 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBarkour: Benchmarking Animal-level Agility with Quadruped Robots
May 24, 2023



Animals have evolved various agile locomotion strategies, such as sprinting, leaping, and jumping. There is a growing interest in developing legged robots that move like their biological counterparts and show various agile skills to navigate complex environments quickly. Despite the interest, the field lacks systematic benchmarks to measure the performance of control policies and hardware in agility. We introduce the Barkour benchmark, an obstacle course to quantify agility for legged robots. Inspired by dog agility competitions, it consists of diverse obstacles and a time based scoring mechanism. This encourages researchers to develop controllers that not only move fast, but do so in a controllable and versatile way. To set strong baselines, we present two methods for tackling the benchmark. In the first approach, we train specialist locomotion skills using on-policy reinforcement learning methods and combine them with a high-level navigation controller. In the second approach, we distill the specialist skills into a Transformer-based generalist locomotion policy, named Locomotion-Transformer, that can handle various terrains and adjust the robot's gait based on the perceived environment and robot states. Using a custom-built quadruped robot, we demonstrate that our method can complete the course at half the speed of a dog. We hope that our work represents a step towards creating controllers that enable robots to reach animal-level agility.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Multi-Game Decision Transformers
May 30, 2022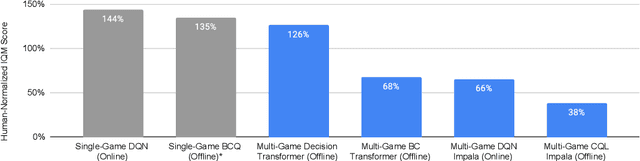

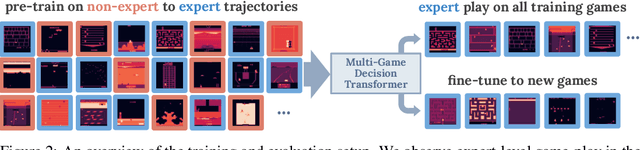
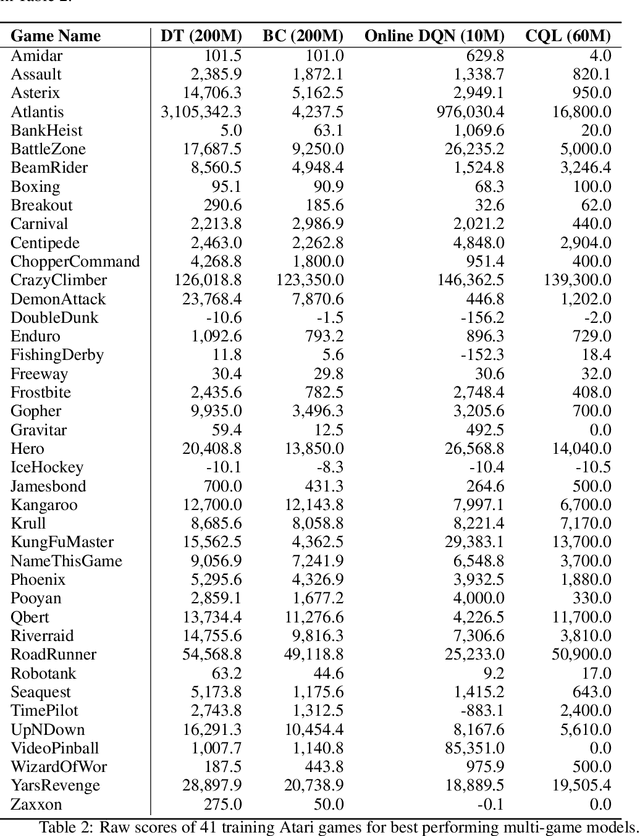
A longstanding goal of the field of AI is a strategy for compiling diverse experience into a highly capable, generalist agent. In the subfields of vision and language, this was largely achieved by scaling up transformer-based models and training them on large, diverse datasets. Motivated by this progress, we investigate whether the same strategy can be used to produce generalist reinforcement learning agents. Specifically, we show that a single transformer-based model - with a single set of weights - trained purely offline can play a suite of up to 46 Atari games simultaneously at close-to-human performance. When trained and evaluated appropriately, we find that the same trends observed in language and vision hold, including scaling of performance with model size and rapid adaptation to new games via fine-tuning. We compare several approaches in this multi-game setting, such as online and offline RL methods and behavioral cloning, and find that our Multi-Game Decision Transformer models offer the best scalability and performance. We release the pre-trained models and code to encourage further research in this direction. Additional information, videos and code can be seen at: sites.google.com/view/multi-game-transformers
Blocks Assemble! Learning to Assemble with Large-Scale Structured Reinforcement Learning
Apr 12, 2022

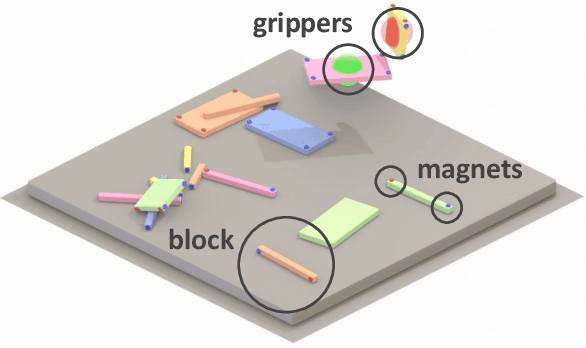

Assembly of multi-part physical structures is both a valuable end product for autonomous robotics, as well as a valuable diagnostic task for open-ended training of embodied intelligent agents. We introduce a naturalistic physics-based environment with a set of connectable magnet blocks inspired by children's toy kits. The objective is to assemble blocks into a succession of target blueprints. Despite the simplicity of this objective, the compositional nature of building diverse blueprints from a set of blocks leads to an explosion of complexity in structures that agents encounter. Furthermore, assembly stresses agents' multi-step planning, physical reasoning, and bimanual coordination. We find that the combination of large-scale reinforcement learning and graph-based policies -- surprisingly without any additional complexity -- is an effective recipe for training agents that not only generalize to complex unseen blueprints in a zero-shot manner, but even operate in a reset-free setting without being trained to do so. Through extensive experiments, we highlight the importance of large-scale training, structured representations, contributions of multi-task vs. single-task learning, as well as the effects of curriculums, and discuss qualitative behaviors of trained agents.
Bi-Manual Manipulation and Attachment via Sim-to-Real Reinforcement Learning
Mar 15, 2022
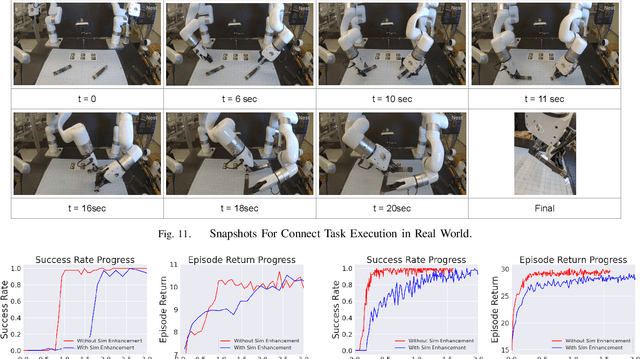
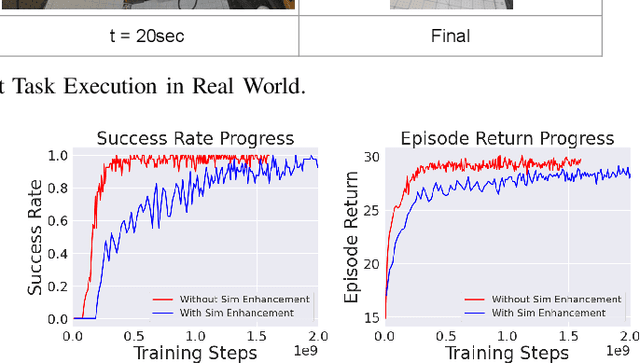
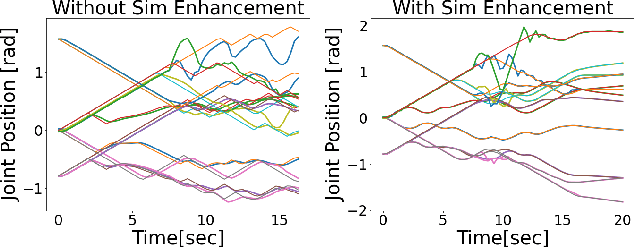
Most successes in robotic manipulation have been restricted to single-arm robots, which limits the range of solvable tasks to pick-and-place, insertion, and objects rearrangement. In contrast, dual and multi arm robot platforms unlock a rich diversity of problems that can be tackled, such as laundry folding and executing cooking skills. However, developing controllers for multi-arm robots is complexified by a number of unique challenges, such as the need for coordinated bimanual behaviors, and collision avoidance amongst robots. Given these challenges, in this work we study how to solve bi-manual tasks using reinforcement learning (RL) trained in simulation, such that the resulting policies can be executed on real robotic platforms. Our RL approach results in significant simplifications due to using real-time (4Hz) joint-space control and directly passing unfiltered observations to neural networks policies. We also extensively discuss modifications to our simulated environment which lead to effective training of RL policies. In addition to designing control algorithms, a key challenge is how to design fair evaluation tasks for bi-manual robots that stress bimanual coordination, while removing orthogonal complicating factors such as high-level perception. In this work, we design a Connect Task, where the aim is for two robot arms to pick up and attach two blocks with magnetic connection points. We validate our approach with two xArm6 robots and 3D printed blocks with magnetic attachments, and find that our system has 100% success rate at picking up blocks, and 65% success rate at the Connect Task.