 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIsoCompute Playbook: Optimally Scaling Sampling Compute for LLM RL
Mar 12, 2026While scaling laws guide compute allocation for LLM pre-training, analogous prescriptions for reinforcement learning (RL) post-training of large language models (LLMs) remain poorly understood. We study the compute-optimal allocation of sampling compute for on-policy RL methods in LLMs, framing scaling as a compute-constrained optimization over three resources: parallel rollouts per problem, number of problems per batch, and number of update steps. We find that the compute-optimal number of parallel rollouts per problem increases predictably with compute budget and then saturates. This trend holds across both easy and hard problems, though driven by different mechanisms: solution sharpening on easy problems and coverage expansion on hard problems. We further show that increasing the number of parallel rollouts mitigates interference across problems, while the number of problems per batch primarily affects training stability and can be chosen within a broad range. Validated across base models and data distributions, our results recast RL scaling laws as prescriptive allocation rules and provide practical guidance for compute-efficient LLM RL post-training.
Retrospective In-Context Learning for Temporal Credit Assignment with Large Language Models
Feb 19, 2026Learning from self-sampled data and sparse environmental feedback remains a fundamental challenge in training self-evolving agents. Temporal credit assignment mitigates this issue by transforming sparse feedback into dense supervision signals. However, previous approaches typically depend on learning task-specific value functions for credit assignment, which suffer from poor sample efficiency and limited generalization. In this work, we propose to leverage pretrained knowledge from large language models (LLMs) to transform sparse rewards into dense training signals (i.e., the advantage function) through retrospective in-context learning (RICL). We further propose an online learning framework, RICOL, which iteratively refines the policy based on the credit assignment results from RICL. We empirically demonstrate that RICL can accurately estimate the advantage function with limited samples and effectively identify critical states in the environment for temporal credit assignment. Extended evaluation on four BabyAI scenarios show that RICOL achieves comparable convergent performance with traditional online RL algorithms with significantly higher sample efficiency. Our findings highlight the potential of leveraging LLMs for temporal credit assignment, paving the way for more sample-efficient and generalizable RL paradigms.
Maximum Likelihood Reinforcement Learning
Feb 02, 2026Reinforcement learning is the method of choice to train models in sampling-based setups with binary outcome feedback, such as navigation, code generation, and mathematical problem solving. In such settings, models implicitly induce a likelihood over correct rollouts. However, we observe that reinforcement learning does not maximize this likelihood, and instead optimizes only a lower-order approximation. Inspired by this observation, we introduce Maximum Likelihood Reinforcement Learning (MaxRL), a sampling-based framework to approximate maximum likelihood using reinforcement learning techniques. MaxRL addresses the challenges of non-differentiable sampling by defining a compute-indexed family of sample-based objectives that interpolate between standard reinforcement learning and exact maximum likelihood as additional sampling compute is allocated. The resulting objectives admit a simple, unbiased policy-gradient estimator and converge to maximum likelihood optimization in the infinite-compute limit. Empirically, we show that MaxRL Pareto-dominates existing methods in all models and tasks we tested, achieving up to 20x test-time scaling efficiency gains compared to its GRPO-trained counterpart. We also observe MaxRL to scale better with additional data and compute. Our results suggest MaxRL is a promising framework for scaling RL training in correctness based settings.
POPE: Learning to Reason on Hard Problems via Privileged On-Policy Exploration
Jan 26, 2026Reinforcement learning (RL) has improved the reasoning abilities of large language models (LLMs), yet state-of-the-art methods still fail to learn on many training problems. On hard problems, on-policy RL rarely explores even a single correct rollout, yielding zero reward and no learning signal for driving improvement. We find that natural solutions to remedy this exploration problem from classical RL, such as entropy bonuses, more permissive clipping of the importance ratio, or direct optimization of pass@k objectives, do not resolve this issue and often destabilize optimization without improving solvability. A natural alternative is to leverage transfer from easier problems. However, we show that mixing easy and hard problems during RL training is counterproductive due to ray interference, where optimization focuses on already-solvable problems in a way that actively inhibits progress on harder ones. To address this challenge, we introduce Privileged On-Policy Exploration (POPE), an approach that leverages human- or other oracle solutions as privileged information to guide exploration on hard problems, unlike methods that use oracle solutions as training targets (e.g., off-policy RL methods or warmstarting from SFT). POPE augments hard problems with prefixes of oracle solutions, enabling RL to obtain non-zero rewards during guided rollouts. Crucially, the resulting behaviors transfer back to the original, unguided problems through a synergy between instruction-following and reasoning. Empirically, POPE expands the set of solvable problems and substantially improves performance on challenging reasoning benchmarks.
Tuning-free Visual Effect Transfer across Videos
Jan 13, 2026We present RefVFX, a new framework that transfers complex temporal effects from a reference video onto a target video or image in a feed-forward manner. While existing methods excel at prompt-based or keyframe-conditioned editing, they struggle with dynamic temporal effects such as dynamic lighting changes or character transformations, which are difficult to describe via text or static conditions. Transferring a video effect is challenging, as the model must integrate the new temporal dynamics with the input video's existing motion and appearance. % To address this, we introduce a large-scale dataset of triplets, where each triplet consists of a reference effect video, an input image or video, and a corresponding output video depicting the transferred effect. Creating this data is non-trivial, especially the video-to-video effect triplets, which do not exist naturally. To generate these, we propose a scalable automated pipeline that creates high-quality paired videos designed to preserve the input's motion and structure while transforming it based on some fixed, repeatable effect. We then augment this data with image-to-video effects derived from LoRA adapters and code-based temporal effects generated through programmatic composition. Building on our new dataset, we train our reference-conditioned model using recent text-to-video backbones. Experimental results demonstrate that RefVFX produces visually consistent and temporally coherent edits, generalizes across unseen effect categories, and outperforms prompt-only baselines in both quantitative metrics and human preference. See our website https://tuningfreevisualeffects-maker.github.io/Tuning-free-Visual-Effect-Transfer-across-Videos-Project-Page/
RLAD: Training LLMs to Discover Abstractions for Solving Reasoning Problems
Oct 02, 2025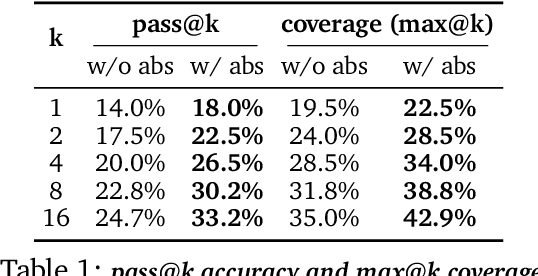
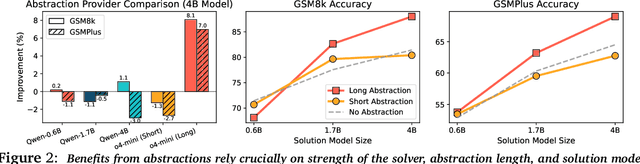
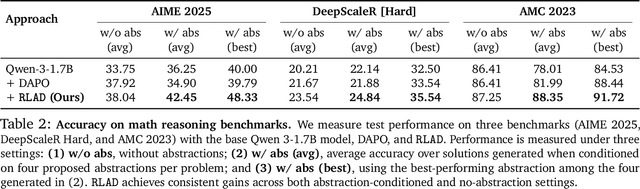
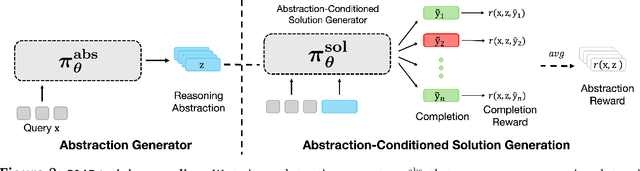
Reasoning requires going beyond pattern matching or memorization of solutions to identify and implement "algorithmic procedures" that can be used to deduce answers to hard problems. Doing so requires realizing the most relevant primitives, intermediate results, or shared procedures, and building upon them. While RL post-training on long chains of thought ultimately aims to uncover this kind of algorithmic behavior, most reasoning traces learned by large models fail to consistently capture or reuse procedures, instead drifting into verbose and degenerate exploration. To address more effective reasoning, we introduce reasoning abstractions: concise natural language descriptions of procedural and factual knowledge that guide the model toward learning successful reasoning. We train models to be capable of proposing multiple abstractions given a problem, followed by RL that incentivizes building a solution while using the information provided by these abstractions. This results in a two-player RL training paradigm, abbreviated as RLAD, that jointly trains an abstraction generator and a solution generator. This setup effectively enables structured exploration, decouples learning signals of abstraction proposal and solution generation, and improves generalization to harder problems. We also show that allocating more test-time compute to generating abstractions is more beneficial for performance than generating more solutions at large test budgets, illustrating the role of abstractions in guiding meaningful exploration.
Accelerating Diffusion Models in Offline RL via Reward-Aware Consistency Trajectory Distillation
Jun 09, 2025Although diffusion models have achieved strong results in decision-making tasks, their slow inference speed remains a key limitation. While the consistency model offers a potential solution, its applications to decision-making often struggle with suboptimal demonstrations or rely on complex concurrent training of multiple networks. In this work, we propose a novel approach to consistency distillation for offline reinforcement learning that directly incorporates reward optimization into the distillation process. Our method enables single-step generation while maintaining higher performance and simpler training. Empirical evaluations on the Gym MuJoCo benchmarks and long horizon planning demonstrate that our approach can achieve an 8.7% improvement over previous state-of-the-art while offering up to 142x speedup over diffusion counterparts in inference time.
Can Large Reasoning Models Self-Train?
May 27, 2025



Scaling the performance of large language models (LLMs) increasingly depends on methods that reduce reliance on human supervision. Reinforcement learning from automated verification offers an alternative, but it incurs scalability limitations due to dependency upon human-designed verifiers. Self-training, where the model's own judgment provides the supervisory signal, presents a compelling direction. We propose an online self-training reinforcement learning algorithm that leverages the model's self-consistency to infer correctness signals and train without any ground-truth supervision. We apply the algorithm to challenging mathematical reasoning tasks and show that it quickly reaches performance levels rivaling reinforcement-learning methods trained explicitly on gold-standard answers. Additionally, we analyze inherent limitations of the algorithm, highlighting how the self-generated proxy reward initially correlated with correctness can incentivize reward hacking, where confidently incorrect outputs are favored. Our results illustrate how self-supervised improvement can achieve significant performance gains without external labels, while also revealing its fundamental challenges.
AgentDAM: Privacy Leakage Evaluation for Autonomous Web Agents
Mar 12, 2025



LLM-powered AI agents are an emerging frontier with tremendous potential to increase human productivity. However, empowering AI agents to take action on their user's behalf in day-to-day tasks involves giving them access to potentially sensitive and private information, which leads to a possible risk of inadvertent privacy leakage when the agent malfunctions. In this work, we propose one way to address that potential risk, by training AI agents to better satisfy the privacy principle of data minimization. For the purposes of this benchmark, by "data minimization" we mean instances where private information is shared only when it is necessary to fulfill a specific task-relevant purpose. We develop a benchmark called AgentDAM to evaluate how well existing and future AI agents can limit processing of potentially private information that we designate "necessary" to fulfill the task. Our benchmark simulates realistic web interaction scenarios and is adaptable to all existing web navigation agents. We use AgentDAM to evaluate how well AI agents built on top of GPT-4, Llama-3 and Claude can limit processing of potentially private information when unnecessary, and show that these agents are often prone to inadvertent use of unnecessary sensitive information. We finally propose a prompting-based approach that reduces this.
Optimizing Test-Time Compute via Meta Reinforcement Fine-Tuning
Mar 10, 2025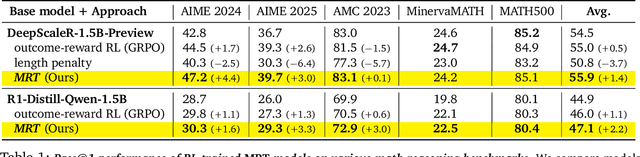
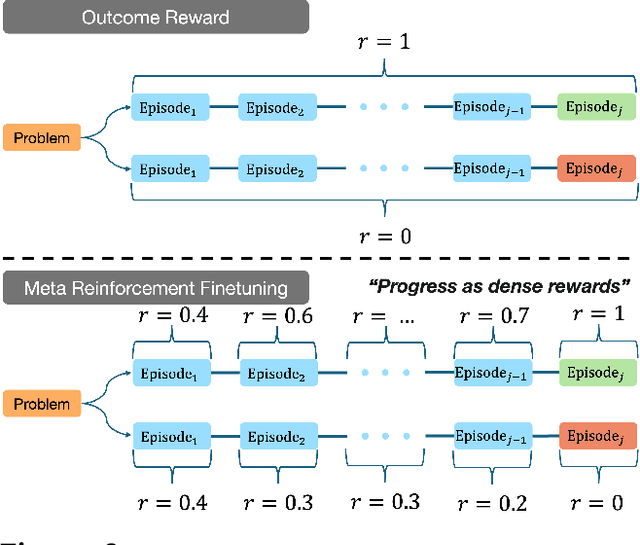
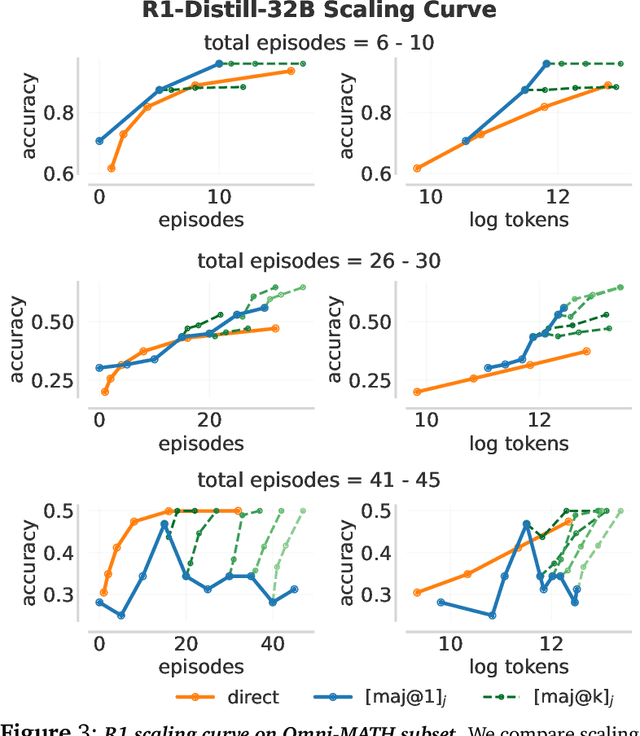
Training models to effectively use test-time compute is crucial for improving the reasoning performance of LLMs. Current methods mostly do so via fine-tuning on search traces or running RL with 0/1 outcome reward, but do these approaches efficiently utilize test-time compute? Would these approaches continue to scale as the budget improves? In this paper, we try to answer these questions. We formalize the problem of optimizing test-time compute as a meta-reinforcement learning (RL) problem, which provides a principled perspective on spending test-time compute. This perspective enables us to view the long output stream from the LLM as consisting of several episodes run at test time and leads us to use a notion of cumulative regret over output tokens as a way to measure the efficacy of test-time compute. Akin to how RL algorithms can best tradeoff exploration and exploitation over training, minimizing cumulative regret would also provide the best balance between exploration and exploitation in the token stream. While we show that state-of-the-art models do not minimize regret, one can do so by maximizing a dense reward bonus in conjunction with the outcome 0/1 reward RL. This bonus is the ''progress'' made by each subsequent block in the output stream, quantified by the change in the likelihood of eventual success. Using these insights, we develop Meta Reinforcement Fine-Tuning, or MRT, a new class of fine-tuning methods for optimizing test-time compute. MRT leads to a 2-3x relative gain in performance and roughly a 1.5x gain in token efficiency for math reasoning compared to outcome-reward RL.