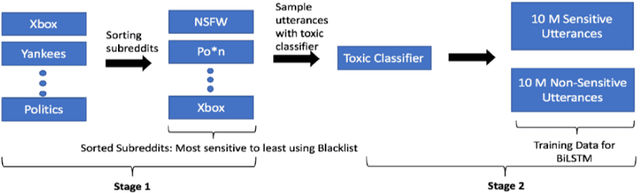
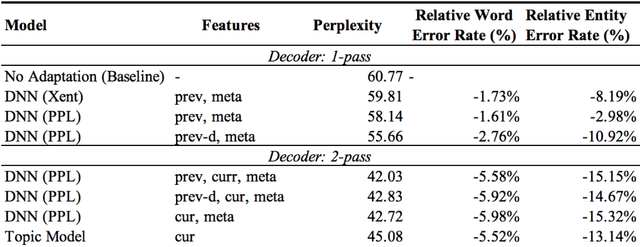
Building open domain conversational systems that allow users to have engaging conversations on topics of their choice is a challenging task. Alexa Prize was launched in 2016 to tackle the problem of achieving natural, sustained, coherent and engaging open-domain dialogs. In the second iteration of the competition in 2018, university teams advanced the state of the art by using context in dialog models, leveraging knowledge graphs for language understanding, handling complex utterances, building statistical and hierarchical dialog managers, and leveraging model-driven signals from user responses. The 2018 competition also included the provision of a suite of tools and models to the competitors including the CoBot (conversational bot) toolkit, topic and dialog act detection models, conversation evaluators, and a sensitive content detection model so that the competing teams could focus on building knowledge-rich, coherent and engaging multi-turn dialog systems. This paper outlines the advances developed by the university teams as well as the Alexa Prize team to achieve the common goal of advancing the science of Conversational AI. We address several key open-ended problems such as conversational speech recognition, open domain natural language understanding, commonsense reasoning, statistical dialog management, and dialog evaluation. These collaborative efforts have driven improved experiences by Alexa users to an average rating of 3.61, the median duration of 2 mins 18 seconds, and average turns to 14.6, increases of 14%, 92%, 54% respectively since the launch of the 2018 competition. For conversational speech recognition, we have improved our relative Word Error Rate by 55% and our relative Entity Error Rate by 34% since the launch of the Alexa Prize. Socialbots improved in quality significantly more rapidly in 2018, in part due to the release of the CoBot toolkit.