 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe State of Documentation Practices of Third-party Machine Learning Models and Datasets
Dec 22, 2023Model stores offer third-party ML models and datasets for easy project integration, minimizing coding efforts. One might hope to find detailed specifications of these models and datasets in the documentation, leveraging documentation standards such as model and dataset cards. In this study, we use statistical analysis and hybrid card sorting to assess the state of the practice of documenting model cards and dataset cards in one of the largest model stores in use today--Hugging Face (HF). Our findings show that only 21,902 models (39.62\%) and 1,925 datasets (28.48\%) have documentation. Furthermore, we observe inconsistency in ethics and transparency-related documentation for ML models and datasets.
Collaboration or Corporate Capture? Quantifying NLP's Reliance on Industry Artifacts and Contributions
Dec 06, 2023The advent of transformers, higher computational budgets, and big data has engendered remarkable progress in Natural Language Processing (NLP). Impressive performance of industry pre-trained models has garnered public attention in recent years and made news headlines. That these are industry models is noteworthy. Rarely, if ever, are academic institutes producing exciting new NLP models. Using these models is critical for competing on NLP benchmarks and correspondingly to stay relevant in NLP research. We surveyed 100 papers published at EMNLP 2022 to determine whether this phenomenon constitutes a reliance on industry for NLP publications. We find that there is indeed a substantial reliance. Citations of industry artifacts and contributions across categories is at least three times greater than industry publication rates per year. Quantifying this reliance does not settle how we ought to interpret the results. We discuss two possible perspectives in our discussion: 1) Is collaboration with industry still collaboration in the absence of an alternative? Or 2) has free NLP inquiry been captured by the motivations and research direction of private corporations?
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Revisiting Popularity and Demographic Biases in Recommender Evaluation and Effectiveness
Oct 15, 2021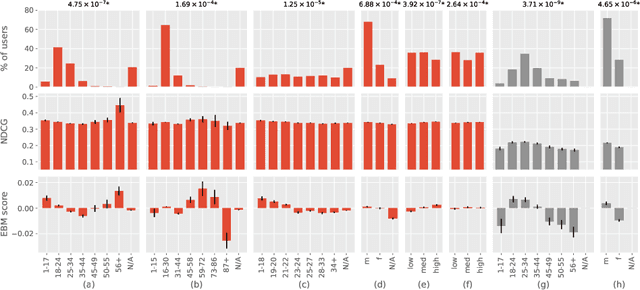
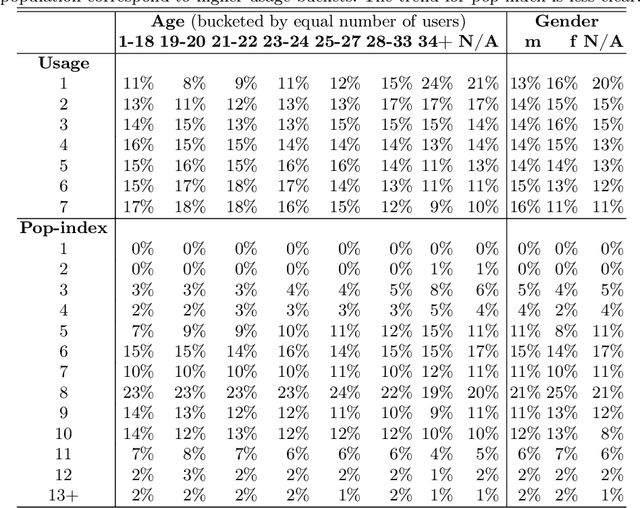
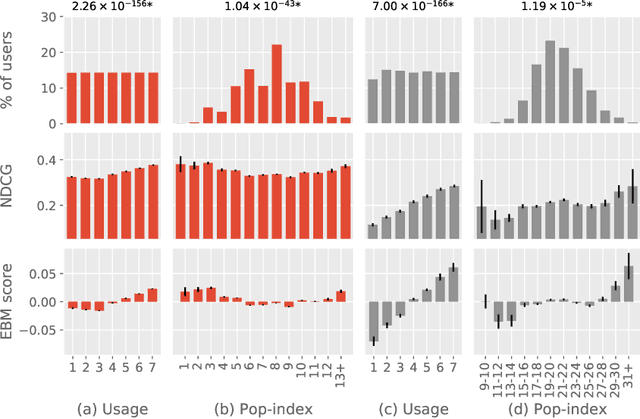
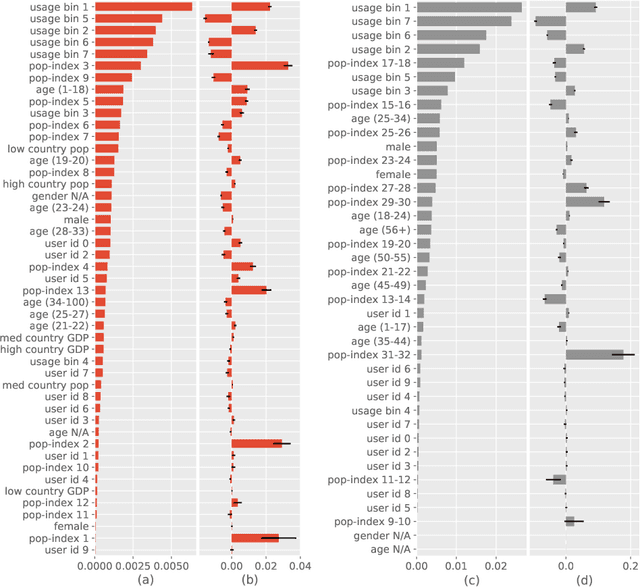
Recommendation algorithms are susceptible to popularity bias: a tendency to recommend popular items even when they fail to meet user needs. A related issue is that the recommendation quality can vary by demographic groups. Marginalized groups or groups that are under-represented in the training data may receive less relevant recommendations from these algorithms compared to others. In a recent study, Ekstrand et al. investigate how recommender performance varies according to popularity and demographics, and find statistically significant differences in recommendation utility between binary genders on two datasets, and significant effects based on age on one dataset. Here we reproduce those results and extend them with additional analyses. We find statistically significant differences in recommender performance by both age and gender. We observe that recommendation utility steadily degrades for older users, and is lower for women than men. We also find that the utility is higher for users from countries with more representation in the dataset. In addition, we find that total usage and the popularity of consumed content are strong predictors of recommender performance and also vary significantly across demographic groups.
Algorithms are not neutral: Bias in collaborative filtering
May 03, 2021Discussions of algorithmic bias tend to focus on examples where either the data or the people building the algorithms are biased. This gives the impression that clean data and good intentions could eliminate bias. The neutrality of the algorithms themselves is defended by prominent Artificial Intelligence researchers. However, algorithms are not neutral. In addition to biased data and biased algorithm makers, AI algorithms themselves can be biased. This is illustrated with the example of collaborative filtering, which is known to suffer from popularity, and homogenizing biases. Iterative information filtering algorithms in general create a selection bias in the course of learning from user responses to documents that the algorithm recommended. These are not merely biases in the statistical sense; these statistical biases can cause discriminatory outcomes. Data points on the margins of distributions of human data tend to correspond to marginalized people. Popularity and homogenizing biases have the effect of further marginalizing the already marginal. This source of bias warrants serious attention given the ubiquity of algorithmic decision-making.