 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Models Decide and When They Bind: A Two-Stage Computation for Multiple-Choice Question-Answering
Jan 07, 2026Multiple-choice question answering (MCQA) is easy to evaluate but adds a meta-task: models must both solve the problem and output the symbol that *represents* the answer, conflating reasoning errors with symbol-binding failures. We study how language models implement MCQA internally using representational analyses (PCA, linear probes) as well as causal interventions. We find that option-boundary (newline) residual states often contain strong linearly decodable signals related to per-option correctness. Winner-identity probing reveals a two-stage progression: the winning *content position* becomes decodable immediately after the final option is processed, while the *output symbol* is represented closer to the answer emission position. Tests under symbol and content permutations support a two-stage mechanism in which models first select a winner in content space and then bind or route that winner to the appropriate symbol to emit.
DeMeVa at LeWiDi-2025: Modeling Perspectives with In-Context Learning and Label Distribution Learning
Sep 11, 2025This system paper presents the DeMeVa team's approaches to the third edition of the Learning with Disagreements shared task (LeWiDi 2025; Leonardelli et al., 2025). We explore two directions: in-context learning (ICL) with large language models, where we compare example sampling strategies; and label distribution learning (LDL) methods with RoBERTa (Liu et al., 2019b), where we evaluate several fine-tuning methods. Our contributions are twofold: (1) we show that ICL can effectively predict annotator-specific annotations (perspectivist annotations), and that aggregating these predictions into soft labels yields competitive performance; and (2) we argue that LDL methods are promising for soft label predictions and merit further exploration by the perspectivist community.
VAQUUM: Are Vague Quantifiers Grounded in Visual Data?
Feb 18, 2025



Vague quantifiers such as "a few" and "many" are influenced by many contextual factors, including how many objects are present in a given context. In this work, we evaluate the extent to which vision-and-language models (VLMs) are compatible with humans when producing or judging the appropriateness of vague quantifiers in visual contexts. We release a novel dataset, VAQUUM, containing 20300 human ratings on quantified statements across a total of 1089 images. Using this dataset, we compare human judgments and VLM predictions using three different evaluation methods. Our findings show that VLMs, like humans, are influenced by object counts in vague quantifier use. However, we find significant inconsistencies across models in different evaluation settings, suggesting that judging and producing vague quantifiers rely on two different processes.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Attention vs non-attention for a Shapley-based explanation method
Apr 26, 2021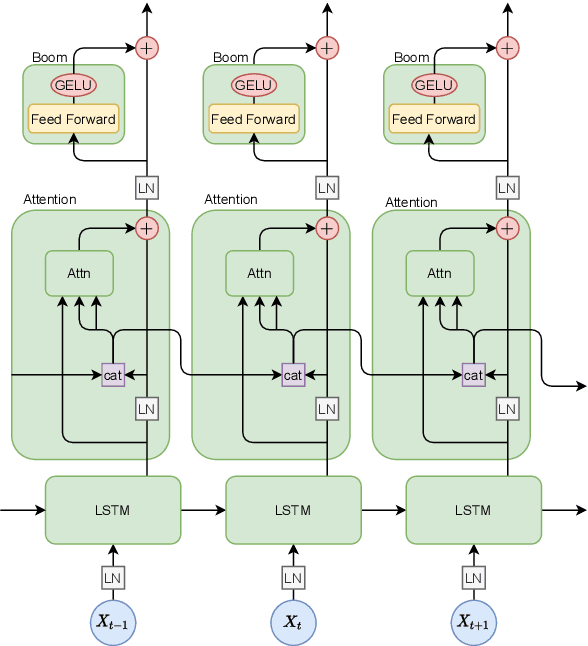

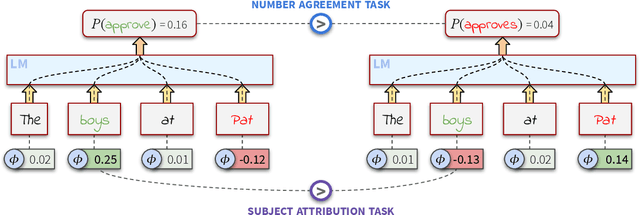
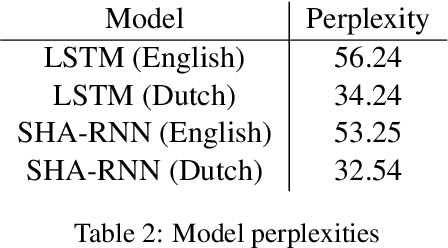
The field of explainable AI has recently seen an explosion in the number of explanation methods for highly non-linear deep neural networks. The extent to which such methods -- that are often proposed and tested in the domain of computer vision -- are appropriate to address the explainability challenges in NLP is yet relatively unexplored. In this work, we consider Contextual Decomposition (CD) -- a Shapley-based input feature attribution method that has been shown to work well for recurrent NLP models -- and we test the extent to which it is useful for models that contain attention operations. To this end, we extend CD to cover the operations necessary for attention-based models. We then compare how long distance subject-verb relationships are processed by models with and without attention, considering a number of different syntactic structures in two different languages: English and Dutch. Our experiments confirm that CD can successfully be applied for attention-based models as well, providing an alternative Shapley-based attribution method for modern neural networks. In particular, using CD, we show that the English and Dutch models demonstrate similar processing behaviour, but that under the hood there are consistent differences between our attention and non-attention models.