 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArgument Reconstruction as Supervision for Critical Thinking in LLMs
Mar 18, 2026To think critically about arguments, human learners are trained to identify, reconstruct, and evaluate arguments. Argument reconstruction is especially important because it makes an argument's underlying inferences explicit. However, it remains unclear whether LLMs can similarly enhance their critical thinking ability by learning to reconstruct arguments. To address this question, we introduce a holistic framework with three contributions. We (1) propose an engine that automatically reconstructs arbitrary arguments (GAAR), (2) synthesize a new high-quality argument reconstruction dataset (Arguinas) using the GAAR engine, and (3) investigate whether learning argument reconstruction benefits downstream critical thinking tasks. Our experimental results show that, across seven critical thinking tasks, models trained to learn argument reconstruction outperform models that do not, with the largest performance gains observed when training on the proposed Arguinas dataset. The source code and dataset will be publicly available.
Guided Reasoning: A Non-Technical Introduction
Aug 29, 2024We introduce the concept and a default implementation of Guided Reasoning. A multi-agent system is a Guided Reasoning system iff one agent (the guide) primarily interacts with other agents in order to improve reasoning quality. We describe Logikon's default implementation of Guided Reasoning in non-technical terms. This is a living document we'll gradually enrich with more detailed information and examples. Code: https://github.com/logikon-ai/logikon
Heuristic Algorithms for the Approximation of Mutual Coherence
Jul 04, 2023Mutual coherence is a measure of similarity between two opinions. Although the notion comes from philosophy, it is essential for a wide range of technologies, e.g., the Wahl-O-Mat system. In Germany, this system helps voters to find candidates that are the closest to their political preferences. The exact computation of mutual coherence is highly time-consuming due to the iteration over all subsets of an opinion. Moreover, for every subset, an instance of the SAT model counting problem has to be solved which is known to be a hard problem in computer science. This work is the first study to accelerate this computation. We model the distribution of the so-called confirmation values as a mixture of three Gaussians and present efficient heuristics to estimate its model parameters. The mutual coherence is then approximated with the expected value of the distribution. Some of the presented algorithms are fully polynomial-time, others only require solving a small number of instances of the SAT model counting problem. The average squared error of our best algorithm lies below 0.0035 which is insignificant if the efficiency is taken into account. Furthermore, the accuracy is precise enough to be used in Wahl-O-Mat-like systems.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
DeepA2: A Modular Framework for Deep Argument Analysis with Pretrained Neural Text2Text Language Models
Oct 04, 2021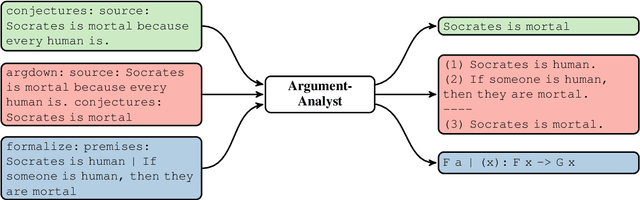
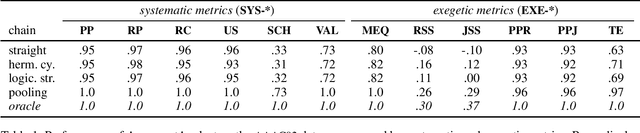
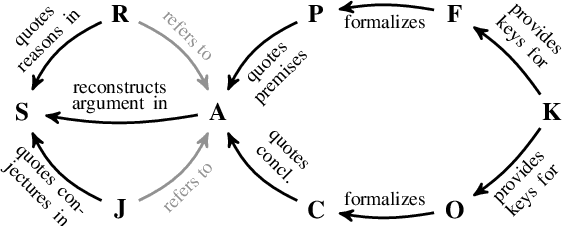
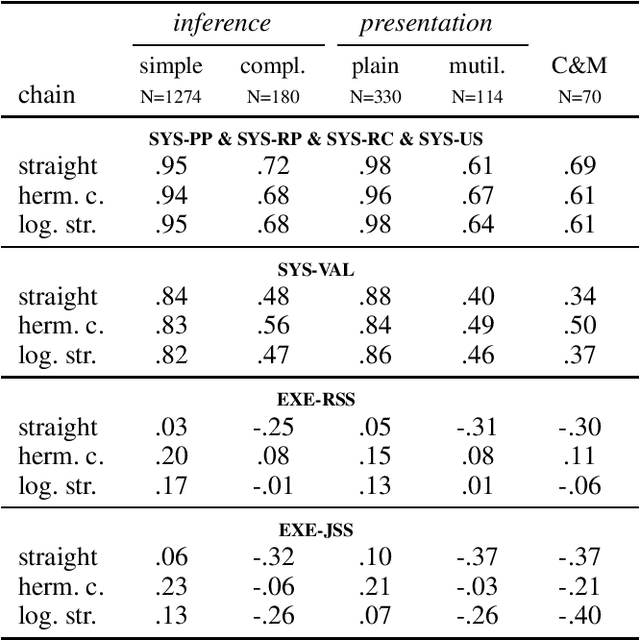
In this paper, we present and implement a multi-dimensional, modular framework for performing deep argument analysis (DeepA2) using current pre-trained language models (PTLMs). ArgumentAnalyst -- a T5 model (Raffel et al. 2020) set up and trained within DeepA2 -- reconstructs argumentative texts, which advance an informal argumentation, as valid arguments: It inserts, e.g., missing premises and conclusions, formalizes inferences, and coherently links the logical reconstruction to the source text. We create a synthetic corpus for deep argument analysis, and evaluate ArgumentAnalyst on this new dataset as well as on existing data, specifically EntailmentBank (Dalvi et al. 2021). Our empirical findings vindicate the overall framework and highlight the advantages of a modular design, in particular its ability to emulate established heuristics (such as hermeneutic cycles), to explore the model's uncertainty, to cope with the plurality of correct solutions (underdetermination), and to exploit higher-order evidence.
Natural-Language Multi-Agent Simulations of Argumentative Opinion Dynamics
Apr 14, 2021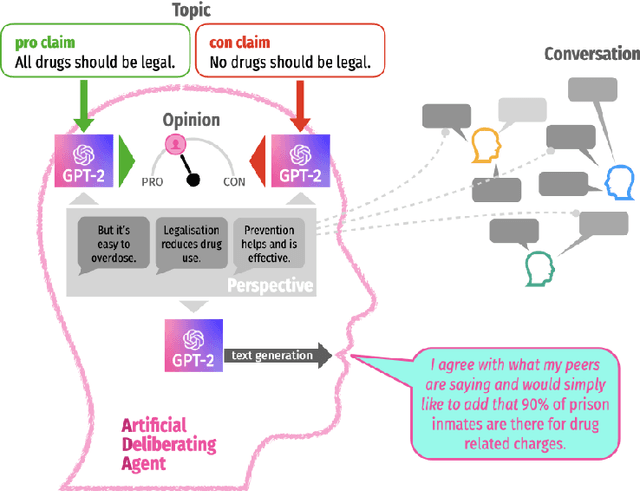
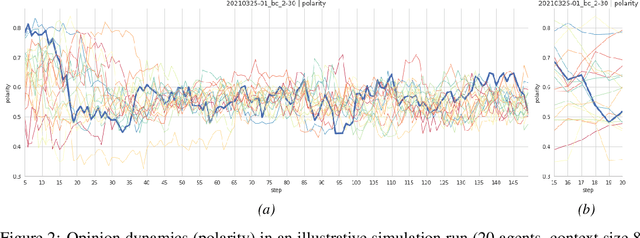
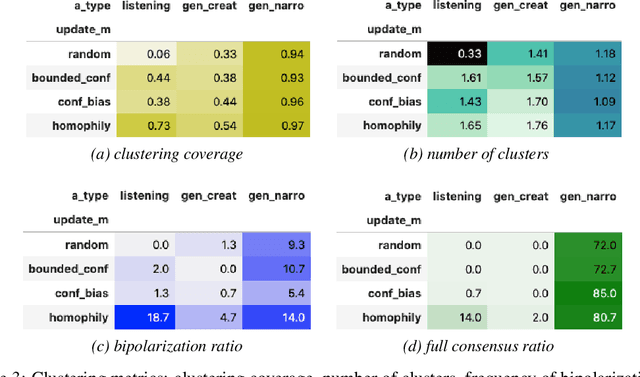

This paper develops a natural-language agent-based model of argumentation (ABMA). Its artificial deliberative agents (ADAs) are constructed with the help of so-called neural language models recently developed in AI and computational linguistics. ADAs are equipped with a minimalist belief system and may generate and submit novel contributions to a conversation. The natural-language ABMA allows us to simulate collective deliberation in English, i.e. with arguments, reasons, and claims themselves -- rather than with their mathematical representations (as in formal models). This paper uses the natural-language ABMA to test the robustness of formal reason-balancing models of argumentation [Maes & Flache 2013, Singer et al. 2019]: First of all, as long as ADAs remain passive, confirmation bias and homophily updating trigger polarization, which is consistent with results from formal models. However, once ADAs start to actively generate new contributions, the evolution of a conservation is dominated by properties of the agents *as authors*. This suggests that the creation of new arguments, reasons, and claims critically affects a conversation and is of pivotal importance for understanding the dynamics of collective deliberation. The paper closes by pointing out further fruitful applications of the model and challenges for future research.
Thinking Aloud: Dynamic Context Generation Improves Zero-Shot Reasoning Performance of GPT-2
Mar 24, 2021

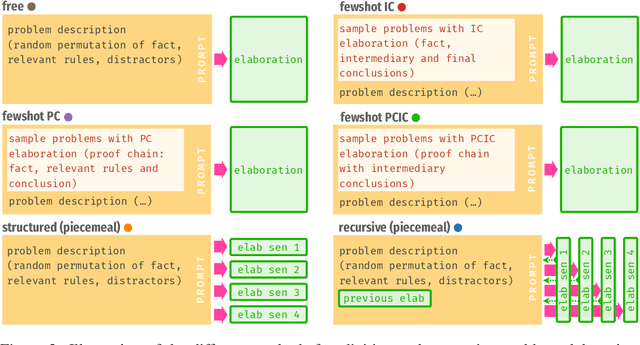
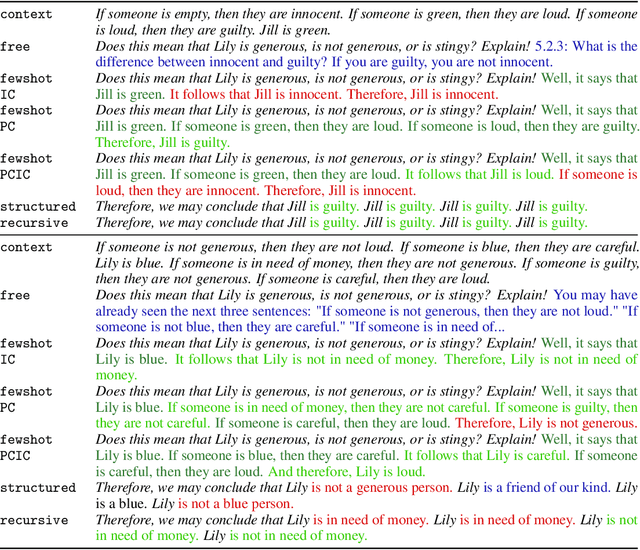
Thinking aloud is an effective meta-cognitive strategy human reasoners apply to solve difficult problems. We suggest to improve the reasoning ability of pre-trained neural language models in a similar way, namely by expanding a task's context with problem elaborations that are dynamically generated by the language model itself. Our main result is that dynamic problem elaboration significantly improves the zero-shot performance of GPT-2 in a deductive reasoning and natural language inference task: While the model uses a syntactic heuristic for predicting an answer, it is capable (to some degree) of generating reasoned additional context which facilitates the successful application of its heuristic. We explore different ways of generating elaborations, including fewshot learning, and find that their relative performance varies with the specific problem characteristics (such as problem difficulty). Moreover, the effectiveness of an elaboration can be explained in terms of the degree to which the elaboration semantically coheres with the corresponding problem. In particular, elaborations that are most faithful to the original problem description may boost accuracy by up to 24%.
Critical Thinking for Language Models
Sep 15, 2020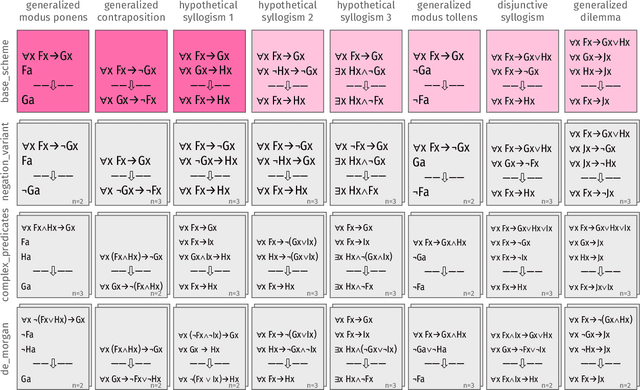
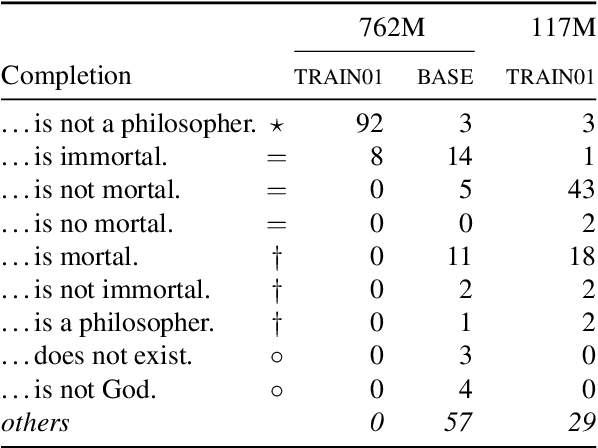
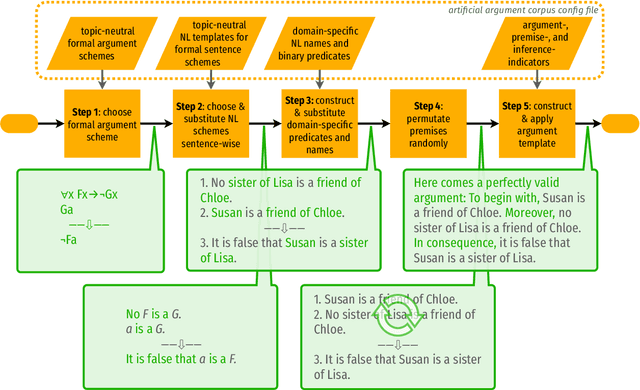
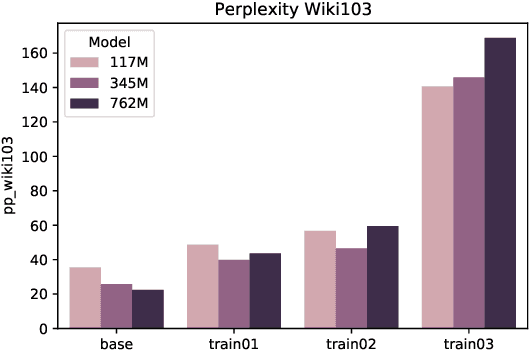
This paper takes a first step towards a critical thinking curriculum for neural auto-regressive language models. We introduce a synthetic text corpus of deductively valid arguments, and use this artificial argument corpus to train and evaluate GPT-2. Significant transfer learning effects can be observed: Training a model on a few simple core schemes allows it to accurately complete conclusions of different, and more complex types of arguments, too. The language models seem to connect and generalize the core argument schemes in a correct way. Moreover, we obtain consistent and promising results for the GLUE and SNLI benchmarks. The findings suggest that there might exist a representative sample of paradigmatic instances of good reasoning that will suffice to acquire general reasoning skills and that might form the core of a critical thinking curriculum for language models.