 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuron Populations Exhibit Divergent Selectivity with Scale
Jun 02, 2026We investigate whether neuron populations within neural networks evolve predictably with scale, extending scaling laws beyond macroscopic observables such as loss. To probe this question, we study Rosetta Neurons, a previously characterized class of neurons whose activation patterns are similar across independently trained models (Dravid et al., 2023). In separate analyses of language models up to 30B parameters and vision models up to 5B parameters, we observe that the population of Rosetta Neurons follows a sublinear power law in model size, growing in absolute number but occupying a shrinking fraction of the total neuron count. We further observe a Neuron Polarization Effect: Rosetta Neurons become more selective and increasingly monosemantic with scale, separating from a growing non-Rosetta population that remains less selective. An analytical model balancing feature utility against limited neuron capacity explains the sublinear power-law scaling and this polarization effect. Finally, we find that Rosetta Neurons become more domain-specialized with scale and illustrate their selectivity through a targeted data-filtering case study for continued pretraining. Our results point to a scaling law for interpretable, shared neuron-level structure, linking model size to systematic changes in neuron universality, selectivity, and specialization.
Symmetry in language statistics shapes the geometry of model representations
Feb 16, 2026Although learned representations underlie neural networks' success, their fundamental properties remain poorly understood. A striking example is the emergence of simple geometric structures in LLM representations: for example, calendar months organize into a circle, years form a smooth one-dimensional manifold, and cities' latitudes and longitudes can be decoded by a linear probe. We show that the statistics of language exhibit a translation symmetry -- e.g., the co-occurrence probability of two months depends only on the time interval between them -- and we prove that the latter governs the aforementioned geometric structures in high-dimensional word embedding models. Moreover, we find that these structures persist even when the co-occurrence statistics are strongly perturbed (for example, by removing all sentences in which two months appear together) and at moderate embedding dimension. We show that this robustness naturally emerges if the co-occurrence statistics are collectively controlled by an underlying continuous latent variable. We empirically validate this theoretical framework in word embedding models, text embedding models, and large language models.
Context Structure Reshapes the Representational Geometry of Language Models
Jan 29, 2026Large Language Models (LLMs) have been shown to organize the representations of input sequences into straighter neural trajectories in their deep layers, which has been hypothesized to facilitate next-token prediction via linear extrapolation. Language models can also adapt to diverse tasks and learn new structure in context, and recent work has shown that this in-context learning (ICL) can be reflected in representational changes. Here we bring these two lines of research together to explore whether representation straightening occurs \emph{within} a context during ICL. We measure representational straightening in Gemma 2 models across a diverse set of in-context tasks, and uncover a dichotomy in how LLMs' representations change in context. In continual prediction settings (e.g., natural language, grid world traversal tasks) we observe that increasing context increases the straightness of neural sequence trajectories, which is correlated with improvement in model prediction. Conversely, in structured prediction settings (e.g., few-shot tasks), straightening is inconsistent -- it is only present in phases of the task with explicit structure (e.g., repeating a template), but vanishes elsewhere. These results suggest that ICL is not a monolithic process. Instead, we propose that LLMs function like a Swiss Army knife: depending on task structure, the LLM dynamically selects between strategies, only some of which yield representational straightening.
On the Emergence of Linear Analogies in Word Embeddings
May 24, 2025Models such as Word2Vec and GloVe construct word embeddings based on the co-occurrence probability $P(i,j)$ of words $i$ and $j$ in text corpora. The resulting vectors $W_i$ not only group semantically similar words but also exhibit a striking linear analogy structure -- for example, $W_{\text{king}} - W_{\text{man}} + W_{\text{woman}} \approx W_{\text{queen}}$ -- whose theoretical origin remains unclear. Previous observations indicate that this analogy structure: (i) already emerges in the top eigenvectors of the matrix $M(i,j) = P(i,j)/P(i)P(j)$, (ii) strengthens and then saturates as more eigenvectors of $M (i, j)$, which controls the dimension of the embeddings, are included, (iii) is enhanced when using $\log M(i,j)$ rather than $M(i,j)$, and (iv) persists even when all word pairs involved in a specific analogy relation (e.g., king-queen, man-woman) are removed from the corpus. To explain these phenomena, we introduce a theoretical generative model in which words are defined by binary semantic attributes, and co-occurrence probabilities are derived from attribute-based interactions. This model analytically reproduces the emergence of linear analogy structure and naturally accounts for properties (i)-(iv). It can be viewed as giving fine-grained resolution into the role of each additional embedding dimension. It is robust to various forms of noise and agrees well with co-occurrence statistics measured on Wikipedia and the analogy benchmark introduced by Mikolov et al.
Quantum Many-Body Physics Calculations with Large Language Models
Mar 05, 2024



Large language models (LLMs) have demonstrated an unprecedented ability to perform complex tasks in multiple domains, including mathematical and scientific reasoning. We demonstrate that with carefully designed prompts, LLMs can accurately carry out key calculations in research papers in theoretical physics. We focus on a broadly used approximation method in quantum physics: the Hartree-Fock method, requiring an analytic multi-step calculation deriving approximate Hamiltonian and corresponding self-consistency equations. To carry out the calculations using LLMs, we design multi-step prompt templates that break down the analytic calculation into standardized steps with placeholders for problem-specific information. We evaluate GPT-4's performance in executing the calculation for 15 research papers from the past decade, demonstrating that, with correction of intermediate steps, it can correctly derive the final Hartree-Fock Hamiltonian in 13 cases and makes minor errors in 2 cases. Aggregating across all research papers, we find an average score of 87.5 (out of 100) on the execution of individual calculation steps. Overall, the requisite skill for doing these calculations is at the graduate level in quantum condensed matter theory. We further use LLMs to mitigate the two primary bottlenecks in this evaluation process: (i) extracting information from papers to fill in templates and (ii) automatic scoring of the calculation steps, demonstrating good results in both cases. The strong performance is the first step for developing algorithms that automatically explore theoretical hypotheses at an unprecedented scale.
Les Houches Lectures on Deep Learning at Large & Infinite Width
Sep 08, 2023These lectures, presented at the 2022 Les Houches Summer School on Statistical Physics and Machine Learning, focus on the infinite-width limit and large-width regime of deep neural networks. Topics covered include various statistical and dynamical properties of these networks. In particular, the lecturers discuss properties of random deep neural networks; connections between trained deep neural networks, linear models, kernels, and Gaussian processes that arise in the infinite-width limit; and perturbative and non-perturbative treatments of large but finite-width networks, at initialization and after training.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
The Evolution of Out-of-Distribution Robustness Throughout Fine-Tuning
Jun 30, 2021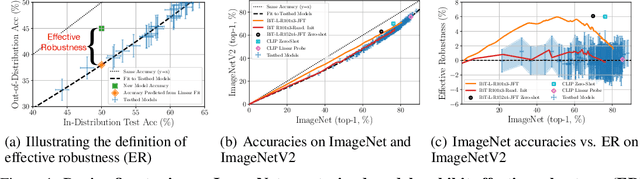

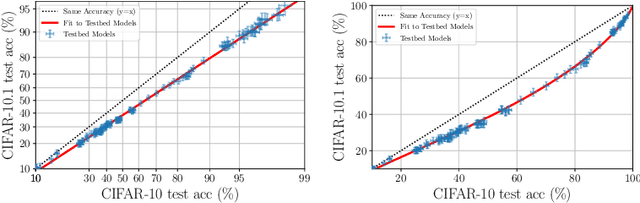

Although machine learning models typically experience a drop in performance on out-of-distribution data, accuracies on in- versus out-of-distribution data are widely observed to follow a single linear trend when evaluated across a testbed of models. Models that are more accurate on the out-of-distribution data relative to this baseline exhibit "effective robustness" and are exceedingly rare. Identifying such models, and understanding their properties, is key to improving out-of-distribution performance. We conduct a thorough empirical investigation of effective robustness during fine-tuning and surprisingly find that models pre-trained on larger datasets exhibit effective robustness during training that vanishes at convergence. We study how properties of the data influence effective robustness, and we show that it increases with the larger size, more diversity, and higher example difficulty of the dataset. We also find that models that display effective robustness are able to correctly classify 10% of the examples that no other current testbed model gets correct. Finally, we discuss several strategies for scaling effective robustness to the high-accuracy regime to improve the out-of-distribution accuracy of state-of-the-art models.
Explaining Neural Scaling Laws
Feb 12, 2021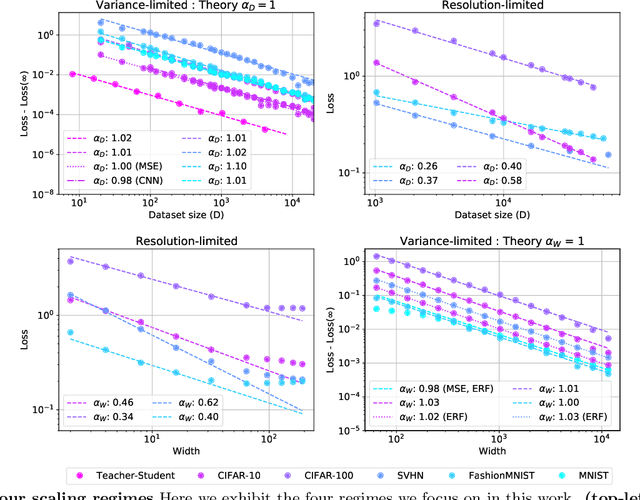
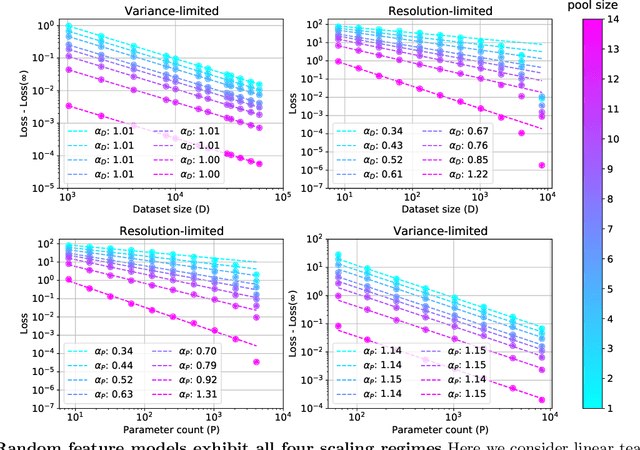
The test loss of well-trained neural networks often follows precise power-law scaling relations with either the size of the training dataset or the number of parameters in the network. We propose a theory that explains and connects these scaling laws. We identify variance-limited and resolution-limited scaling behavior for both dataset and model size, for a total of four scaling regimes. The variance-limited scaling follows simply from the existence of a well-behaved infinite data or infinite width limit, while the resolution-limited regime can be explained by positing that models are effectively resolving a smooth data manifold. In the large width limit, this can be equivalently obtained from the spectrum of certain kernels, and we present evidence that large width and large dataset resolution-limited scaling exponents are related by a duality. We exhibit all four scaling regimes in the controlled setting of large random feature and pretrained models and test the predictions empirically on a range of standard architectures and datasets. We also observe several empirical relationships between datasets and scaling exponents: super-classing image tasks does not change exponents, while changing input distribution (via changing datasets or adding noise) has a strong effect. We further explore the effect of architecture aspect ratio on scaling exponents.
Exact posterior distributions of wide Bayesian neural networks
Jun 18, 2020
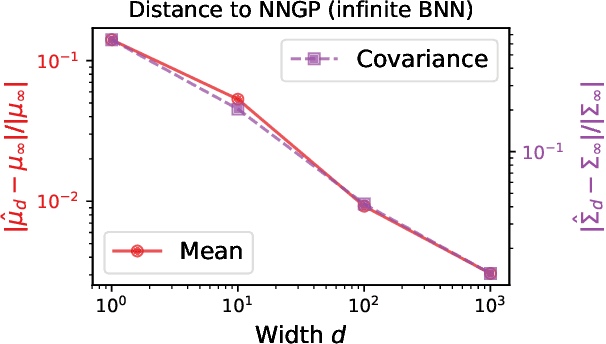
Recent work has shown that the prior over functions induced by a deep Bayesian neural network (BNN) behaves as a Gaussian process (GP) as the width of all layers becomes large. However, many BNN applications are concerned with the BNN function space posterior. While some empirical evidence of the posterior convergence was provided in the original works of Neal (1996) and Matthews et al. (2018), it is limited to small datasets or architectures due to the notorious difficulty of obtaining and verifying exactness of BNN posterior approximations. We provide the missing theoretical proof that the exact BNN posterior converges (weakly) to the one induced by the GP limit of the prior. For empirical validation, we show how to generate exact samples from a finite BNN on a small dataset via rejection sampling.