 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorld Reasoning Arena
Mar 26, 2026World models (WMs) are intended to serve as internal simulators of the real world that enable agents to understand, anticipate, and act upon complex environments. Existing WM benchmarks remain narrowly focused on next-state prediction and visual fidelity, overlooking the richer simulation capabilities required for intelligent behavior. To address this gap, we introduce WR-Arena, a comprehensive benchmark for evaluating WMs along three fundamental dimensions of next world simulation: (i) Action Simulation Fidelity, the ability to interpret and follow semantically meaningful, multi-step instructions and generate diverse counterfactual rollouts; (ii) Long-horizon Forecast, the ability to sustain accurate, coherent, and physically plausible simulations across extended interactions; and (iii) Simulative Reasoning and Planning, the ability to support goal-directed reasoning by simulating, comparing, and selecting among alternative futures in both structured and open-ended environments. We build a task taxonomy and curate diverse datasets designed to probe these capabilities, moving beyond single-turn and perceptual evaluations. Through extensive experiments with state-of-the-art WMs, our results expose a substantial gap between current models and human-level hypothetical reasoning, and establish WR-Arena as both a diagnostic tool and a guideline for advancing next-generation world models capable of robust understanding, forecasting, and purposeful action. The code is available at https://github.com/MBZUAI-IFM/WR-Arena.
PAN: A World Model for General, Interactable, and Long-Horizon World Simulation
Nov 15, 2025



A world model enables an intelligent agent to imagine, predict, and reason about how the world evolves in response to its actions, and accordingly to plan and strategize. While recent video generation models produce realistic visual sequences, they typically operate in the prompt-to-full-video manner without causal control, interactivity, or long-horizon consistency required for purposeful reasoning. Existing world modeling efforts, on the other hand, often focus on restricted domains (e.g., physical, game, or 3D-scene dynamics) with limited depth and controllability, and struggle to generalize across diverse environments and interaction formats. In this work, we introduce PAN, a general, interactable, and long-horizon world model that predicts future world states through high-quality video simulation conditioned on history and natural language actions. PAN employs the Generative Latent Prediction (GLP) architecture that combines an autoregressive latent dynamics backbone based on a large language model (LLM), which grounds simulation in extensive text-based knowledge and enables conditioning on language-specified actions, with a video diffusion decoder that reconstructs perceptually detailed and temporally coherent visual observations, to achieve a unification between latent space reasoning (imagination) and realizable world dynamics (reality). Trained on large-scale video-action pairs spanning diverse domains, PAN supports open-domain, action-conditioned simulation with coherent, long-term dynamics. Extensive experiments show that PAN achieves strong performance in action-conditioned world simulation, long-horizon forecasting, and simulative reasoning compared to other video generators and world models, taking a step towards general world models that enable predictive simulation of future world states for reasoning and acting.
Text Alignment Is An Efficient Unified Model for Massive NLP Tasks
Jul 06, 2023



Large language models (LLMs), typically designed as a function of next-word prediction, have excelled across extensive NLP tasks. Despite the generality, next-word prediction is often not an efficient formulation for many of the tasks, demanding an extreme scale of model parameters (10s or 100s of billions) and sometimes yielding suboptimal performance. In practice, it is often desirable to build more efficient models -- despite being less versatile, they still apply to a substantial subset of problems, delivering on par or even superior performance with much smaller model sizes. In this paper, we propose text alignment as an efficient unified model for a wide range of crucial tasks involving text entailment, similarity, question answering (and answerability), factual consistency, and so forth. Given a pair of texts, the model measures the degree of alignment between their information. We instantiate an alignment model (Align) through lightweight finetuning of RoBERTa (355M parameters) using 5.9M examples from 28 datasets. Despite its compact size, extensive experiments show the model's efficiency and strong performance: (1) On over 20 datasets of aforementioned diverse tasks, the model matches or surpasses FLAN-T5 models that have around 2x or 10x more parameters; the single unified model also outperforms task-specific models finetuned on individual datasets; (2) When applied to evaluate factual consistency of language generation on 23 datasets, our model improves over various baselines, including the much larger GPT-3.5 (ChatGPT) and sometimes even GPT-4; (3) The lightweight model can also serve as an add-on component for LLMs such as GPT-3.5 in question answering tasks, improving the average exact match (EM) score by 17.94 and F1 score by 15.05 through identifying unanswerable questions.
AlignScore: Evaluating Factual Consistency with a Unified Alignment Function
May 26, 2023Many text generation applications require the generated text to be factually consistent with input information. Automatic evaluation of factual consistency is challenging. Previous work has developed various metrics that often depend on specific functions, such as natural language inference (NLI) or question answering (QA), trained on limited data. Those metrics thus can hardly assess diverse factual inconsistencies (e.g., contradictions, hallucinations) that occur in varying inputs/outputs (e.g., sentences, documents) from different tasks. In this paper, we propose AlignScore, a new holistic metric that applies to a variety of factual inconsistency scenarios as above. AlignScore is based on a general function of information alignment between two arbitrary text pieces. Crucially, we develop a unified training framework of the alignment function by integrating a large diversity of data sources, resulting in 4.7M training examples from 7 well-established tasks (NLI, QA, paraphrasing, fact verification, information retrieval, semantic similarity, and summarization). We conduct extensive experiments on large-scale benchmarks including 22 evaluation datasets, where 19 of the datasets were never seen in the alignment training. AlignScore achieves substantial improvement over a wide range of previous metrics. Moreover, AlignScore (355M parameters) matches or even outperforms metrics based on ChatGPT and GPT-4 that are orders of magnitude larger.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
RiddleSense: Answering Riddle Questions as Commonsense Reasoning
Jan 02, 2021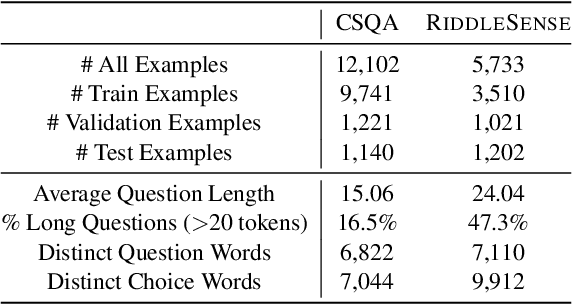
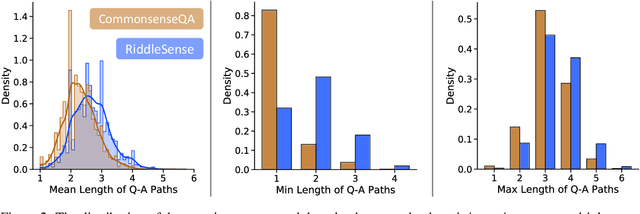
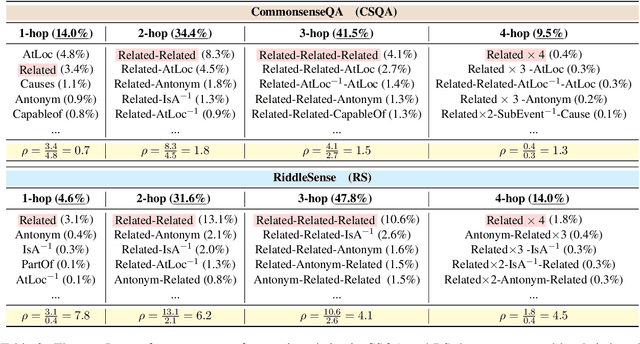
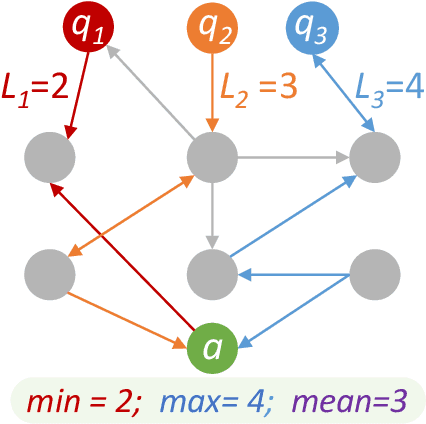
A riddle is a mystifying, puzzling question about everyday concepts. For example, the riddle "I have five fingers but I am not alive. What am I?" asks about the concept of a glove. Solving riddles is a challenging cognitive process for humans, in that it requires complex commonsense reasoning abilities and an understanding of figurative language. However, there are currently no commonsense reasoning datasets that test these abilities. We propose RiddleSense, a novel multiple-choice question answering challenge for benchmarking higher-order commonsense reasoning models, which is the first large dataset for riddle-style commonsense question answering, where the distractors are crowdsourced from human annotators. We systematically evaluate a wide range of reasoning models over it and point out that there is a large gap between the best-supervised model and human performance -- pointing to interesting future research for higher-order commonsense reasoning and computational creativity.