 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReflective Prompt Tuning through Language Model Function-Calling
May 20, 2026Large language models (LLMs) have become increasingly capable of following instructions and complex reasoning, making prompting a flexible interface for adapting models without parameter updates. Yet prompt design remains labor-intensive and highly sensitive to formatting, phrasing, and instruction order, motivating automated prompt optimization methods that reduce manual effort while preserving inference-time flexibility. However, existing methods often search over prompt candidates or use fixed critique-refine pipelines driven by individual examples or small batches, limiting their ability to capture systematic error patterns and make targeted edits grounded in failure history. We propose Reflective Prompt Tuning (RPT), a framework that uses LLM function calling to simulate the iterative workflow of human prompt engineers. An LLM optimizer calls a diagnostic function that evaluates the target model over an entire optimization set, summarizes recurring failure modes, and returns a structured diagnostic report. The optimizer uses this report, together with an accumulated memory of prior reports, to revise the prompt for the next iteration. RPT further supports confidence-aware optimization by using calibration signals in diagnostic feedback and final prompt selection. Across three reasoning tasks, RPT improves over initial prompts by up to 12.9 points, remains competitive with state of the art, and improves confidence calibration. Our analyses show that RPT is especially effective on multi-hop and mathematical reasoning, producing targeted prompt revisions that align with diagnosed failure patterns and lead to gains in task performance and calibration.
Blue Data Intelligence Layer: Streaming Data and Agents for Multi-source Multi-modal Data-Centric Applications
Apr 16, 2026NL2SQL systems aim to address the growing need for natural language interaction with data. However, real-world information rarely maps to a single SQL query because (1) users express queries iteratively (2) questions often span multiple data sources beyond the closed-world assumption of a single database, and (3) queries frequently rely on commonsense or external knowledge. Consequently, satisfying realistic data needs require integrating heterogeneous sources, modalities, and contextual data. In this paper, we present Blue's Data Intelligence Layer (DIL) designed to support multi-source, multi-modal, and data-centric applications. Blue is a compound AI system that orchestrates agents and data for enterprise settings. DIL serves as the data intelligence layer for agentic data processing, to bridge the semantic gap between user intent and available information by unifying structured enterprise data, world knowledge accessible through LLMs, and personal context obtained through interaction. At the core of DIL is a data registry that stores metadata for diverse data sources and modalities to enable both native and natural language queries. DIL treats LLMs, the Web, and the User as source 'databases', each with their own query interface, elevating them to first-class data sources. DIL relies on data planners to transform user queries into executable query plans. These plans are declarative abstractions that unify relational operators with other operators spanning multiple modalities. DIL planners support decomposition of complex requests into subqueries, retrieval from diverse sources, and finally reasoning and integration to produce final results. We demonstrate DIL through two interactive scenarios in which user queries dynamically trigger multi-source retrieval, cross-modal reasoning, and result synthesis, illustrating how compound AI systems can move beyond single database NL2SQL.
Align then Train: Efficient Retrieval Adapter Learning
Apr 03, 2026Dense retrieval systems increasingly need to handle complex queries. In many realistic settings, users express intent through long instructions or task-specific descriptions, while target documents remain relatively simple and static. This asymmetry creates a retrieval mismatch: understanding queries may require strong reasoning and instruction-following, whereas efficient document indexing favors lightweight encoders. Existing retrieval systems often address this mismatch by directly improving the embedding model, but fine-tuning large embedding models to better follow such instructions is computationally expensive, memory-intensive, and operationally burdensome. To address this challenge, we propose Efficient Retrieval Adapter (ERA), a label-efficient framework that trains retrieval adapters in two stages: self-supervised alignment and supervised adaptation. Inspired by the pre-training and supervised fine-tuning stages of LLMs, ERA first aligns the embedding spaces of a large query embedder and a lightweight document embedder, and then uses limited labeled data to adapt the query-side representation, bridging both the representation gap between embedding models and the semantic gap between complex queries and simple documents without re-indexing the corpus. Experiments on the MAIR benchmark, spanning 126 retrieval tasks across 6 domains, show that ERA improves retrieval in low-label settings, outperforms methods that rely on larger amounts of labeled data, and effectively combines stronger query embedders with weaker document embedders across domains.
Mixed Signals: Decoding VLMs' Reasoning and Underlying Bias in Vision-Language Conflict
Apr 11, 2025Vision-language models (VLMs) have demonstrated impressive performance by effectively integrating visual and textual information to solve complex tasks. However, it is not clear how these models reason over the visual and textual data together, nor how the flow of information between modalities is structured. In this paper, we examine how VLMs reason by analyzing their biases when confronted with scenarios that present conflicting image and text cues, a common occurrence in real-world applications. To uncover the extent and nature of these biases, we build upon existing benchmarks to create five datasets containing mismatched image-text pairs, covering topics in mathematics, science, and visual descriptions. Our analysis shows that VLMs favor text in simpler queries but shift toward images as query complexity increases. This bias correlates with model scale, with the difference between the percentage of image- and text-preferred responses ranging from +56.8% (image favored) to -74.4% (text favored), depending on the task and model. In addition, we explore three mitigation strategies: simple prompt modifications, modifications that explicitly instruct models on how to handle conflicting information (akin to chain-of-thought prompting), and a task decomposition strategy that analyzes each modality separately before combining their results. Our findings indicate that the effectiveness of these strategies in identifying and mitigating bias varies significantly and is closely linked to the model's overall performance on the task and the specific modality in question.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
ParsiNLU: A Suite of Language Understanding Challenges for Persian
Dec 11, 2020
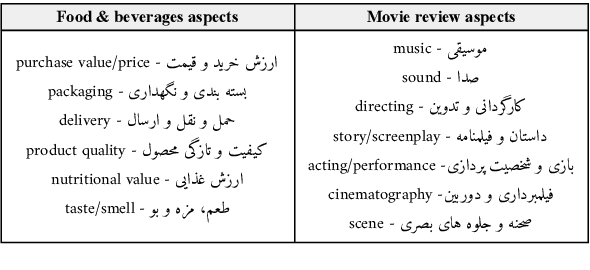
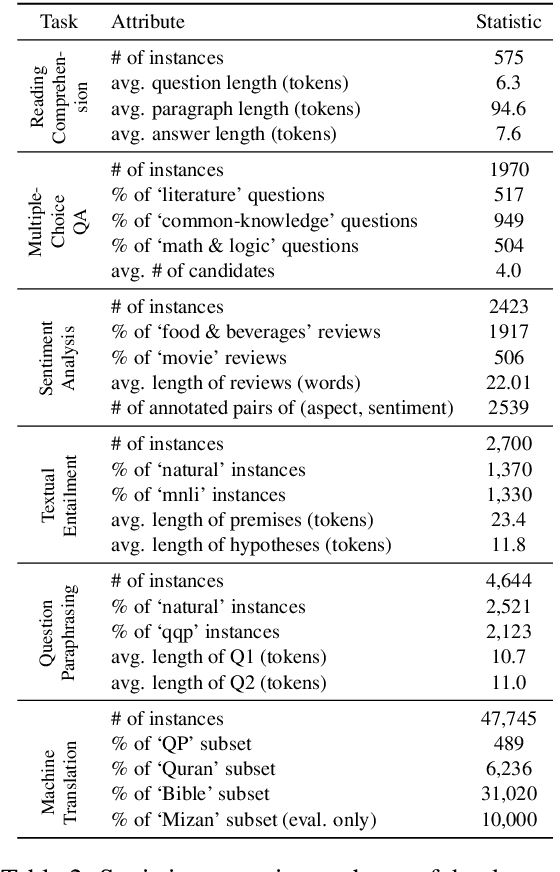
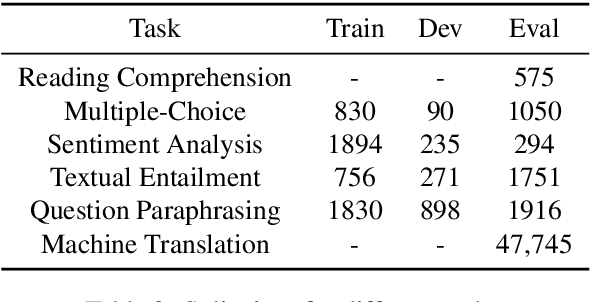
Despite the progress made in recent years in addressing natural language understanding (NLU) challenges, the majority of this progress remains to be concentrated on resource-rich languages like English. This work focuses on Persian language, one of the widely spoken languages in the world, and yet there are few NLU datasets available for this rich language. The availability of high-quality evaluation datasets is a necessity for reliable assessment of the progress on different NLU tasks and domains. We introduce ParsiNLU, the first benchmark in Persian language that includes a range of high-level tasks -- Reading Comprehension, Textual Entailment, etc. These datasets are collected in a multitude of ways, often involving manual annotations by native speakers. This results in over 14.5$k$ new instances across 6 distinct NLU tasks. Besides, we present the first results on state-of-the-art monolingual and multi-lingual pre-trained language-models on this benchmark and compare them with human performance, which provides valuable insights into our ability to tackle natural language understanding challenges in Persian. We hope ParsiNLU fosters further research and advances in Persian language understanding.