 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZeroSCROLLS: A Zero-Shot Benchmark for Long Text Understanding
May 23, 2023



We introduce ZeroSCROLLS, a zero-shot benchmark for natural language understanding over long texts, which contains only test sets, without training or development data. We adapt six tasks from the SCROLLS benchmark, and add four new datasets, including two novel information fusing tasks, such as aggregating the percentage of positive reviews. Using ZeroSCROLLS, we conduct a comprehensive evaluation of both open-source and closed large language models, finding that Claude outperforms ChatGPT, and that GPT-4 achieves the highest average score. However, there is still room for improvement on multiple open challenges in ZeroSCROLLS, such as aggregation tasks, where models struggle to pass the naive baseline. As the state of the art is a moving target, we invite researchers to evaluate their ideas on the live ZeroSCROLLS leaderboard
LIMA: Less Is More for Alignment
May 18, 2023



Large language models are trained in two stages: (1) unsupervised pretraining from raw text, to learn general-purpose representations, and (2) large scale instruction tuning and reinforcement learning, to better align to end tasks and user preferences. We measure the relative importance of these two stages by training LIMA, a 65B parameter LLaMa language model fine-tuned with the standard supervised loss on only 1,000 carefully curated prompts and responses, without any reinforcement learning or human preference modeling. LIMA demonstrates remarkably strong performance, learning to follow specific response formats from only a handful of examples in the training data, including complex queries that range from planning trip itineraries to speculating about alternate history. Moreover, the model tends to generalize well to unseen tasks that did not appear in the training data. In a controlled human study, responses from LIMA are either equivalent or strictly preferred to GPT-4 in 43% of cases; this statistic is as high as 58% when compared to Bard and 65% versus DaVinci003, which was trained with human feedback. Taken together, these results strongly suggest that almost all knowledge in large language models is learned during pretraining, and only limited instruction tuning data is necessary to teach models to produce high quality output.
LMentry: A Language Model Benchmark of Elementary Language Tasks
Nov 03, 2022As the performance of large language models rapidly improves, benchmarks are getting larger and more complex as well. We present LMentry, a benchmark that avoids this "arms race" by focusing on a compact set of tasks that are trivial to humans, e.g. writing a sentence containing a specific word, identifying which words in a list belong to a specific category, or choosing which of two words is longer. LMentry is specifically designed to provide quick and interpretable insights into the capabilities and robustness of large language models. Our experiments reveal a wide variety of failure cases that, while immediately obvious to humans, pose a considerable challenge for large language models, including OpenAI's latest 175B-parameter instruction-tuned model, TextDavinci002. LMentry complements contemporary evaluation approaches of large language models, providing a quick, automatic, and easy-to-run "unit test", without resorting to large benchmark suites of complex tasks.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
SCROLLS: Standardized CompaRison Over Long Language Sequences
Jan 10, 2022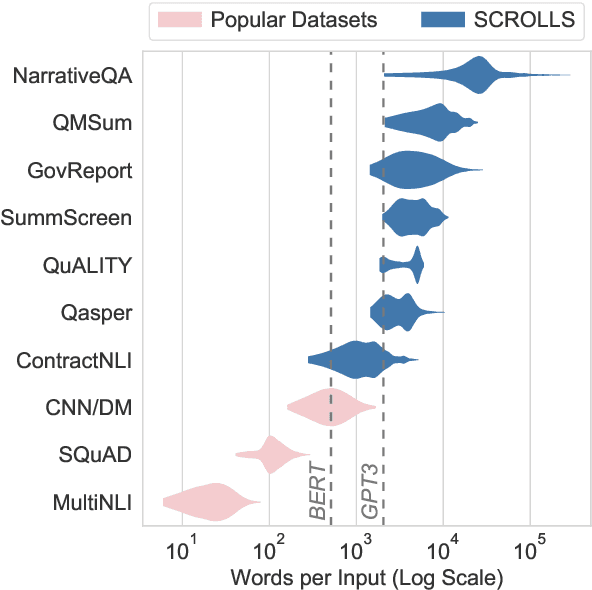
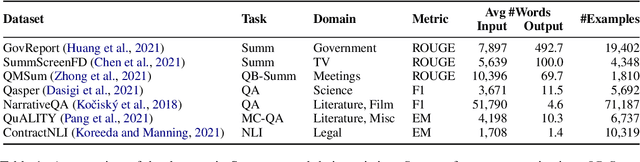

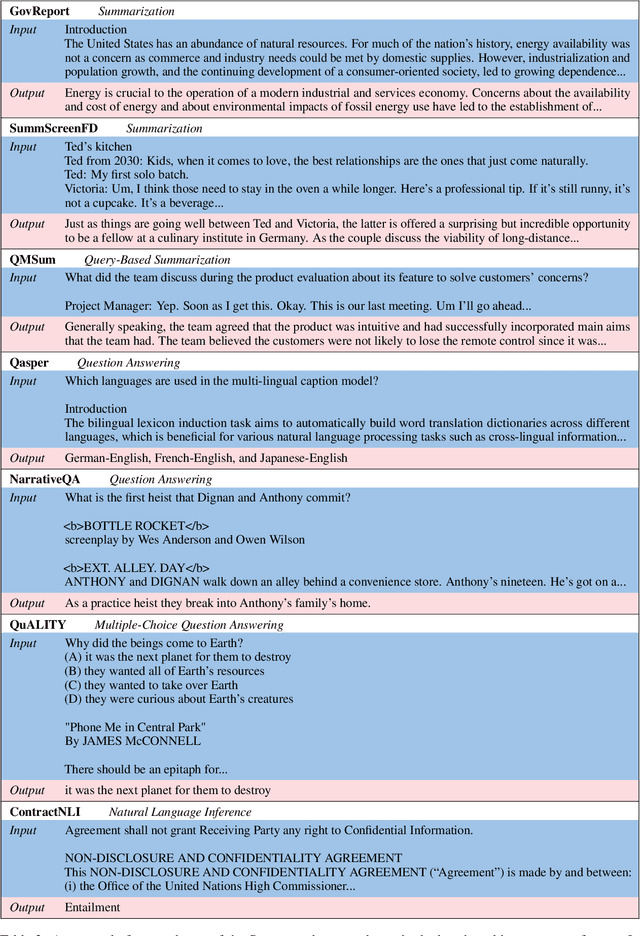
NLP benchmarks have largely focused on short texts, such as sentences and paragraphs, even though long texts comprise a considerable amount of natural language in the wild. We introduce SCROLLS, a suite of tasks that require reasoning over long texts. We examine existing long-text datasets, and handpick ones where the text is naturally long, while prioritizing tasks that involve synthesizing information across the input. SCROLLS contains summarization, question answering, and natural language inference tasks, covering multiple domains, including literature, science, business, and entertainment. Initial baselines, including Longformer Encoder-Decoder, indicate that there is ample room for improvement on SCROLLS. We make all datasets available in a unified text-to-text format and host a live leaderboard to facilitate research on model architecture and pretraining methods.
How Optimal is Greedy Decoding for Extractive Question Answering?
Aug 12, 2021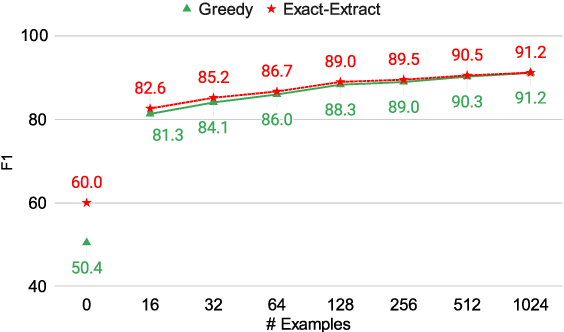
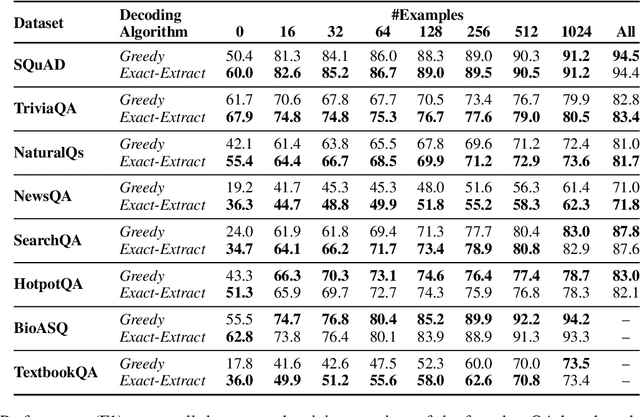
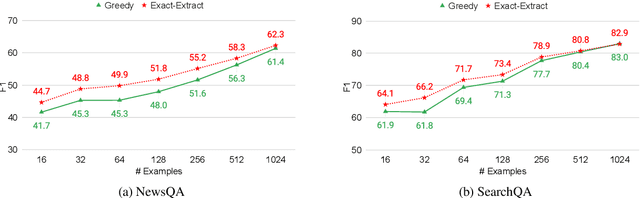
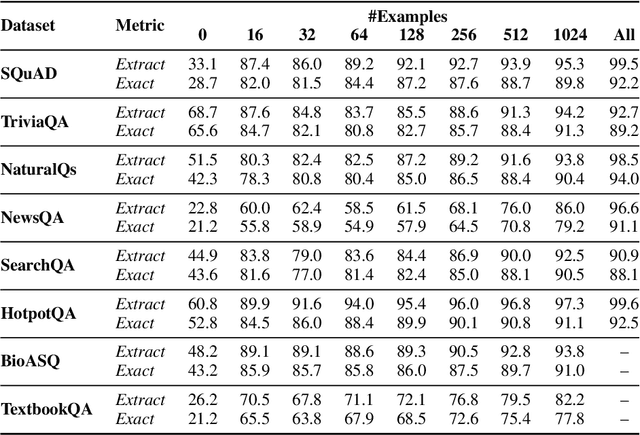
Fine-tuned language models use greedy decoding to answer reading comprehension questions with relative success. However, this approach does not ensure that the answer is a span in the given passage, nor does it guarantee that it is the most probable one. Does greedy decoding actually perform worse than an algorithm that does adhere to these properties? To study the performance and optimality of greedy decoding, we present exact-extract, a decoding algorithm that efficiently finds the most probable answer span in the context. We compare the performance of T5 with both decoding algorithms on zero-shot and few-shot extractive question answering. When no training examples are available, exact-extract significantly outperforms greedy decoding. However, greedy decoding quickly converges towards the performance of exact-extract with the introduction of a few training examples, becoming more extractive and increasingly likelier to generate the most probable span as the training set grows. We also show that self-supervised training can bias the model towards extractive behavior, increasing performance in the zero-shot setting without resorting to annotated examples. Overall, our results suggest that pretrained language models are so good at adapting to extractive question answering, that it is often enough to fine-tune on a small training set for the greedy algorithm to emulate the optimal decoding strategy.
Cryptonite: A Cryptic Crossword Benchmark for Extreme Ambiguity in Language
Mar 01, 2021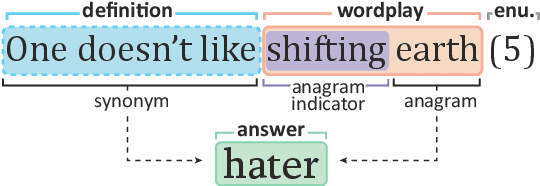
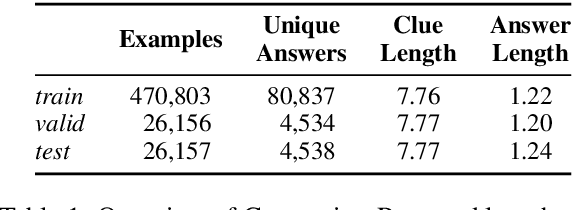


Current NLP datasets targeting ambiguity can be solved by a native speaker with relative ease. We present Cryptonite, a large-scale dataset based on cryptic crosswords, which is both linguistically complex and naturally sourced. Each example in Cryptonite is a cryptic clue, a short phrase or sentence with a misleading surface reading, whose solving requires disambiguating semantic, syntactic, and phonetic wordplays, as well as world knowledge. Cryptic clues pose a challenge even for experienced solvers, though top-tier experts can solve them with almost 100% accuracy. Cryptonite is a challenging task for current models; fine-tuning T5-Large on 470k cryptic clues achieves only 7.6% accuracy, on par with the accuracy of a rule-based clue solver (8.6%).
The Turking Test: Can Language Models Understand Instructions?
Oct 22, 2020
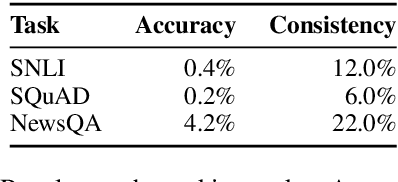


Supervised machine learning provides the learner with a set of input-output examples of the target task. Humans, however, can also learn to perform new tasks from instructions in natural language. Can machines learn to understand instructions as well? We present the Turking Test, which examines a model's ability to follow natural language instructions of varying complexity. These range from simple tasks, like retrieving the nth word of a sentence, to ones that require creativity, such as generating examples for SNLI and SQuAD in place of human intelligence workers ("turkers"). Despite our lenient evaluation methodology, we observe that a large pretrained language model performs poorly across all tasks. Analyzing the model's error patterns reveals that the model tends to ignore explicit instructions and often generates outputs that cannot be construed as an attempt to solve the task. While it is not yet clear whether instruction understanding can be captured by traditional language models, the sheer expressivity of instruction understanding makes it an appealing alternative to the rising few-shot inference paradigm.
Tag-based Multi-Span Extraction in Reading Comprehension
Oct 02, 2019
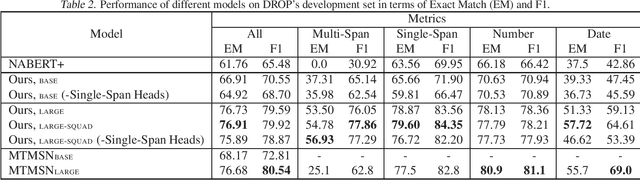
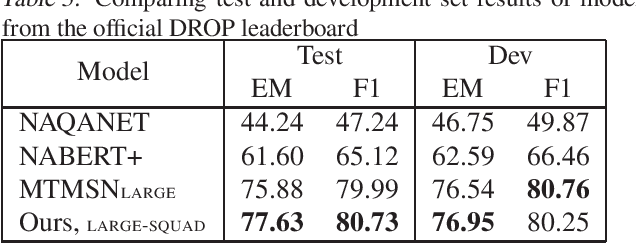
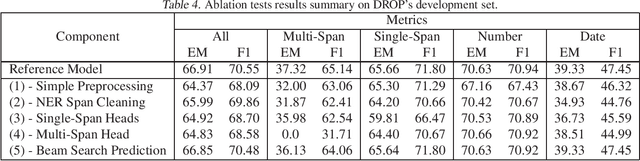
With models reaching human performance on many popular reading comprehension datasets in recent years, a new dataset, DROP, introduced questions that were expected to present a harder challenge for reading comprehension models. Among these new types of questions were "multi-span questions", questions whose answers consist of several spans from either the paragraph or the question itself. Until now, only one model attempted to tackle multi-span questions as a part of its design. In this work, we suggest a new approach for tackling multi-span questions, based on sequence tagging, which differs from previous approaches for answering span questions. We show that our approach leads to an absolute improvement of 29.7 EM and 15.1 F1 compared to existing state-of-the-art results, while not hurting performance on other question types. Furthermore, we show that our model slightly eclipses the current state-of-the-art results on the entire DROP dataset.