 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Large image datasets: A pyrrhic win for computer vision?
Jun 24, 2020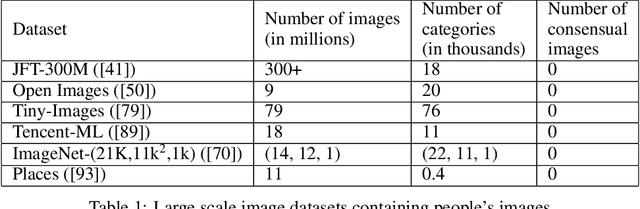
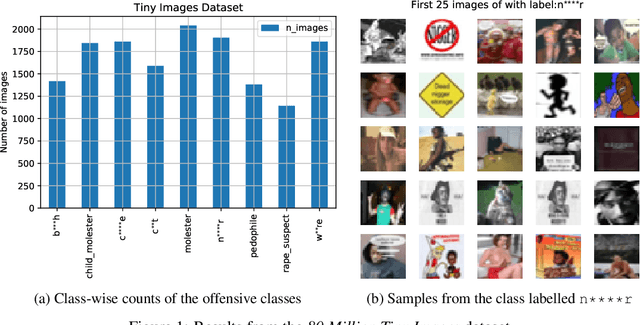

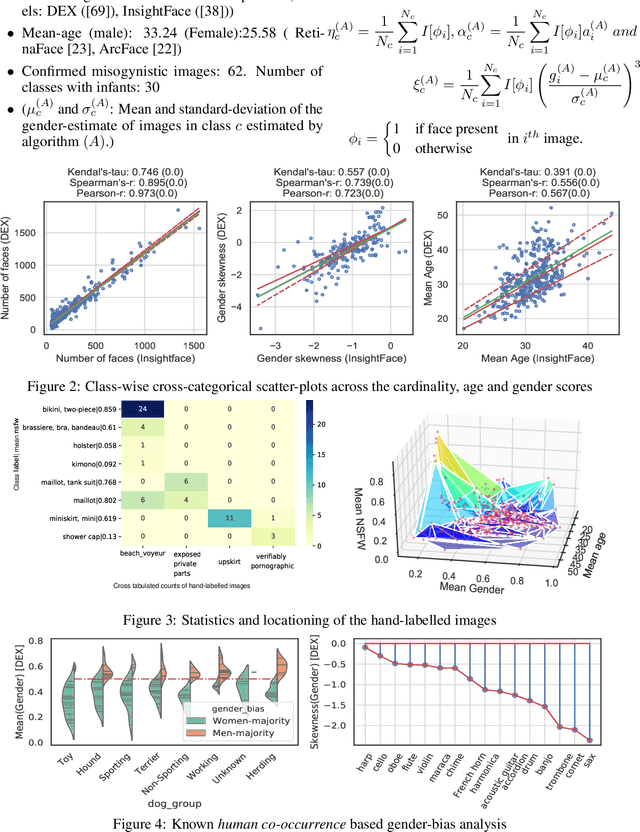
In this paper we investigate problematic practices and consequences of large scale vision datasets. We examine broad issues such as the question of consent and justice as well as specific concerns such as the inclusion of verifiably pornographic images in datasets. Taking the ImageNet-ILSVRC-2012 dataset as an example, we perform a cross-sectional model-based quantitative census covering factors such as age, gender, NSFW content scoring, class-wise accuracy, human-cardinality-analysis, and the semanticity of the image class information in order to statistically investigate the extent and subtleties of ethical transgressions. We then use the census to help hand-curate a look-up-table of images in the ImageNet-ILSVRC-2012 dataset that fall into the categories of verifiably pornographic: shot in a non-consensual setting (up-skirt), beach voyeuristic, and exposed private parts. We survey the landscape of harm and threats both society broadly and individuals face due to uncritical and ill-considered dataset curation practices. We then propose possible courses of correction and critique the pros and cons of these. We have duly open-sourced all of the code and the census meta-datasets generated in this endeavor for the computer vision community to build on. By unveiling the severity of the threats, our hope is to motivate the constitution of mandatory Institutional Review Boards (IRB) for large scale dataset curation processes.
Model Weight Theft With Just Noise Inputs: The Curious Case of the Petulant Attacker
Dec 19, 2019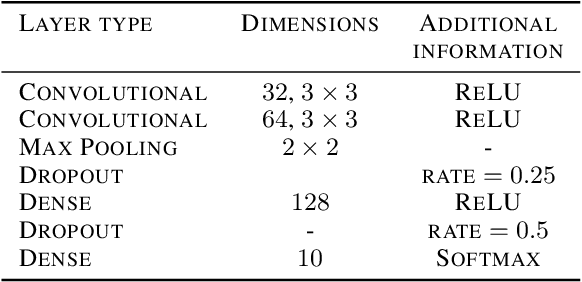
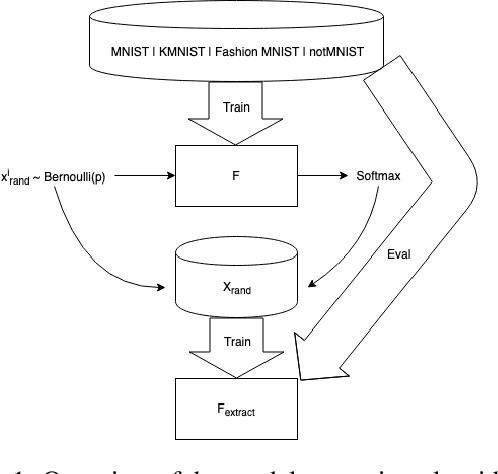

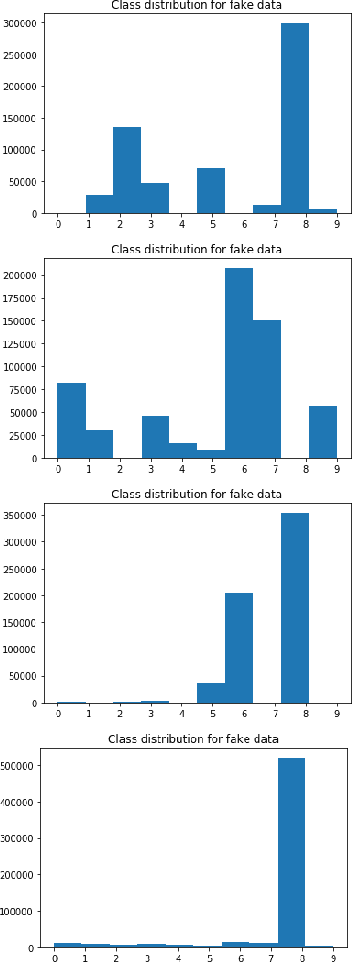
This paper explores the scenarios under which an attacker can claim that 'Noise and access to the softmax layer of the model is all you need' to steal the weights of a convolutional neural network whose architecture is already known. We were able to achieve 96% test accuracy using the stolen MNIST model and 82% accuracy using the stolen KMNIST model learned using only i.i.d. Bernoulli noise inputs. We posit that this theft-susceptibility of the weights is indicative of the complexity of the dataset and propose a new metric that captures the same. The goal of this dissemination is to not just showcase how far knowing the architecture can take you in terms of model stealing, but to also draw attention to this rather idiosyncratic weight learnability aspects of CNNs spurred by i.i.d. noise input. We also disseminate some initial results obtained with using the Ising probability distribution in lieu of the i.i.d. Bernoulli distribution.
Deep Connectomics Networks: Neural Network Architectures Inspired by Neuronal Networks
Dec 19, 2019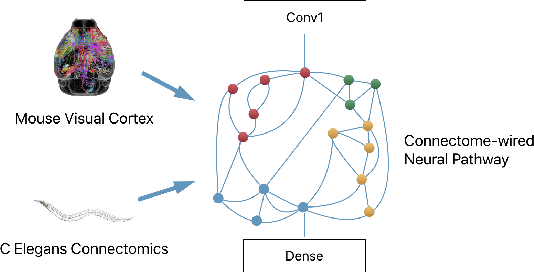
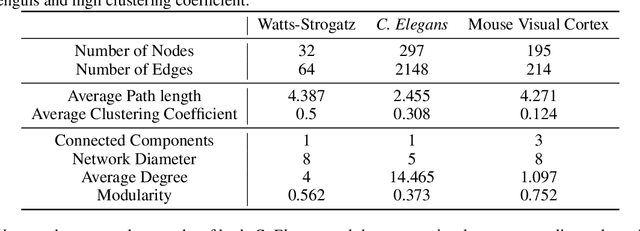
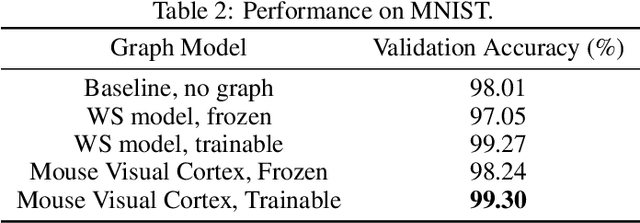
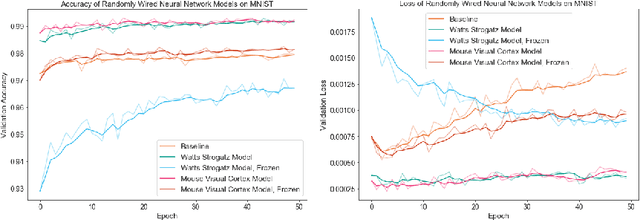
The interplay between inter-neuronal network topology and cognition has been studied deeply by connectomics researchers and network scientists, which is crucial towards understanding the remarkable efficacy of biological neural networks. Curiously, the deep learning revolution that revived neural networks has not paid much attention to topological aspects. The architectures of deep neural networks (DNNs) do not resemble their biological counterparts in the topological sense. We bridge this gap by presenting initial results of Deep Connectomics Networks (DCNs) as DNNs with topologies inspired by real-world neuronal networks. We show high classification accuracy obtained by DCNs whose architecture was inspired by the biological neuronal networks of C. Elegans and the mouse visual cortex.
Grassmannian Packings in Neural Networks: Learning with Maximal Subspace Packings for Diversity and Anti-Sparsity
Nov 18, 2019

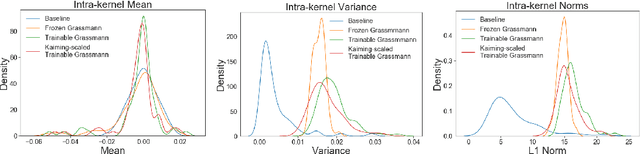
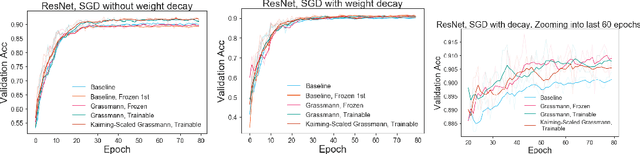
Kernel sparsity ("dying ReLUs") and lack of diversity are commonly observed in CNN kernels, which decreases model capacity. Drawing inspiration from information theory and wireless communications, we demonstrate the intersection of coding theory and deep learning through the Grassmannian subspace packing problem in CNNs. We propose Grassmannian packings for initial kernel layers to be initialized maximally far apart based on chordal or Fubini-Study distance. Convolutional kernels initialized with Grassmannian packings exhibit diverse features and obtain diverse representations. We show that Grassmannian packings, especially in the initial layers, address kernel sparsity and encourage diversity, while improving classification accuracy across shallow and deep CNNs with better convergence rates.
Kannada-MNIST: A new handwritten digits dataset for the Kannada language
Aug 03, 2019
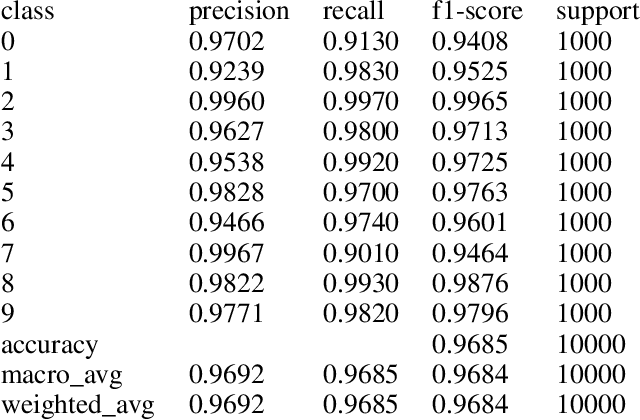

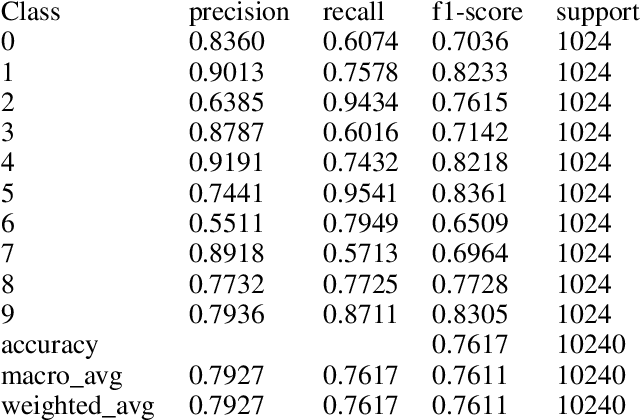
In this paper, we disseminate a new handwritten digits-dataset, termed Kannada-MNIST, for the Kannada script, that can potentially serve as a direct drop-in replacement for the original MNIST dataset. In addition to this dataset, we disseminate an additional real world handwritten dataset (with $10k$ images), which we term as the Dig-MNIST dataset that can serve as an out-of-domain test dataset. We also duly open source all the code as well as the raw scanned images along with the scanner settings so that researchers who want to try out different signal processing pipelines can perform end-to-end comparisons. We provide high level morphological comparisons with the MNIST dataset and provide baselines accuracies for the dataset disseminated. The initial baselines obtained using an oft-used CNN architecture ($96.8\%$ for the main test-set and $76.1\%$ for the Dig-MNIST test-set) indicate that these datasets do provide a sterner challenge with regards to generalizability than MNIST or the KMNIST datasets. We also hope this dissemination will spur the creation of similar datasets for all the languages that use different symbols for the numeral digits.
Understanding Adversarial Robustness Through Loss Landscape Geometries
Jul 22, 2019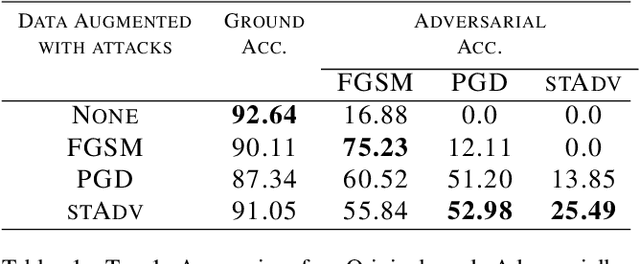
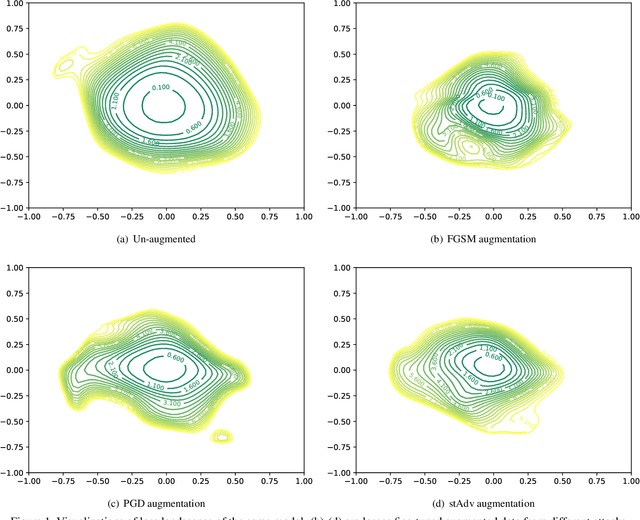

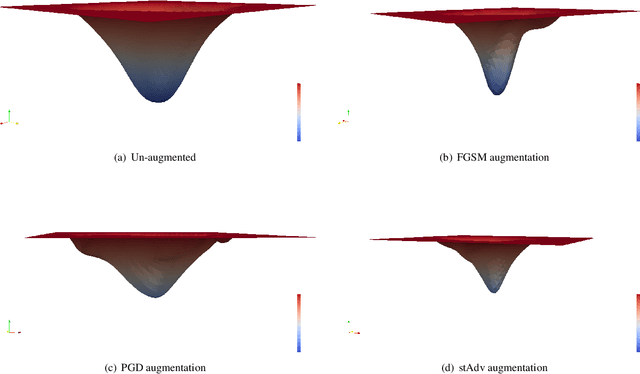
The pursuit of explaining and improving generalization in deep learning has elicited efforts both in regularization techniques as well as visualization techniques of the loss surface geometry. The latter is related to the intuition prevalent in the community that flatter local optima leads to lower generalization error. In this paper, we harness the state-of-the-art "filter normalization" technique of loss-surface visualization to qualitatively understand the consequences of using adversarial training data augmentation as the explicit regularization technique of choice. Much to our surprise, we discover that this oft deployed adversarial augmentation technique does not actually result in "flatter" loss-landscapes, which requires rethinking adversarial training generalization, and the relationship between generalization and loss landscapes geometries.
Covering up bias in CelebA-like datasets with Markov blankets: A post-hoc cure for attribute prior avoidance
Jul 22, 2019

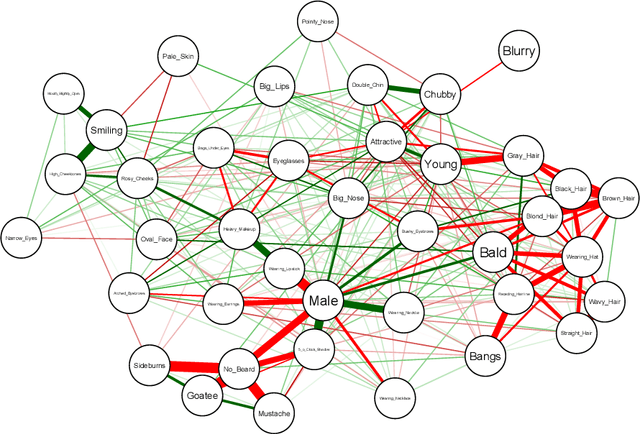
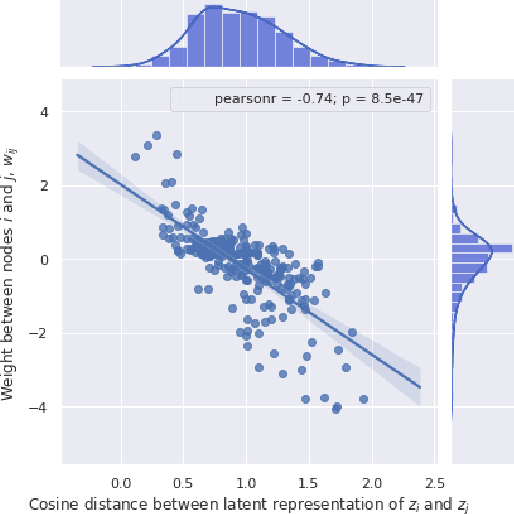
Attribute prior avoidance entails subconscious or willful non-modeling of (meta)attributes that datasets are oft born with, such as the 40 semantic facial attributes associated with the CelebA and CelebA-HQ datasets. The consequences of this infirmity, we discover, are especially stark in state-of-the-art deep generative models learned on these datasets that just model the pixel-space measurements, resulting in an inter-attribute bias-laden latent space. This viscerally manifests itself when we perform face manipulation experiments based on latent vector interpolations. In this paper, we address this and propose a post-hoc solution that utilizes an Ising attribute prior learned in the attribute space and showcase its efficacy via qualitative experiments.
Fonts-2-Handwriting: A Seed-Augment-Train framework for universal digit classification
May 16, 2019

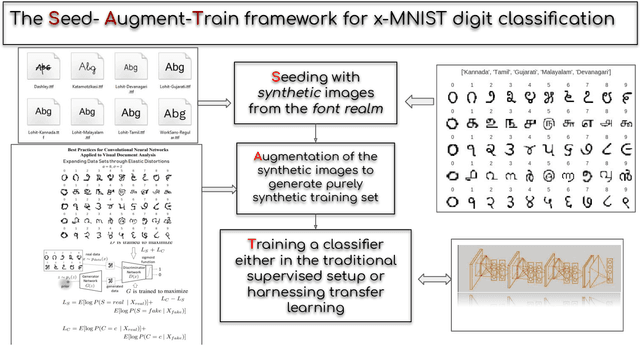

In this paper, we propose a Seed-Augment-Train/Transfer (SAT) framework that contains a synthetic seed image dataset generation procedure for languages with different numeral systems using freely available open font file datasets. This seed dataset of images is then augmented to create a purely synthetic training dataset, which is in turn used to train a deep neural network and test on held-out real world handwritten digits dataset spanning five Indic scripts, Kannada, Tamil, Gujarati, Malayalam, and Devanagari. We showcase the efficacy of this approach both qualitatively, by training a Boundary-seeking GAN (BGAN) that generates realistic digit images in the five languages, and also quantitatively by testing a CNN trained on the synthetic data on the real-world datasets. This establishes not only an interesting nexus between the font-datasets-world and transfer learning but also provides a recipe for universal-digit classification in any script.
On Lyapunov exponents and adversarial perturbation
Feb 20, 2018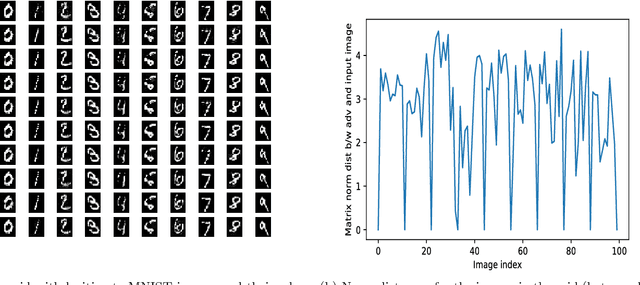
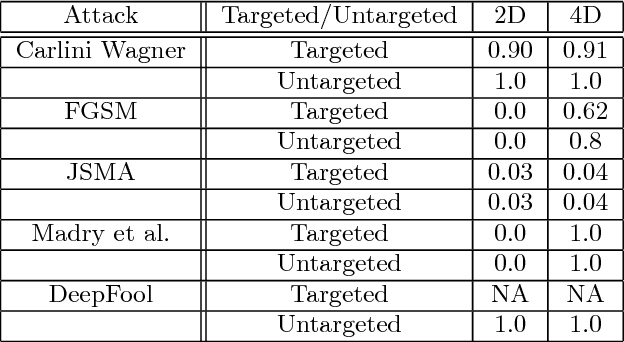

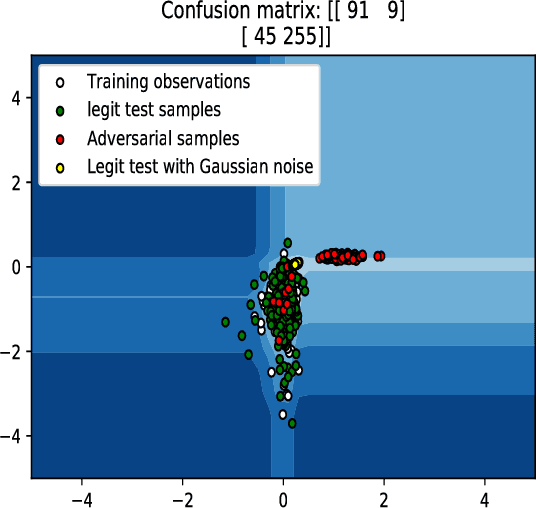
In this paper, we would like to disseminate a serendipitous discovery involving Lyapunov exponents of a 1-D time series and their use in serving as a filtering defense tool against a specific kind of deep adversarial perturbation. To this end, we use the state-of-the-art CleverHans library to generate adversarial perturbations against a standard Convolutional Neural Network (CNN) architecture trained on the MNIST as well as the Fashion-MNIST datasets. We empirically demonstrate how the Lyapunov exponents computed on the flattened 1-D vector representations of the images served as highly discriminative features that could be to pre-classify images as adversarial or legitimate before feeding the image into the CNN for classification. We also explore the issue of possible false-alarms when the input images are noisy in a non-adversarial sense.