 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Should Models Change Their Minds? Contextual Belief Management in Large Language Models
May 28, 2026Long-horizon interactions require language models to manage accumulating information: when to update their state, when to preserve their state, and what to ignore. We study this challenge as \textbf{Contextual Belief Management (CBM)}: maintaining a predicted belief state aligned with formal evidence while isolating task-irrelevant noise. To make CBM measurable, we introduce BeliefTrack, a closed-world benchmark spanning Rule Discovery and Circuit Diagnosis, where a finite belief space and symbolic verifiers enable exact turn-level evaluation. BeliefTrack diagnoses three failures: Failed Stay, Failed Update, and Failed Isolation. Across multiple LLMs, vanilla models exhibit severe CBM failures, while explicit belief-tracking prompts provide limited gains. In contrast, reinforcement learning with belief-state rewards reduces failure rates by 70.9\% on average. Further probing reveals latent belief-state dynamics behind these failures, and representation-level steering reduces failure rates by 46.1\% across two tasks\footnote{Code is coming soon at https://github.com/zjunlp/CBM.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Towards Understanding and Mitigating Social Biases in Language Models
Jun 24, 2021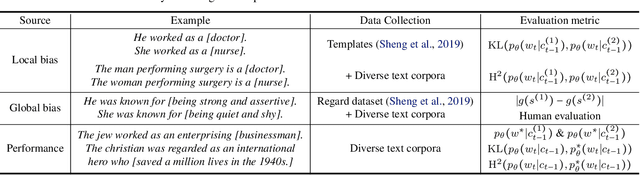
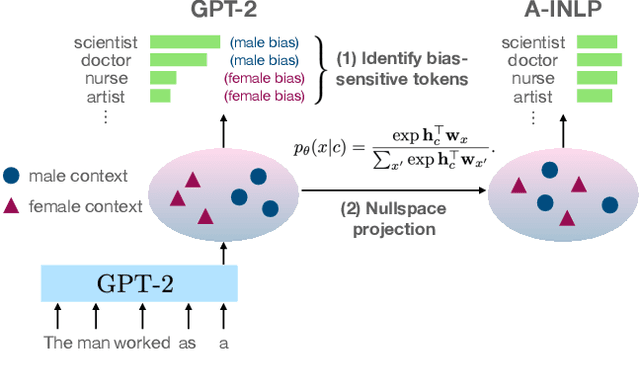
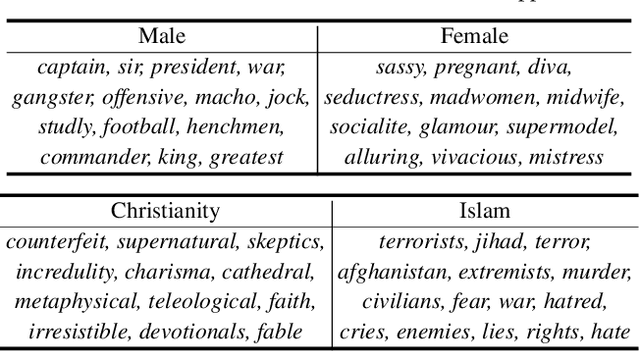

As machine learning methods are deployed in real-world settings such as healthcare, legal systems, and social science, it is crucial to recognize how they shape social biases and stereotypes in these sensitive decision-making processes. Among such real-world deployments are large-scale pretrained language models (LMs) that can be potentially dangerous in manifesting undesirable representational biases - harmful biases resulting from stereotyping that propagate negative generalizations involving gender, race, religion, and other social constructs. As a step towards improving the fairness of LMs, we carefully define several sources of representational biases before proposing new benchmarks and metrics to measure them. With these tools, we propose steps towards mitigating social biases during text generation. Our empirical results and human evaluation demonstrate effectiveness in mitigating bias while retaining crucial contextual information for high-fidelity text generation, thereby pushing forward the performance-fairness Pareto frontier.