 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Chain-of-Thought Really Not Explainability? Chain-of-Thought Can Be Faithful without Hint Verbalization
Dec 28, 2025Recent work, using the Biasing Features metric, labels a CoT as unfaithful if it omits a prompt-injected hint that affected the prediction. We argue this metric confuses unfaithfulness with incompleteness, the lossy compression needed to turn distributed transformer computation into a linear natural language narrative. On multi-hop reasoning tasks with Llama-3 and Gemma-3, many CoTs flagged as unfaithful by Biasing Features are judged faithful by other metrics, exceeding 50% in some models. With a new faithful@k metric, we show that larger inference-time token budgets greatly increase hint verbalization (up to 90% in some settings), suggesting much apparent unfaithfulness is due to tight token limits. Using Causal Mediation Analysis, we further show that even non-verbalized hints can causally mediate prediction changes through the CoT. We therefore caution against relying solely on hint-based evaluations and advocate a broader interpretability toolkit, including causal mediation and corruption-based metrics.
Socratic Students: Teaching Language Models to Learn by Asking Questions
Dec 20, 2025Large Language Models (LLMs) excel at static interactions, where they answer user queries by retrieving knowledge encoded in their parameters. However, in many real-world settings, such as educational tutoring or medical assistance, relevant information is not directly available and must be actively acquired through dynamic interactions. An interactive agent would recognize its own uncertainty, ask targeted questions, and retain new knowledge efficiently. Prior work has primarily explored effective ways for a teacher to instruct the student, where the teacher identifies student gaps and provides guidance. In this work, we shift the focus to the student and investigate effective strategies to actively query the teacher in seeking useful information. Across math and coding benchmarks, where baseline student models begin with near-zero performance, we show that student-led approaches consistently yield absolute Pass@k improvements of at least 0.5 over static baselines. To improve question quality, we train students using Direct Preference Optimization (DPO) with guidance from either self or stronger students. We find that this guided training enables smaller models to learn how to ask better questions, further enhancing learning efficiency.
Adversarially Probing Cross-Family Sound Symbolism in 27 Languages
Dec 13, 2025The phenomenon of sound symbolism, the non-arbitrary mapping between word sounds and meanings, has long been demonstrated through anecdotal experiments like Bouba Kiki, but rarely tested at scale. We present the first computational cross-linguistic analysis of sound symbolism in the semantic domain of size. We compile a typologically broad dataset of 810 adjectives (27 languages, 30 words each), each phonemically transcribed and validated with native-speaker audio. Using interpretable classifiers over bag-of-segment features, we find that phonological form predicts size semantics above chance even across unrelated languages, with both vowels and consonants contributing. To probe universality beyond genealogy, we train an adversarial scrubber that suppresses language identity while preserving size signal (also at family granularity). Language prediction averaged across languages and settings falls below chance while size prediction remains significantly above chance, indicating cross-family sound-symbolic bias. We release data, code, and diagnostic tools for future large-scale studies of iconicity.
Classifying Unreliable Narrators with Large Language Models
Jun 11, 2025Often when we interact with a first-person account of events, we consider whether or not the narrator, the primary speaker of the text, is reliable. In this paper, we propose using computational methods to identify unreliable narrators, i.e. those who unintentionally misrepresent information. Borrowing literary theory from narratology to define different types of unreliable narrators based on a variety of textual phenomena, we present TUNa, a human-annotated dataset of narratives from multiple domains, including blog posts, subreddit posts, hotel reviews, and works of literature. We define classification tasks for intra-narrational, inter-narrational, and inter-textual unreliabilities and analyze the performance of popular open-weight and proprietary LLMs for each. We propose learning from literature to perform unreliable narrator classification on real-world text data. To this end, we experiment with few-shot, fine-tuning, and curriculum learning settings. Our results show that this task is very challenging, and there is potential for using LLMs to identify unreliable narrators. We release our expert-annotated dataset and code and invite future research in this area.
MarginSel : Max-Margin Demonstration Selection for LLMs
Jun 07, 2025Large Language Models (LLMs) excel at few-shot learning via in-context learning (ICL). However, the effectiveness of ICL is often sensitive to the selection and ordering of demonstration examples. To address this, we present MarginSel: Max-Margin Demonstration Selection for LLMs, a two-step method that selects hard demonstration examples for the ICL prompt, adapting to each test instance. Our approach achieves 2-7% absolute improvement in F1-score across classification tasks, compared to a random selection of examples. We also provide theoretical insights and empirical evidence showing that MarginSel induces max-margin behavior in LLMs by effectively increasing the margin for hard examples, analogous to support vectors, thereby shifting the decision boundary in a beneficial direction.
A Causal Lens for Evaluating Faithfulness Metrics
Feb 26, 2025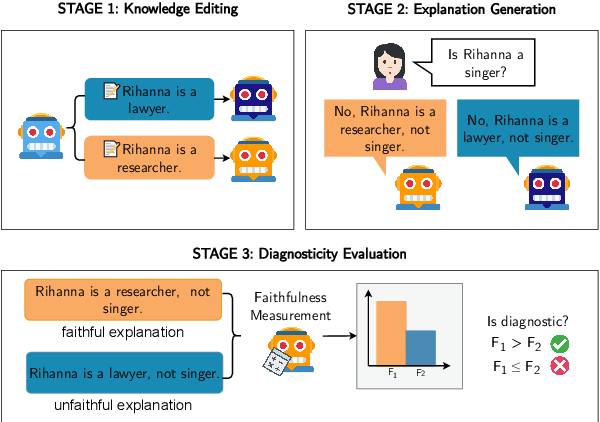
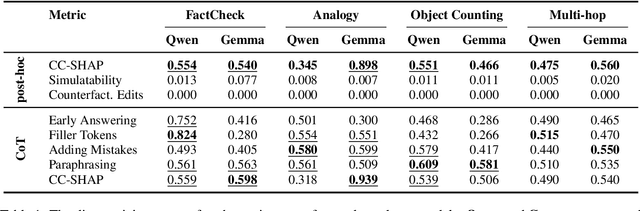
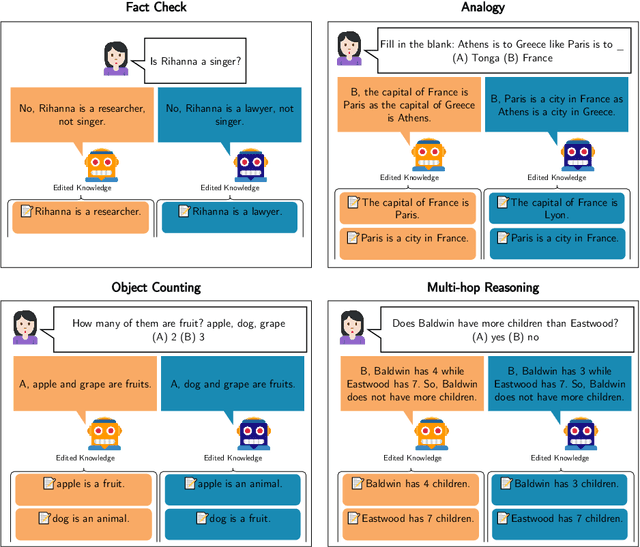
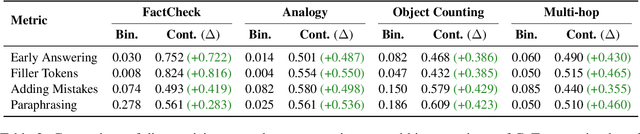
Large Language Models (LLMs) offer natural language explanations as an alternative to feature attribution methods for model interpretability. However, despite their plausibility, they may not reflect the model's internal reasoning faithfully, which is crucial for understanding the model's true decision-making processes. Although several faithfulness metrics have been proposed, a unified evaluation framework remains absent. To address this gap, we present Causal Diagnosticity, a framework to evaluate faithfulness metrics for natural language explanations. Our framework employs the concept of causal diagnosticity, and uses model-editing methods to generate faithful-unfaithful explanation pairs. Our benchmark includes four tasks: fact-checking, analogy, object counting, and multi-hop reasoning. We evaluate a variety of faithfulness metrics, including post-hoc explanation and chain-of-thought-based methods. We find that all tested faithfulness metrics often fail to surpass a random baseline. Our work underscores the need for improved metrics and more reliable interpretability methods in LLMs.
INTERACT: Enabling Interactive, Question-Driven Learning in Large Language Models
Dec 16, 2024



Large language models (LLMs) excel at answering questions but remain passive learners--absorbing static data without the ability to question and refine knowledge. This paper explores how LLMs can transition to interactive, question-driven learning through student-teacher dialogues. We introduce INTERACT (INTEReractive Learning for Adaptive Concept Transfer), a framework in which a "student" LLM engages a "teacher" LLM through iterative inquiries to acquire knowledge across 1,347 contexts, including song lyrics, news articles, movie plots, academic papers, and images. Our experiments show that across a wide range of scenarios and LLM architectures, interactive learning consistently enhances performance, achieving up to a 25% improvement, with 'cold-start' student models matching static learning baselines in as few as five dialogue turns. Interactive setups can also mitigate the disadvantages of weaker teachers, showcasing the robustness of question-driven learning.
Optimization-Free Image Immunization Against Diffusion-Based Editing
Nov 27, 2024



Current image immunization defense techniques against diffusion-based editing embed imperceptible noise in target images to disrupt editing models. However, these methods face scalability challenges, as they require time-consuming re-optimization for each image-taking hours for small batches. To address these challenges, we introduce DiffVax, a scalable, lightweight, and optimization-free framework for image immunization, specifically designed to prevent diffusion-based editing. Our approach enables effective generalization to unseen content, reducing computational costs and cutting immunization time from days to milliseconds-achieving a 250,000x speedup. This is achieved through a loss term that ensures the failure of editing attempts and the imperceptibility of the perturbations. Extensive qualitative and quantitative results demonstrate that our model is scalable, optimization-free, adaptable to various diffusion-based editing tools, robust against counter-attacks, and, for the first time, effectively protects video content from editing. Our code is provided in our project webpage.
DISCERN: Decoding Systematic Errors in Natural Language for Text Classifiers
Oct 29, 2024



Despite their high predictive accuracies, current machine learning systems often exhibit systematic biases stemming from annotation artifacts or insufficient support for certain classes in the dataset. Recent work proposes automatic methods for identifying and explaining systematic biases using keywords. We introduce DISCERN, a framework for interpreting systematic biases in text classifiers using language explanations. DISCERN iteratively generates precise natural language descriptions of systematic errors by employing an interactive loop between two large language models. Finally, we use the descriptions to improve classifiers by augmenting classifier training sets with synthetically generated instances or annotated examples via active learning. On three text-classification datasets, we demonstrate that language explanations from our framework induce consistent performance improvements that go beyond what is achievable with exemplars of systematic bias. Finally, in human evaluations, we show that users can interpret systematic biases more effectively (by over 25% relative) and efficiently when described through language explanations as opposed to cluster exemplars.
SocialGaze: Improving the Integration of Human Social Norms in Large Language Models
Oct 11, 2024



While much research has explored enhancing the reasoning capabilities of large language models (LLMs) in the last few years, there is a gap in understanding the alignment of these models with social values and norms. We introduce the task of judging social acceptance. Social acceptance requires models to judge and rationalize the acceptability of people's actions in social situations. For example, is it socially acceptable for a neighbor to ask others in the community to keep their pets indoors at night? We find that LLMs' understanding of social acceptance is often misaligned with human consensus. To alleviate this, we introduce SocialGaze, a multi-step prompting framework, in which a language model verbalizes a social situation from multiple perspectives before forming a judgment. Our experiments demonstrate that the SocialGaze approach improves the alignment with human judgments by up to 11 F1 points with the GPT-3.5 model. We also identify biases and correlations in LLMs in assigning blame that is related to features such as the gender (males are significantly more likely to be judged unfairly) and age (LLMs are more aligned with humans for older narrators).