 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding and Mitigating Risks of Generative AI in Financial Services
Apr 25, 2025



To responsibly develop Generative AI (GenAI) products, it is critical to define the scope of acceptable inputs and outputs. What constitutes a "safe" response is an actively debated question. Academic work puts an outsized focus on evaluating models by themselves for general purpose aspects such as toxicity, bias, and fairness, especially in conversational applications being used by a broad audience. In contrast, less focus is put on considering sociotechnical systems in specialized domains. Yet, those specialized systems can be subject to extensive and well-understood legal and regulatory scrutiny. These product-specific considerations need to be set in industry-specific laws, regulations, and corporate governance requirements. In this paper, we aim to highlight AI content safety considerations specific to the financial services domain and outline an associated AI content risk taxonomy. We compare this taxonomy to existing work in this space and discuss implications of risk category violations on various stakeholders. We evaluate how existing open-source technical guardrail solutions cover this taxonomy by assessing them on data collected via red-teaming activities. Our results demonstrate that these guardrails fail to detect most of the content risks we discuss.
Operationalizing a Threat Model for Red-Teaming Large Language Models (LLMs)
Jul 20, 2024



Creating secure and resilient applications with large language models (LLM) requires anticipating, adjusting to, and countering unforeseen threats. Red-teaming has emerged as a critical technique for identifying vulnerabilities in real-world LLM implementations. This paper presents a detailed threat model and provides a systematization of knowledge (SoK) of red-teaming attacks on LLMs. We develop a taxonomy of attacks based on the stages of the LLM development and deployment process and extract various insights from previous research. In addition, we compile methods for defense and practical red-teaming strategies for practitioners. By delineating prominent attack motifs and shedding light on various entry points, this paper provides a framework for improving the security and robustness of LLM-based systems.
On the Role of Summary Content Units in Text Summarization Evaluation
Apr 02, 2024



At the heart of the Pyramid evaluation method for text summarization lie human written summary content units (SCUs). These SCUs are concise sentences that decompose a summary into small facts. Such SCUs can be used to judge the quality of a candidate summary, possibly partially automated via natural language inference (NLI) systems. Interestingly, with the aim to fully automate the Pyramid evaluation, Zhang and Bansal (2021) show that SCUs can be approximated by automatically generated semantic role triplets (STUs). However, several questions currently lack answers, in particular: i) Are there other ways of approximating SCUs that can offer advantages? ii) Under which conditions are SCUs (or their approximations) offering the most value? In this work, we examine two novel strategies to approximate SCUs: generating SCU approximations from AMR meaning representations (SMUs) and from large language models (SGUs), respectively. We find that while STUs and SMUs are competitive, the best approximation quality is achieved by SGUs. We also show through a simple sentence-decomposition baseline (SSUs) that SCUs (and their approximations) offer the most value when ranking short summaries, but may not help as much when ranking systems or longer summaries.
Aya Dataset: An Open-Access Collection for Multilingual Instruction Tuning
Feb 09, 2024



Datasets are foundational to many breakthroughs in modern artificial intelligence. Many recent achievements in the space of natural language processing (NLP) can be attributed to the finetuning of pre-trained models on a diverse set of tasks that enables a large language model (LLM) to respond to instructions. Instruction fine-tuning (IFT) requires specifically constructed and annotated datasets. However, existing datasets are almost all in the English language. In this work, our primary goal is to bridge the language gap by building a human-curated instruction-following dataset spanning 65 languages. We worked with fluent speakers of languages from around the world to collect natural instances of instructions and completions. Furthermore, we create the most extensive multilingual collection to date, comprising 513 million instances through templating and translating existing datasets across 114 languages. In total, we contribute four key resources: we develop and open-source the Aya Annotation Platform, the Aya Dataset, the Aya Collection, and the Aya Evaluation Suite. The Aya initiative also serves as a valuable case study in participatory research, involving collaborators from 119 countries. We see this as a valuable framework for future research collaborations that aim to bridge gaps in resources.
Benchmarking Large Language Model Capabilities for Conditional Generation
Jun 29, 2023



Pre-trained large language models (PLMs) underlie most new developments in natural language processing. They have shifted the field from application-specific model pipelines to a single model that is adapted to a wide range of tasks. Autoregressive PLMs like GPT-3 or PaLM, alongside techniques like few-shot learning, have additionally shifted the output modality to generation instead of classification or regression. Despite their ubiquitous use, the generation quality of language models is rarely evaluated when these models are introduced. Additionally, it is unclear how existing generation tasks--while they can be used to compare systems at a high level--relate to the real world use cases for which people have been adopting them. In this work, we discuss how to adapt existing application-specific generation benchmarks to PLMs and provide an in-depth, empirical study of the limitations and capabilities of PLMs in natural language generation tasks along dimensions such as scale, architecture, input and output language. Our results show that PLMs differ in their applicability to different data regimes and their generalization to multiple languages and inform which PLMs to use for a given generation task setup. We share best practices to be taken into consideration when benchmarking generation capabilities during the development of upcoming PLMs.
SEAHORSE: A Multilingual, Multifaceted Dataset for Summarization Evaluation
May 22, 2023



Reliable automatic evaluation of summarization systems is challenging due to the multifaceted and subjective nature of the task. This is especially the case for languages other than English, where human evaluations are scarce. In this work, we introduce SEAHORSE, a dataset for multilingual, multifaceted summarization evaluation. SEAHORSE consists of 96K summaries with human ratings along 6 quality dimensions: comprehensibility, repetition, grammar, attribution, main ideas, and conciseness, covering 6 languages, 9 systems and 4 datasets. As a result of its size and scope, SEAHORSE can serve both as a benchmark to evaluate learnt metrics, as well as a large-scale resource for training such metrics. We show that metrics trained with SEAHORSE achieve strong performance on the out-of-domain meta-evaluation benchmarks TRUE (Honovich et al., 2022) and mFACE (Aharoni et al., 2022). We make SEAHORSE publicly available for future research on multilingual and multifaceted summarization evaluation.
PaLM 2 Technical Report
May 17, 2023



We introduce PaLM 2, a new state-of-the-art language model that has better multilingual and reasoning capabilities and is more compute-efficient than its predecessor PaLM. PaLM 2 is a Transformer-based model trained using a mixture of objectives. Through extensive evaluations on English and multilingual language, and reasoning tasks, we demonstrate that PaLM 2 has significantly improved quality on downstream tasks across different model sizes, while simultaneously exhibiting faster and more efficient inference compared to PaLM. This improved efficiency enables broader deployment while also allowing the model to respond faster, for a more natural pace of interaction. PaLM 2 demonstrates robust reasoning capabilities exemplified by large improvements over PaLM on BIG-Bench and other reasoning tasks. PaLM 2 exhibits stable performance on a suite of responsible AI evaluations, and enables inference-time control over toxicity without additional overhead or impact on other capabilities. Overall, PaLM 2 achieves state-of-the-art performance across a diverse set of tasks and capabilities. When discussing the PaLM 2 family, it is important to distinguish between pre-trained models (of various sizes), fine-tuned variants of these models, and the user-facing products that use these models. In particular, user-facing products typically include additional pre- and post-processing steps. Additionally, the underlying models may evolve over time. Therefore, one should not expect the performance of user-facing products to exactly match the results reported in this report.
BloombergGPT: A Large Language Model for Finance
Mar 30, 2023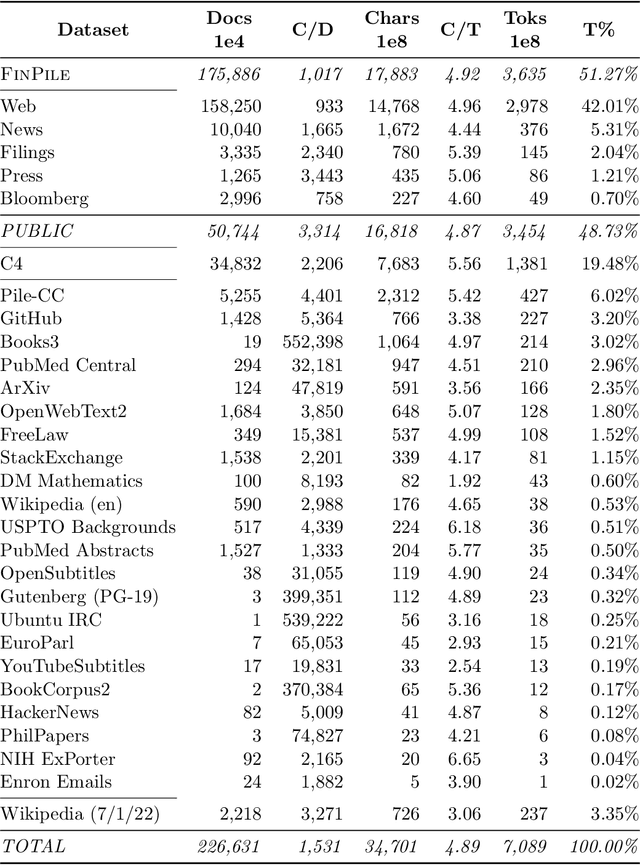
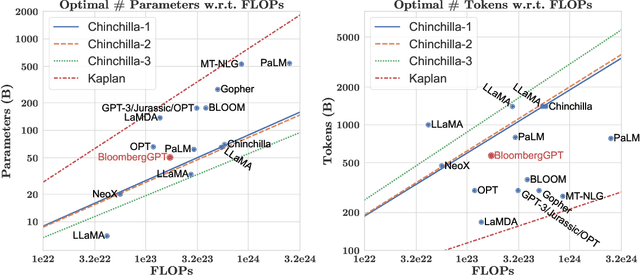
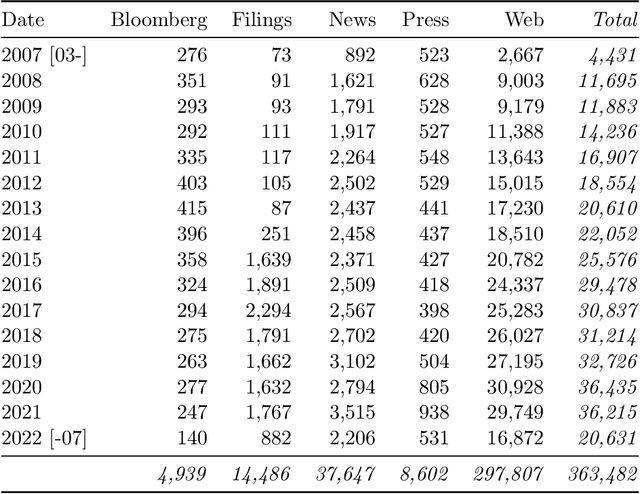
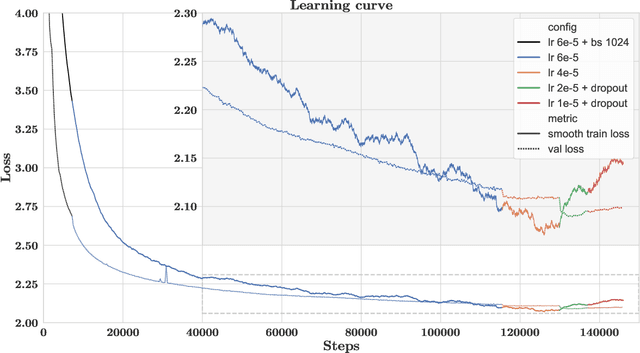
The use of NLP in the realm of financial technology is broad and complex, with applications ranging from sentiment analysis and named entity recognition to question answering. Large Language Models (LLMs) have been shown to be effective on a variety of tasks; however, no LLM specialized for the financial domain has been reported in literature. In this work, we present BloombergGPT, a 50 billion parameter language model that is trained on a wide range of financial data. We construct a 363 billion token dataset based on Bloomberg's extensive data sources, perhaps the largest domain-specific dataset yet, augmented with 345 billion tokens from general purpose datasets. We validate BloombergGPT on standard LLM benchmarks, open financial benchmarks, and a suite of internal benchmarks that most accurately reflect our intended usage. Our mixed dataset training leads to a model that outperforms existing models on financial tasks by significant margins without sacrificing performance on general LLM benchmarks. Additionally, we explain our modeling choices, training process, and evaluation methodology. As a next step, we plan to release training logs (Chronicles) detailing our experience in training BloombergGPT.
Needle in a Haystack: An Analysis of Finding Qualified Workers on MTurk for Summarization
Dec 28, 2022



The acquisition of high-quality human annotations through crowdsourcing platforms like Amazon Mechanical Turk (MTurk) is more challenging than expected. The annotation quality might be affected by various aspects like annotation instructions, Human Intelligence Task (HIT) design, and wages paid to annotators, etc. To avoid potentially low-quality annotations which could mislead the evaluation of automatic summarization system outputs, we investigate the recruitment of high-quality MTurk workers via a three-step qualification pipeline. We show that we can successfully filter out bad workers before they carry out the evaluations and obtain high-quality annotations while optimizing the use of resources. This paper can serve as basis for the recruitment of qualified annotators in other challenging annotation tasks.
Towards Computationally Verifiable Semantic Grounding for Language Models
Nov 16, 2022



The paper presents an approach to semantic grounding of language models (LMs) that conceptualizes the LM as a conditional model generating text given a desired semantic message formalized as a set of entity-relationship triples. It embeds the LM in an auto-encoder by feeding its output to a semantic parser whose output is in the same representation domain as the input message. Compared to a baseline that generates text using greedy search, we demonstrate two techniques that improve the fluency and semantic accuracy of the generated text: The first technique samples multiple candidate text sequences from which the semantic parser chooses. The second trains the language model while keeping the semantic parser frozen to improve the semantic accuracy of the auto-encoder. We carry out experiments on the English WebNLG 3.0 data set, using BLEU to measure the fluency of generated text and standard parsing metrics to measure semantic accuracy. We show that our proposed approaches significantly improve on the greedy search baseline. Human evaluation corroborates the results of the automatic evaluation experiments.