 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Language Models Track Entities Across State Changes?
May 28, 2026Entity tracking (ET), the ability to keep track of states, is a fundamental skill that underlies complex reasoning. An increasing amount of work investigates how transformer language models (LMs) solve entity binding $\textit{without}$ state changes. However, there is limited understanding of how non-toy LMs address ET problems of realistic difficulties expressed in natural language. To this end, we investigate the mechanisms underlying ET in more complex scenarios featuring multiple state-changing operations. We find that LMs do not incrementally track world states across tokens or query-relevant states across layers, but simply aggregate relevant information in parallel at the last token when the query becomes evident. We further investigate mechanisms of individual operations ($\texttt{PUT}$, $\texttt{REMOVE}$, $\texttt{MOVE}$) to characterize this non-incremental ET mechanism. Surprisingly, LMs implement the $\texttt{REMOVE}$ operation with a fragile global suppression tag; this global removal mechanism predicts various failure modes that we confirm behaviorally. We provide a mechanistic solution of nullifying this tag to partially address this issue. Overall, our findings reveal that LMs solve a fundamentally sequential task using a non-sequential strategy. More broadly, our work illustrates how behavioral and mechanistic analyses can fruitfully interact. Behavioral results inform mechanistic hypotheses, and insights from mechanistic analyses help build stronger behavioral evaluations by predicting failure modes missing from existing evaluations.
Ask or Assume? Uncertainty-Aware Clarification-Seeking in Coding Agents
Mar 27, 2026As Large Language Model (LLM) agents are increasingly deployed in open-ended domains like software engineering, they frequently encounter underspecified instructions that lack crucial context. While human developers naturally resolve underspecification by asking clarifying questions, current agents are largely optimized for autonomous execution. In this work, we systematically evaluate the clarification-seeking abilities of LLM agents on an underspecified variant of SWE-bench Verified. We propose an uncertainty-aware multi-agent scaffold that explicitly decouples underspecification detection from code execution. Our results demonstrate that this multi-agent system using OpenHands + Claude Sonnet 4.5 achieves a 69.40% task resolve rate, significantly outperforming a standard single-agent setup (61.20%) and closing the performance gap with agents operating on fully specified instructions. Furthermore, we find that the multi-agent system exhibits well-calibrated uncertainty, conserving queries on simple tasks while proactively seeking information on more complex issues. These findings indicate that current models can be turned into proactive collaborators, where agents independently recognize when to ask questions to elicit missing information in real-world, underspecified tasks.
Diffusion LLMs can think EoS-by-EoS
Mar 05, 2026Diffusion LLMs have been proposed as an alternative to autoregressive LLMs, excelling especially at complex reasoning tasks with interdependent sub-goals. Curiously, this is particularly true if the generation length, i.e., the number of tokens the model has to output, is set to a much higher value than is required for providing the correct answer to the task, and the model pads its answer with end-of-sequence (EoS) tokens. We hypothesize that diffusion models think EoS-by-EoS, that is, they use the representations of EoS tokens as a hidden scratchpad, which allows them to solve harder reasoning problems. We experiment with the diffusion models LLaDA1.5, LLaDA2.0-mini, and Dream-v0 on the tasks Addition, Entity Tracking, and Sudoku. In a controlled prompting experiment, we confirm that adding EoS tokens improves the LLMs' reasoning capabilities. To further verify whether they serve as space for hidden computations, we patch the hidden states of the EoS tokens with those of a counterfactual generation, which frequently changes the generated output to the counterfactual. The success of the causal intervention underscores that the EoS tokens, which one may expect to be devoid of meaning, carry information on the problem to solve. The behavioral experiments and the causal interventions indicate that diffusion LLMs can indeed think EoS-by-EoS.
Code Pretraining Improves Entity Tracking Abilities of Language Models
May 31, 2024



Recent work has provided indirect evidence that pretraining language models on code improves the ability of models to track state changes of discourse entities expressed in natural language. In this work, we systematically test this claim by comparing pairs of language models on their entity tracking performance. Critically, the pairs consist of base models and models trained on top of these base models with additional code data. We extend this analysis to additionally examine the effect of math training, another highly structured data type, and alignment tuning, an important step for enhancing the usability of models. We find clear evidence that models additionally trained on large amounts of code outperform the base models. On the other hand, we find no consistent benefit of additional math training or alignment tuning across various model families.
Scope Ambiguities in Large Language Models
Apr 05, 2024Sentences containing multiple semantic operators with overlapping scope often create ambiguities in interpretation, known as scope ambiguities. These ambiguities offer rich insights into the interaction between semantic structure and world knowledge in language processing. Despite this, there has been little research into how modern large language models treat them. In this paper, we investigate how different versions of certain autoregressive language models -- GPT-2, GPT-3/3.5, Llama 2 and GPT-4 -- treat scope ambiguous sentences, and compare this with human judgments. We introduce novel datasets that contain a joint total of almost 1,000 unique scope-ambiguous sentences, containing interactions between a range of semantic operators, and annotated for human judgments. Using these datasets, we find evidence that several models (i) are sensitive to the meaning ambiguity in these sentences, in a way that patterns well with human judgments, and (ii) can successfully identify human-preferred readings at a high level of accuracy (over 90% in some cases).
Entity Tracking in Language Models
May 03, 2023



Keeping track of how states and relations of entities change as a text or dialog unfolds is a key prerequisite to discourse understanding. Despite this fact, there have been few systematic investigations into the ability of large language models (LLMs) to track discourse entities. In this work, we present a task to probe to what extent a language model can infer the final state of an entity given an English description of the initial state and a series of state-changing operations. We use this task to first investigate whether Flan-T5, GPT-3 and GPT-3.5 can track the state of entities, and find that only GPT-3.5 models, which have been pretrained on large amounts of code, exhibit this ability. We then investigate whether smaller models pretrained primarily on text can learn to track entities, through finetuning T5 on several training/evaluation splits. While performance degrades for more complex splits, we find that even for splits with almost no lexical overlap between training and evaluation, a finetuned model can often perform non-trivial entity tracking. Taken together, these results suggest that language models can learn to track entities but pretraining on large text corpora alone does not make this capacity surface.
Expectations over Unspoken Alternatives Predict Pragmatic Inferences
Apr 07, 2023Scalar inferences (SI) are a signature example of how humans interpret language based on unspoken alternatives. While empirical studies have demonstrated that human SI rates are highly variable -- both within instances of a single scale, and across different scales -- there have been few proposals that quantitatively explain both cross- and within-scale variation. Furthermore, while it is generally assumed that SIs arise through reasoning about unspoken alternatives, it remains debated whether humans reason about alternatives as linguistic forms, or at the level of concepts. Here, we test a shared mechanism explaining SI rates within and across scales: context-driven expectations about the unspoken alternatives. Using neural language models to approximate human predictive distributions, we find that SI rates are captured by the expectedness of the strong scalemate as an alternative. Crucially, however, expectedness robustly predicts cross-scale variation only under a meaning-based view of alternatives. Our results suggest that pragmatic inferences arise from context-driven expectations over alternatives, and these expectations operate at the level of concepts.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
When a sentence does not introduce a discourse entity, Transformer-based models still sometimes refer to it
May 06, 2022
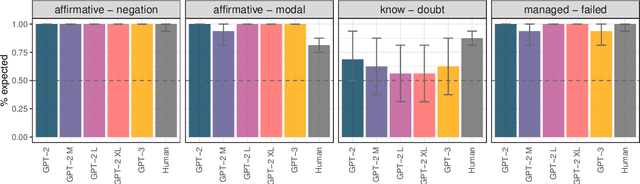
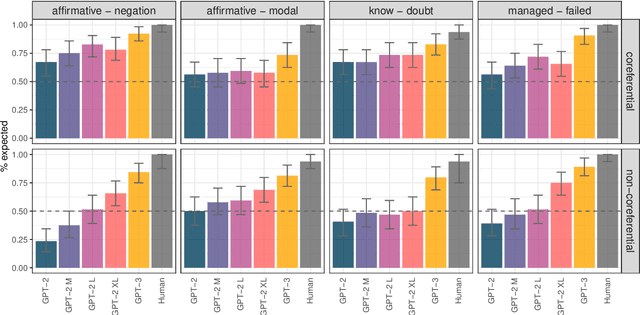

Understanding longer narratives or participating in conversations requires tracking of discourse entities that have been mentioned. Indefinite noun phrases (NPs), such as 'a dog', frequently introduce discourse entities but this behavior is modulated by sentential operators such as negation. For example, 'a dog' in 'Arthur doesn't own a dog' does not introduce a discourse entity due to the presence of negation. In this work, we adapt the psycholinguistic assessment of language models paradigm to higher-level linguistic phenomena and introduce an English evaluation suite that targets the knowledge of the interactions between sentential operators and indefinite NPs. We use this evaluation suite for a fine-grained investigation of the entity tracking abilities of the Transformer-based models GPT-2 and GPT-3. We find that while the models are to a certain extent sensitive to the interactions we investigate, they are all challenged by the presence of multiple NPs and their behavior is not systematic, which suggests that even models at the scale of GPT-3 do not fully acquire basic entity tracking abilities.
Coloring the Blank Slate: Pre-training Imparts a Hierarchical Inductive Bias to Sequence-to-sequence Models
Mar 17, 2022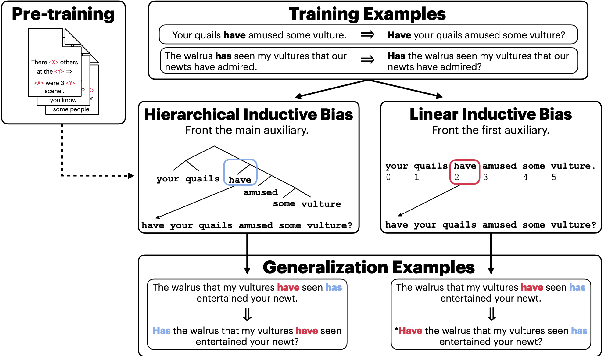


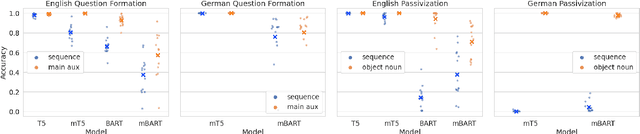
Relations between words are governed by hierarchical structure rather than linear ordering. Sequence-to-sequence (seq2seq) models, despite their success in downstream NLP applications, often fail to generalize in a hierarchy-sensitive manner when performing syntactic transformations - for example, transforming declarative sentences into questions. However, syntactic evaluations of seq2seq models have only observed models that were not pre-trained on natural language data before being trained to perform syntactic transformations, in spite of the fact that pre-training has been found to induce hierarchical linguistic generalizations in language models; in other words, the syntactic capabilities of seq2seq models may have been greatly understated. We address this gap using the pre-trained seq2seq models T5 and BART, as well as their multilingual variants mT5 and mBART. We evaluate whether they generalize hierarchically on two transformations in two languages: question formation and passivization in English and German. We find that pre-trained seq2seq models generalize hierarchically when performing syntactic transformations, whereas models trained from scratch on syntactic transformations do not. This result presents evidence for the learnability of hierarchical syntactic information from non-annotated natural language text while also demonstrating that seq2seq models are capable of syntactic generalization, though only after exposure to much more language data than human learners receive.