 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Merging via Data-Free Covariance Estimation
Apr 01, 2026Model merging provides a way of cheaply combining individual models to produce a model that inherits each individual's capabilities. While some merging methods can approach the performance of multitask training, they are often heuristically motivated and lack theoretical justification. A principled alternative is to pose model merging as a layer-wise optimization problem that directly minimizes interference between tasks. However, this formulation requires estimating per-layer covariance matrices from data, which may not be available when performing merging. In contrast, many of the heuristically-motivated methods do not require auxiliary data, making them practically advantageous. In this work, we revisit the interference minimization framework and show that, under certain conditions, covariance matrices can be estimated directly from difference matrices, eliminating the need for data while also reducing computational costs. We validate our approach across vision and language benchmarks on models ranging from 86M parameters to 7B parameters, outperforming previous data-free state-of-the-art merging methods
Realistic Evaluation of Model Merging for Compositional Generalization
Sep 26, 2024Merging has become a widespread way to cheaply combine individual models into a single model that inherits their capabilities and attains better performance. This popularity has spurred rapid development of many new merging methods, which are typically validated in disparate experimental settings and frequently differ in the assumptions made about model architecture, data availability, and computational budget. In this work, we characterize the relative merits of different merging methods by evaluating them in a shared experimental setting and precisely identifying the practical requirements of each method. Specifically, our setting focuses on using merging for compositional generalization of capabilities in image classification, image generation, and natural language processing. Additionally, we measure the computational costs of different merging methods as well as how they perform when scaling the number of models being merged. Taken together, our results clarify the state of the field of model merging and provide a comprehensive and rigorous experimental setup to test new methods.
Merging by Matching Models in Task Subspaces
Dec 07, 2023



Model merging aims to cheaply combine individual task-specific models into a single multitask model. In this work, we view past merging methods as leveraging different notions of a ''task subspace'' in which models are matched before being merged. We connect the task subspace of a given model to its loss landscape and formalize how this approach to model merging can be seen as solving a linear system of equations. While past work has generally been limited to linear systems that have a closed-form solution, we consider using the conjugate gradient method to find a solution. We show that using the conjugate gradient method can outperform closed-form solutions, enables merging via linear systems that are otherwise intractable to solve, and flexibly allows choosing from a wide variety of initializations and estimates for the ''task subspace''. We ultimately demonstrate that our merging framework called ''Matching Models in their Task Subspace'' (MaTS) achieves state-of-the-art results in multitask and intermediate-task model merging. We release all of the code and checkpoints used in our work at https://github.com/r-three/mats.
Resolving Interference When Merging Models
Jun 02, 2023



Transfer learning - i.e., further fine-tuning a pre-trained model on a downstream task - can confer significant advantages, including improved downstream performance, faster convergence, and better sample efficiency. These advantages have led to a proliferation of task-specific fine-tuned models, which typically can only perform a single task and do not benefit from one another. Recently, model merging techniques have emerged as a solution to combine multiple task-specific models into a single multitask model without performing additional training. However, existing merging methods often ignore the interference between parameters of different models, resulting in large performance drops when merging multiple models. In this paper, we demonstrate that prior merging techniques inadvertently lose valuable information due to two major sources of interference: (a) interference due to redundant parameter values and (b) disagreement on the sign of a given parameter's values across models. To address this, we propose our method, TrIm, Elect Sign & Merge (TIES-Merging), which introduces three novel steps when merging models: (1) resetting parameters that only changed a small amount during fine-tuning, (2) resolving sign conflicts, and (3) merging only the parameters that are in alignment with the final agreed-upon sign. We find that TIES-Merging outperforms several existing methods in diverse settings covering a range of modalities, domains, number of tasks, model sizes, architectures, and fine-tuning settings. We further analyze the impact of different types of interference on model parameters, highlight the importance of resolving sign interference. Our code is available at https://github.com/prateeky2806/ties-merging
Evaluating the Factual Consistency of Large Language Models Through Summarization
Nov 15, 2022



While large language models (LLMs) have proven to be effective on a large variety of tasks, they are also known to hallucinate information. To measure whether an LLM prefers factually consistent continuations of its input, we propose a new benchmark called FIB(Factual Inconsistency Benchmark) that focuses on the task of summarization. Specifically, our benchmark involves comparing the scores an LLM assigns to a factually consistent versus a factually inconsistent summary for an input news article. For factually consistent summaries, we use human-written reference summaries that we manually verify as factually consistent. To generate summaries that are factually inconsistent, we generate summaries from a suite of summarization models that we have manually annotated as factually inconsistent. A model's factual consistency is then measured according to its accuracy, i.e.\ the proportion of documents where it assigns a higher score to the factually consistent summary. To validate the usefulness of FIB, we evaluate 23 large language models ranging from 1B to 176B parameters from six different model families including BLOOM and OPT. We find that existing LLMs generally assign a higher score to factually consistent summaries than to factually inconsistent summaries. However, if the factually inconsistent summaries occur verbatim in the document, then LLMs assign a higher score to these factually inconsistent summaries than factually consistent summaries. We validate design choices in our benchmark including the scoring method and source of distractor summaries. Our code and benchmark data can be found at https://github.com/r-three/fib.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning
May 11, 2022
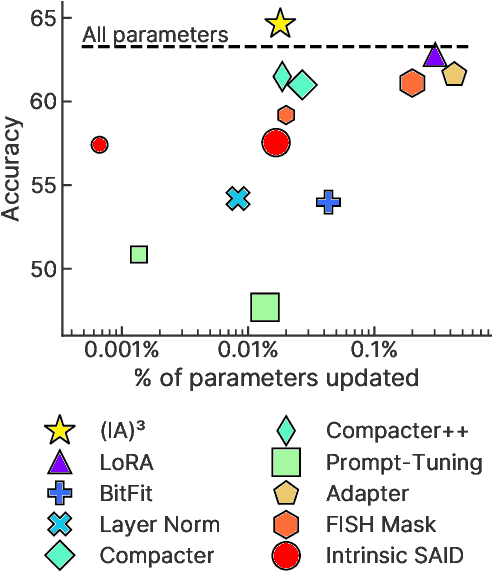
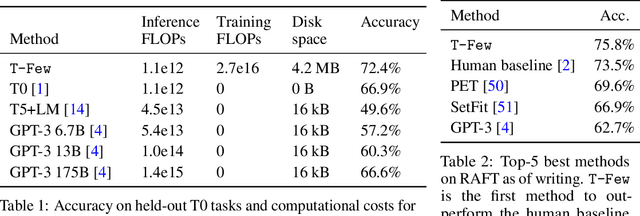
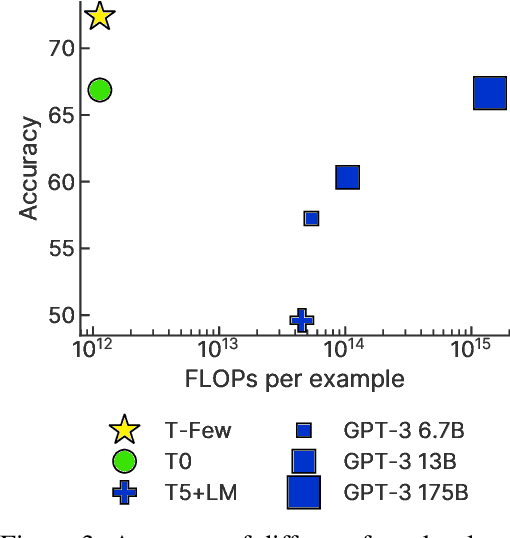
Few-shot in-context learning (ICL) enables pre-trained language models to perform a previously-unseen task without any gradient-based training by feeding a small number of training examples as part of the input. ICL incurs substantial computational, memory, and storage costs because it involves processing all of the training examples every time a prediction is made. Parameter-efficient fine-tuning (e.g. adapter modules, prompt tuning, sparse update methods, etc.) offers an alternative paradigm where a small set of parameters are trained to enable a model to perform the new task. In this paper, we rigorously compare few-shot ICL and parameter-efficient fine-tuning and demonstrate that the latter offers better accuracy as well as dramatically lower computational costs. Along the way, we introduce a new parameter-efficient fine-tuning method called (IA)$^3$ that scales activations by learned vectors, attaining stronger performance while only introducing a relatively tiny amount of new parameters. We also propose a simple recipe based on the T0 model called T-Few that can be applied to new tasks without task-specific tuning or modifications. We validate the effectiveness of T-Few on completely unseen tasks by applying it to the RAFT benchmark, attaining super-human performance for the first time and outperforming the state-of-the-art by 6% absolute. All of the code used in our experiments is publicly available.
Prosody-Aware Neural Machine Translation for Dubbing
Dec 16, 2021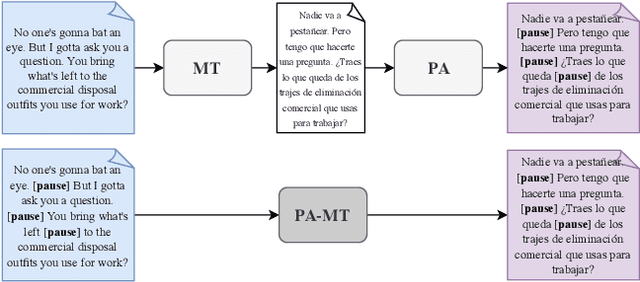
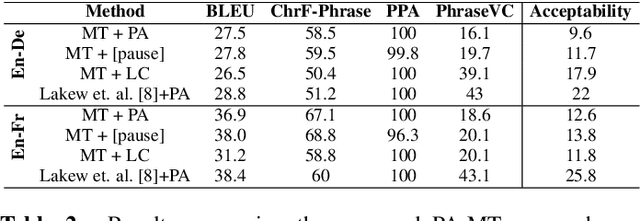
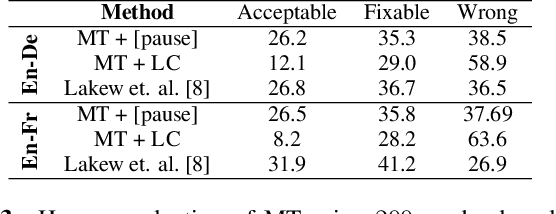

We introduce the task of prosody-aware machine translation which aims at generating translations suitable for dubbing. Dubbing of a spoken sentence requires transferring the content as well as the prosodic structure of the source into the target language to preserve timing information. Practically, this implies correctly projecting pauses from the source to the target and ensuring that target speech segments have roughly the same duration of the corresponding source segments. In this work, we propose an implicit and explicit modeling approaches to integrate prosody information into neural machine translation. Experiments on English-German/French with automatic metrics show that the simplest of the considered approaches works best. Results are confirmed by human evaluations of translations and dubbed videos.
An Empirical Survey of Data Augmentation for Limited Data Learning in NLP
Jun 14, 2021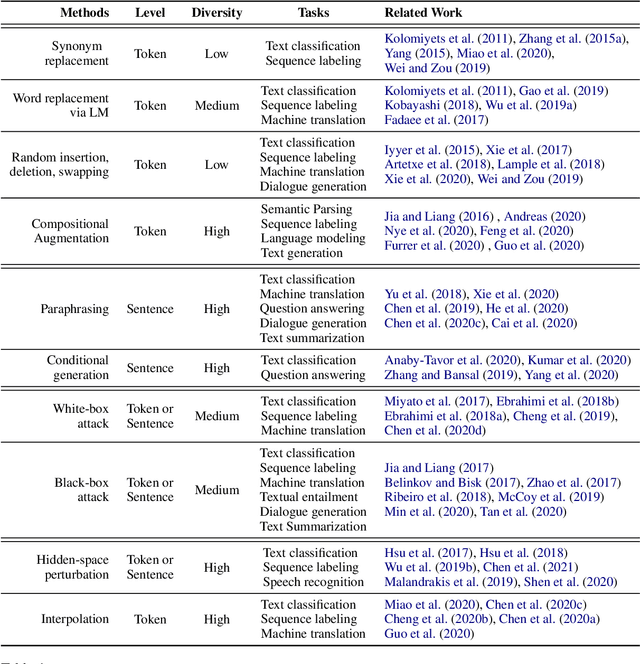
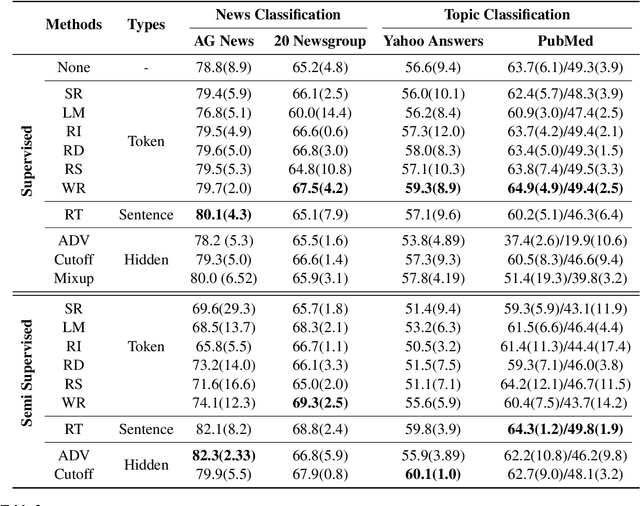
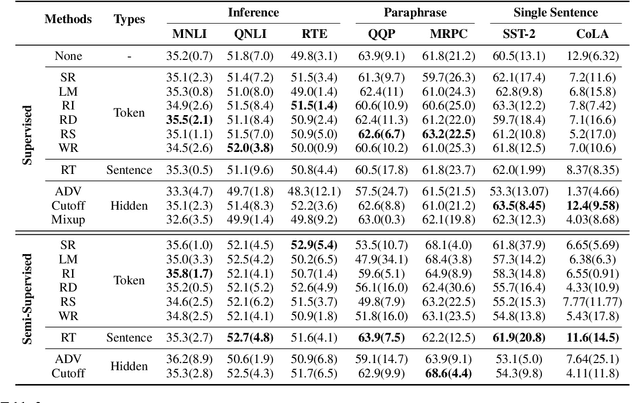
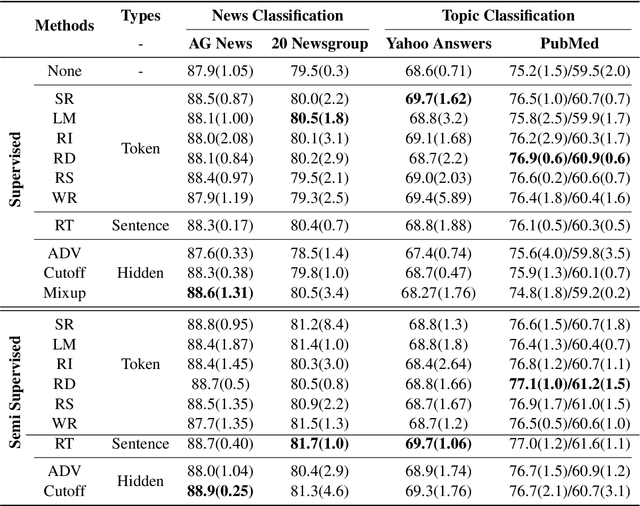
NLP has achieved great progress in the past decade through the use of neural models and large labeled datasets. The dependence on abundant data prevents NLP models from being applied to low-resource settings or novel tasks where significant time, money, or expertise is required to label massive amounts of textual data. Recently, data augmentation methods have been explored as a means of improving data efficiency in NLP. To date, there has been no systematic empirical overview of data augmentation for NLP in the limited labeled data setting, making it difficult to understand which methods work in which settings. In this paper, we provide an empirical survey of recent progress on data augmentation for NLP in the limited labeled data setting, summarizing the landscape of methods (including token-level augmentations, sentence-level augmentations, adversarial augmentations, and hidden-space augmentations) and carrying out experiments on 11 datasets covering topics/news classification, inference tasks, paraphrasing tasks, and single-sentence tasks. Based on the results, we draw several conclusions to help practitioners choose appropriate augmentations in different settings and discuss the current challenges and future directions for limited data learning in NLP.
Improving and Simplifying Pattern Exploiting Training
Mar 22, 2021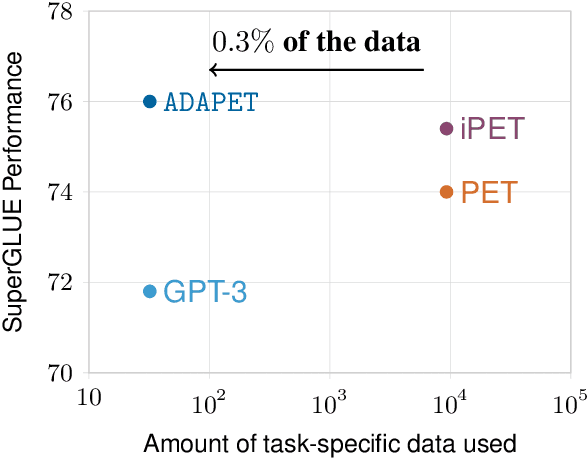

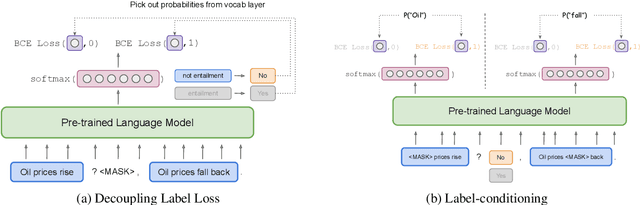

Recently, pre-trained language models (LMs) have achieved strong performance when fine-tuned on difficult benchmarks like SuperGLUE. However, performance can suffer when there are very few labeled examples available for fine-tuning. Pattern Exploiting Training (PET) is a recent approach that leverages patterns for few-shot learning. However, PET uses task-specific unlabeled data. In this paper, we focus on few shot learning without any unlabeled data and introduce ADAPET, which modifies PET's objective to provide denser supervision during fine-tuning. As a result, ADAPET outperforms PET on SuperGLUE without any task-specific unlabeled data. Our code can be found at https://github.com/rrmenon10/ADAPET.