 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting the Scaling Properties of Downstream Metrics in Large Language Model Training
Dec 09, 2025While scaling laws for Large Language Models (LLMs) traditionally focus on proxy metrics like pretraining loss, predicting downstream task performance has been considered unreliable. This paper challenges that view by proposing a direct framework to model the scaling of benchmark performance from the training budget. We find that for a fixed token-to-parameter ratio, a simple power law can accurately describe the scaling behavior of log accuracy on multiple popular downstream tasks. Our results show that the direct approach extrapolates better than the previously proposed two-stage procedure, which is prone to compounding errors. Furthermore, we introduce functional forms that predict accuracy across token-to-parameter ratios and account for inference compute under repeated sampling. We validate our findings on models with up to 17B parameters trained on up to 350B tokens across two dataset mixtures. To support reproducibility and encourage future research, we release the complete set of pretraining losses and downstream evaluation results.
Apple Intelligence Foundation Language Models
Jul 29, 2024



We present foundation language models developed to power Apple Intelligence features, including a ~3 billion parameter model designed to run efficiently on devices and a large server-based language model designed for Private Cloud Compute. These models are designed to perform a wide range of tasks efficiently, accurately, and responsibly. This report describes the model architecture, the data used to train the model, the training process, how the models are optimized for inference, and the evaluation results. We highlight our focus on Responsible AI and how the principles are applied throughout the model development.
ChatShop: Interactive Information Seeking with Language Agents
Apr 15, 2024



The desire and ability to seek new information strategically are fundamental to human learning but often overlooked in current language agent development. Using a web shopping task as an example, we show that it can be reformulated and solved as a retrieval task without a requirement of interactive information seeking. We then redesign the task to introduce a new role of shopper, serving as a realistically constrained communication channel. The agents in our proposed ChatShop task explore user preferences in open-ended conversation to make informed decisions. Our experiments demonstrate that the proposed task can effectively evaluate the agent's ability to explore and gradually accumulate information through multi-turn interaction. We also show that LLM-simulated shoppers serve as a good proxy to real human shoppers and discover similar error patterns of agents.
MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training
Mar 22, 2024



In this work, we discuss building performant Multimodal Large Language Models (MLLMs). In particular, we study the importance of various architecture components and data choices. Through careful and comprehensive ablations of the image encoder, the vision language connector, and various pre-training data choices, we identified several crucial design lessons. For example, we demonstrate that for large-scale multimodal pre-training using a careful mix of image-caption, interleaved image-text, and text-only data is crucial for achieving state-of-the-art (SOTA) few-shot results across multiple benchmarks, compared to other published pre-training results. Further, we show that the image encoder together with image resolution and the image token count has substantial impact, while the vision-language connector design is of comparatively negligible importance. By scaling up the presented recipe, we build MM1, a family of multimodal models up to 30B parameters, including both dense models and mixture-of-experts (MoE) variants, that are SOTA in pre-training metrics and achieve competitive performance after supervised fine-tuning on a range of established multimodal benchmarks. Thanks to large-scale pre-training, MM1 enjoys appealing properties such as enhanced in-context learning, and multi-image reasoning, enabling few-shot chain-of-thought prompting.
Seq2seq is All You Need for Coreference Resolution
Oct 20, 2023



Existing works on coreference resolution suggest that task-specific models are necessary to achieve state-of-the-art performance. In this work, we present compelling evidence that such models are not necessary. We finetune a pretrained seq2seq transformer to map an input document to a tagged sequence encoding the coreference annotation. Despite the extreme simplicity, our model outperforms or closely matches the best coreference systems in the literature on an array of datasets. We also propose an especially simple seq2seq approach that generates only tagged spans rather than the spans interleaved with the original text. Our analysis shows that the model size, the amount of supervision, and the choice of sequence representations are key factors in performance.
BM25 Query Augmentation Learned End-to-End
May 23, 2023



Given BM25's enduring competitiveness as an information retrieval baseline, we investigate to what extent it can be even further improved by augmenting and re-weighting its sparse query-vector representation. We propose an approach to learning an augmentation and a re-weighting end-to-end, and we find that our approach improves performance over BM25 while retaining its speed. We furthermore find that the learned augmentations and re-weightings transfer well to unseen datasets.
Approximating CKY with Transformers
May 03, 2023



We investigate the ability of transformer models to approximate the CKY algorithm, using them to directly predict a parse and thus avoid the CKY algorithm's cubic dependence on sentence length. We find that on standard constituency parsing benchmarks this approach achieves competitive or better performance than comparable parsers that make use of CKY, while being faster. We also evaluate the viability of this approach for parsing under random PCFGs. Here we find that performance declines as the grammar becomes more ambiguous, suggesting that the transformer is not fully capturing the CKY computation. However, we also find that incorporating additional inductive bias is helpful, and we propose a novel approach that makes use of gradients with respect to chart representations in predicting the parse, in analogy with the CKY algorithm being the subgradient of a partition function variant with respect to the chart.
CREATIVESUMM: Shared Task on Automatic Summarization for Creative Writing
Nov 10, 2022



This paper introduces the shared task of summarizing documents in several creative domains, namely literary texts, movie scripts, and television scripts. Summarizing these creative documents requires making complex literary interpretations, as well as understanding non-trivial temporal dependencies in texts containing varied styles of plot development and narrative structure. This poses unique challenges and is yet underexplored for text summarization systems. In this shared task, we introduce four sub-tasks and their corresponding datasets, focusing on summarizing books, movie scripts, primetime television scripts, and daytime soap opera scripts. We detail the process of curating these datasets for the task, as well as the metrics used for the evaluation of the submissions. As part of the CREATIVESUMM workshop at COLING 2022, the shared task attracted 18 submissions in total. We discuss the submissions and the baselines for each sub-task in this paper, along with directions for facilitating future work in the field.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
On Generalization in Coreference Resolution
Sep 20, 2021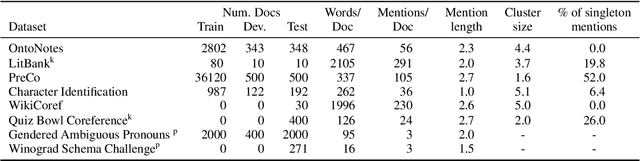
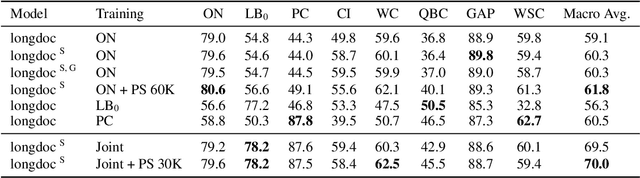

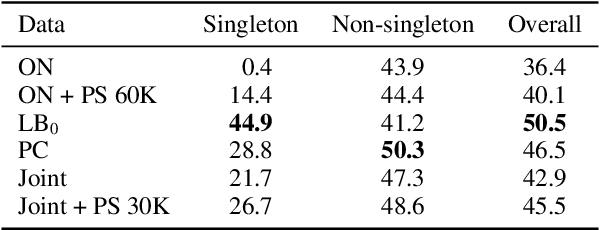
While coreference resolution is defined independently of dataset domain, most models for performing coreference resolution do not transfer well to unseen domains. We consolidate a set of 8 coreference resolution datasets targeting different domains to evaluate the off-the-shelf performance of models. We then mix three datasets for training; even though their domain, annotation guidelines, and metadata differ, we propose a method for jointly training a single model on this heterogeneous data mixture by using data augmentation to account for annotation differences and sampling to balance the data quantities. We find that in a zero-shot setting, models trained on a single dataset transfer poorly while joint training yields improved overall performance, leading to better generalization in coreference resolution models. This work contributes a new benchmark for robust coreference resolution and multiple new state-of-the-art results.