 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Formal Language Recognition by Hard Attention Transformers: Perspectives from Circuit Complexity
Apr 13, 2022
This paper analyzes three formal models of Transformer encoders that differ in the form of their self-attention mechanism: unique hard attention (UHAT); generalized unique hard attention (GUHAT), which generalizes UHAT; and averaging hard attention (AHAT). We show that UHAT and GUHAT Transformers, viewed as string acceptors, can only recognize formal languages in the complexity class AC$^0$, the class of languages recognizable by families of Boolean circuits of constant depth and polynomial size. This upper bound subsumes Hahn's (2020) results that GUHAT cannot recognize the DYCK languages or the PARITY language, since those languages are outside AC$^0$ (Furst et al., 1984). In contrast, the non-AC$^0$ languages MAJORITY and DYCK-1 are recognizable by AHAT networks, implying that AHAT can recognize languages that UHAT and GUHAT cannot.
An Adversarial Benchmark for Fake News Detection Models
Jan 03, 2022

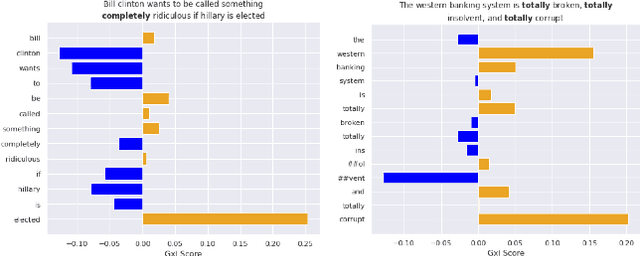
With the proliferation of online misinformation, fake news detection has gained importance in the artificial intelligence community. In this paper, we propose an adversarial benchmark that tests the ability of fake news detectors to reason about real-world facts. We formulate adversarial attacks that target three aspects of "understanding": compositional semantics, lexical relations, and sensitivity to modifiers. We test our benchmark using BERT classifiers fine-tuned on the LIAR arXiv:arch-ive/1705648 and Kaggle Fake-News datasets, and show that both models fail to respond to changes in compositional and lexical meaning. Our results strengthen the need for such models to be used in conjunction with other fact checking methods.
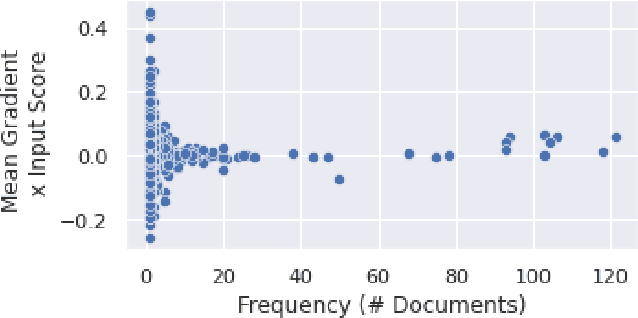
Evaluating Attribution Methods using White-Box LSTMs
Oct 16, 2020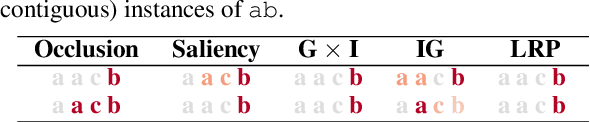

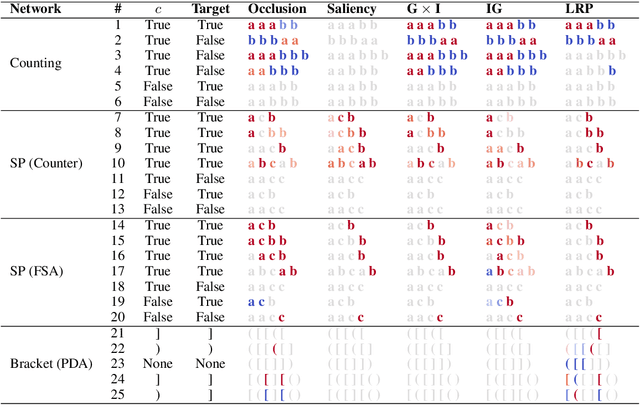
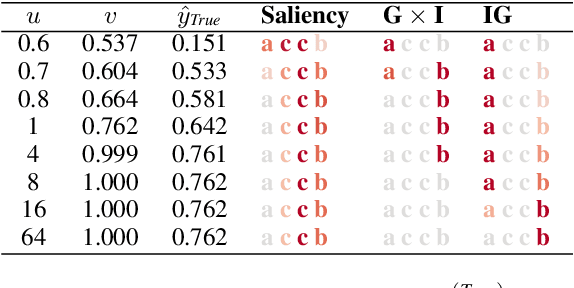
Interpretability methods for neural networks are difficult to evaluate because we do not understand the black-box models typically used to test them. This paper proposes a framework in which interpretability methods are evaluated using manually constructed networks, which we call white-box networks, whose behavior is understood a priori. We evaluate five methods for producing attribution heatmaps by applying them to white-box LSTM classifiers for tasks based on formal languages. Although our white-box classifiers solve their tasks perfectly and transparently, we find that all five attribution methods fail to produce the expected model explanations.
Probabilistic Predictions of People Perusing: Evaluating Metrics of Language Model Performance for Psycholinguistic Modeling
Sep 08, 2020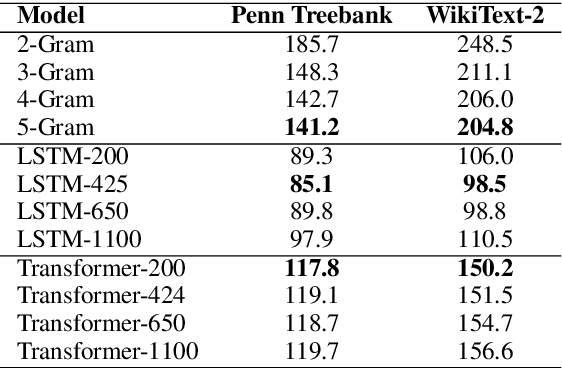
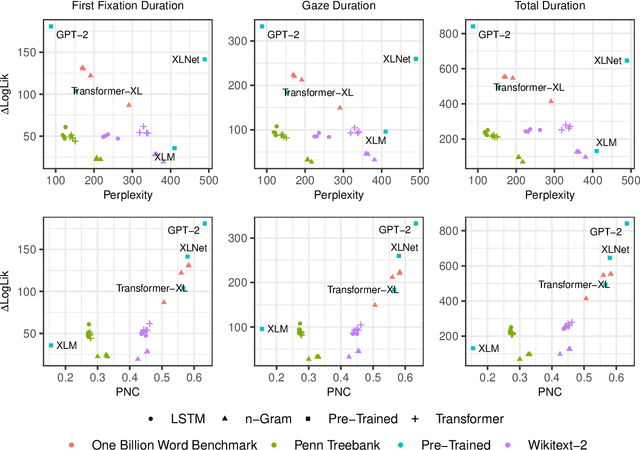
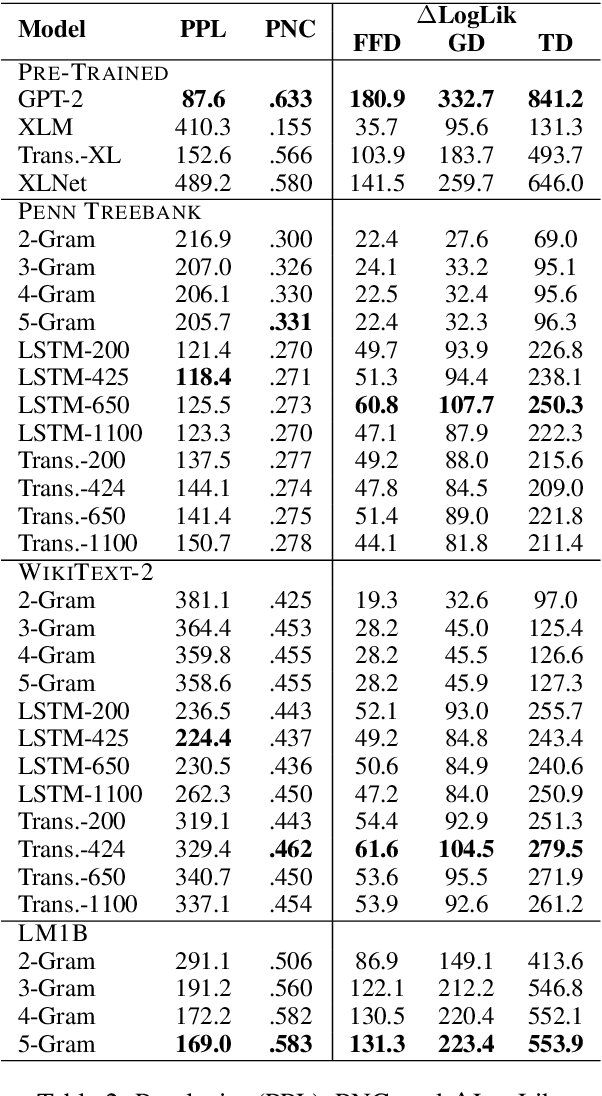
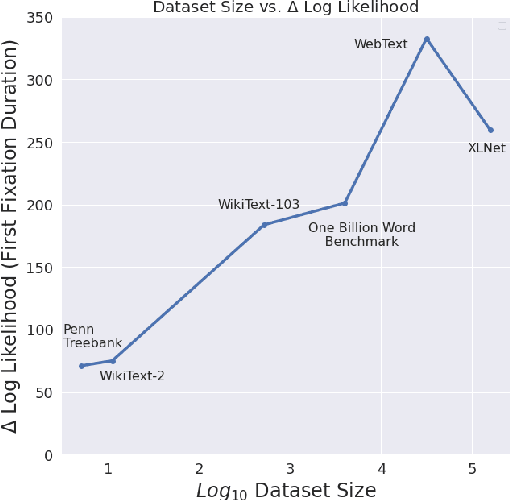
By positing a relationship between naturalistic reading times and information-theoretic surprisal, surprisal theory (Hale, 2001; Levy, 2008) provides a natural interface between language models and psycholinguistic models. This paper re-evaluates a claim due to Goodkind and Bicknell (2018) that a language model's ability to model reading times is a linear function of its perplexity. By extending Goodkind and Bicknell's analysis to modern neural architectures, we show that the proposed relation does not always hold for Long Short-Term Memory networks, Transformers, and pre-trained models. We introduce an alternate measure of language modeling performance called predictability norm correlation based on Cloze probabilities measured from human subjects. Our new metric yields a more robust relationship between language model quality and psycholinguistic modeling performance that allows for comparison between models with different training configurations.
Attribution Analysis of Grammatical Dependencies in LSTMs
Apr 30, 2020
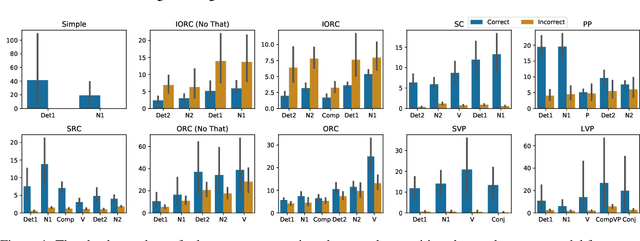
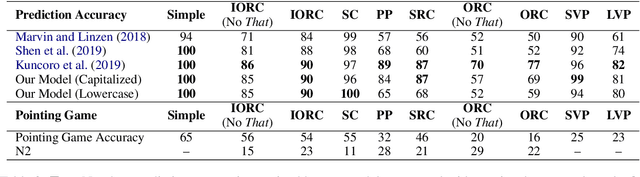
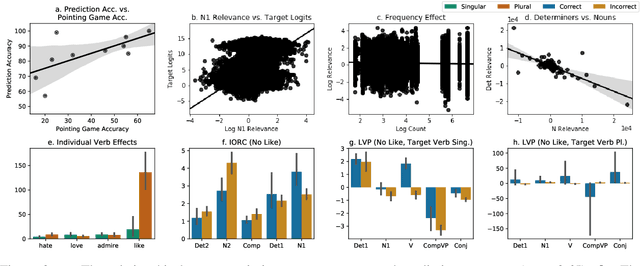
LSTM language models have been shown to capture syntax-sensitive grammatical dependencies such as subject-verb agreement with a high degree of accuracy (Linzen et al., 2016, inter alia). However, questions remain regarding whether they do so using spurious correlations, or whether they are truly able to match verbs with their subjects. This paper argues for the latter hypothesis. Using layer-wise relevance propagation (Bach et al., 2015), a technique that quantifies the contributions of input features to model behavior, we show that LSTM performance on number agreement is directly correlated with the model's ability to distinguish subjects from other nouns. Our results suggest that LSTM language models are able to infer robust representations of syntactic dependencies.
Action-Sensitive Phonological Dependencies
Jun 12, 2019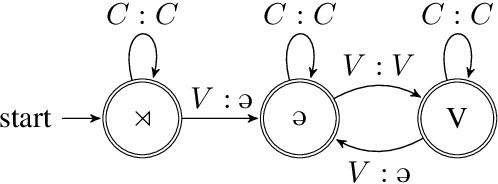
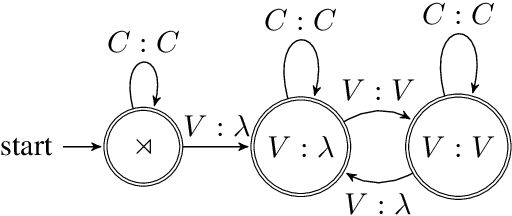
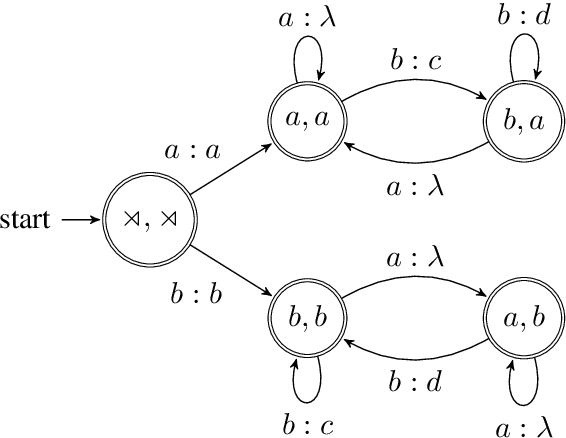
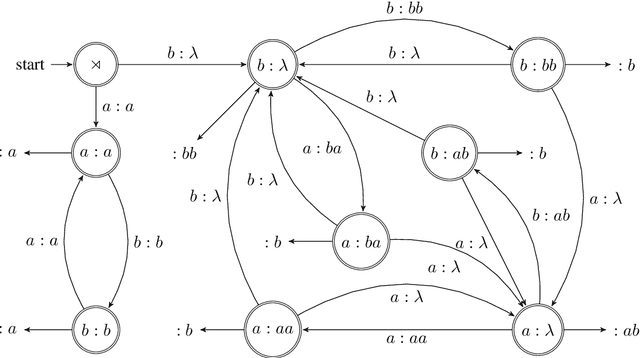
This paper defines a subregular class of functions called the tier-based synchronized strictly local (TSSL) functions. These functions are similar to the the tier-based input-output strictly local (TIOSL) functions, except that the locality condition is enforced not on the input and output streams, but on the computation history of the minimal subsequential finite-state transducer. We show that TSSL functions naturally describe rhythmic syncope while TIOSL functions cannot, and we argue that TSSL functions provide a more restricted characterization of rhythmic syncope than existing treatments within Optimality Theory.
Finding Syntactic Representations in Neural Stacks
Jun 04, 2019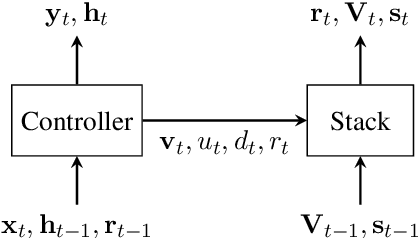
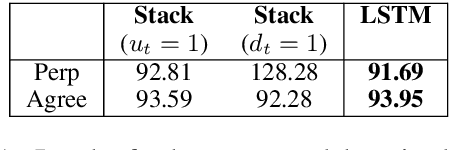
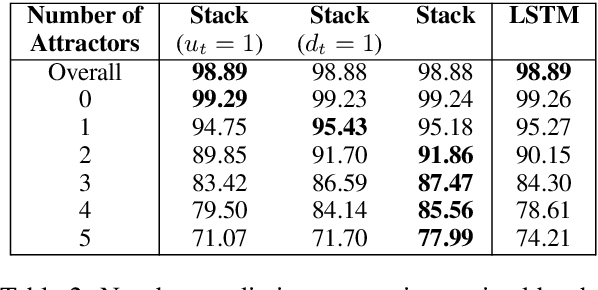
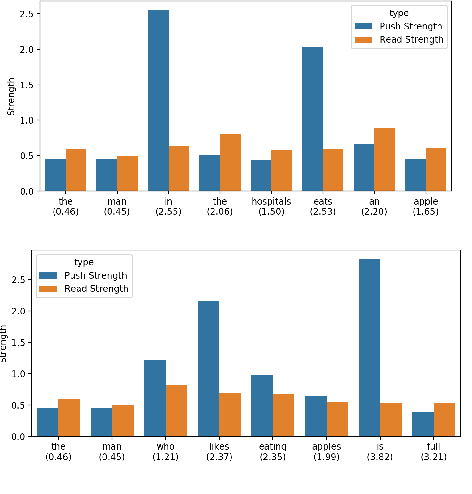
Neural network architectures have been augmented with differentiable stacks in order to introduce a bias toward learning hierarchy-sensitive regularities. It has, however, proven difficult to assess the degree to which such a bias is effective, as the operation of the differentiable stack is not always interpretable. In this paper, we attempt to detect the presence of latent representations of hierarchical structure through an exploration of the unsupervised learning of constituency structure. Using a technique due to Shen et al. (2018a,b), we extract syntactic trees from the pushing behavior of stack RNNs trained on language modeling and classification objectives. We find that our models produce parses that reflect natural language syntactic constituencies, demonstrating that stack RNNs do indeed infer linguistically relevant hierarchical structure.
Context-Free Transductions with Neural Stacks
Sep 08, 2018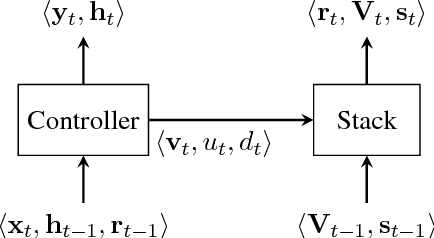
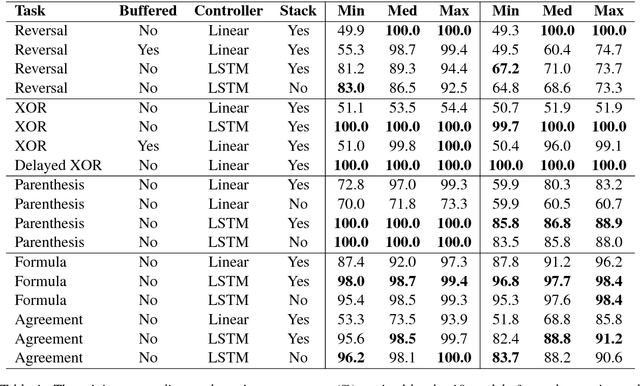
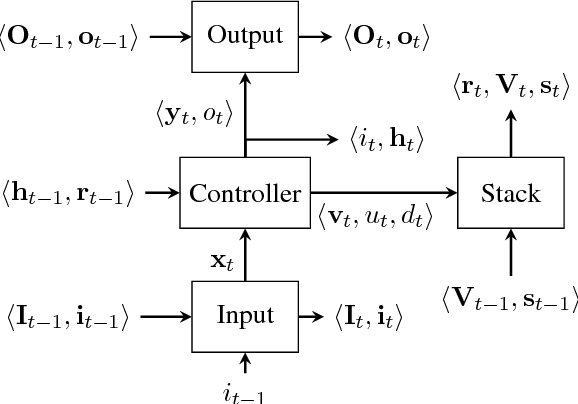
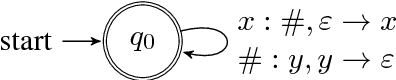
This paper analyzes the behavior of stack-augmented recurrent neural network (RNN) models. Due to the architectural similarity between stack RNNs and pushdown transducers, we train stack RNN models on a number of tasks, including string reversal, context-free language modelling, and cumulative XOR evaluation. Examining the behavior of our networks, we show that stack-augmented RNNs can discover intuitive stack-based strategies for solving our tasks. However, stack RNNs are more difficult to train than classical architectures such as LSTMs. Rather than employ stack-based strategies, more complex networks often find approximate solutions by using the stack as unstructured memory.