 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgestring2string: A Modern Python Library for String-to-String Algorithms
Apr 27, 2023



We introduce string2string, an open-source library that offers a comprehensive suite of efficient algorithms for a broad range of string-to-string problems. It includes traditional algorithmic solutions as well as recent advanced neural approaches to tackle various problems in string alignment, distance measurement, lexical and semantic search, and similarity analysis -- along with several helpful visualization tools and metrics to facilitate the interpretation and analysis of these methods. Notable algorithms featured in the library include the Smith-Waterman algorithm for pairwise local alignment, the Hirschberg algorithm for global alignment, the Wagner-Fisher algorithm for edit distance, BARTScore and BERTScore for similarity analysis, the Knuth-Morris-Pratt algorithm for lexical search, and Faiss for semantic search. Besides, it wraps existing efficient and widely-used implementations of certain frameworks and metrics, such as sacreBLEU and ROUGE, whenever it is appropriate and suitable. Overall, the library aims to provide extensive coverage and increased flexibility in comparison to existing libraries for strings. It can be used for many downstream applications, tasks, and problems in natural-language processing, bioinformatics, and computational social sciences. It is implemented in Python, easily installable via pip, and accessible through a simple API. Source code, documentation, and tutorials are all available on our GitHub page: https://github.com/stanfordnlp/string2string.
The Harvard USPTO Patent Dataset: A Large-Scale, Well-Structured, and Multi-Purpose Corpus of Patent Applications
Jul 08, 2022


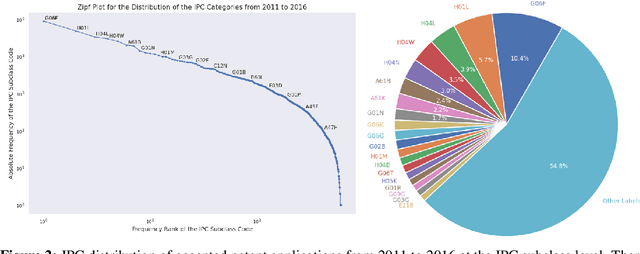
Innovation is a major driver of economic and social development, and information about many kinds of innovation is embedded in semi-structured data from patents and patent applications. Although the impact and novelty of innovations expressed in patent data are difficult to measure through traditional means, ML offers a promising set of techniques for evaluating novelty, summarizing contributions, and embedding semantics. In this paper, we introduce the Harvard USPTO Patent Dataset (HUPD), a large-scale, well-structured, and multi-purpose corpus of English-language patent applications filed to the United States Patent and Trademark Office (USPTO) between 2004 and 2018. With more than 4.5 million patent documents, HUPD is two to three times larger than comparable corpora. Unlike previously proposed patent datasets in NLP, HUPD contains the inventor-submitted versions of patent applications--not the final versions of granted patents--thereby allowing us to study patentability at the time of filing using NLP methods for the first time. It is also novel in its inclusion of rich structured metadata alongside the text of patent filings: By providing each application's metadata along with all of its text fields, the dataset enables researchers to perform new sets of NLP tasks that leverage variation in structured covariates. As a case study on the types of research HUPD makes possible, we introduce a new task to the NLP community--namely, binary classification of patent decisions. We additionally show the structured metadata provided in the dataset enables us to conduct explicit studies of concept shifts for this task. Finally, we demonstrate how HUPD can be used for three additional tasks: multi-class classification of patent subject areas, language modeling, and summarization.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Memory-Augmented Recurrent Neural Networks Can Learn Generalized Dyck Languages
Nov 08, 2019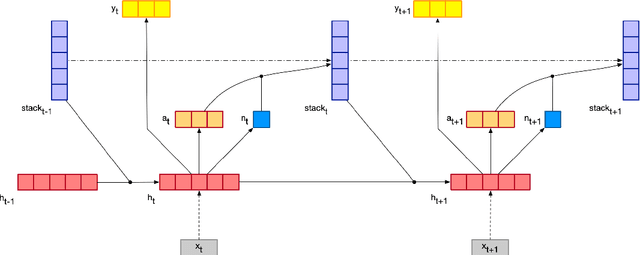
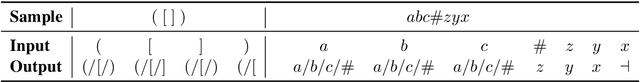
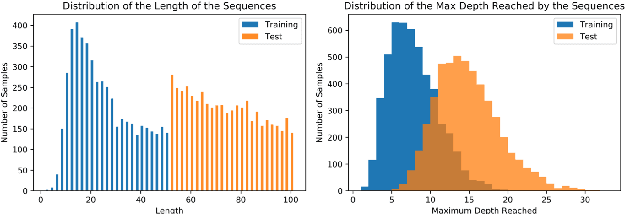
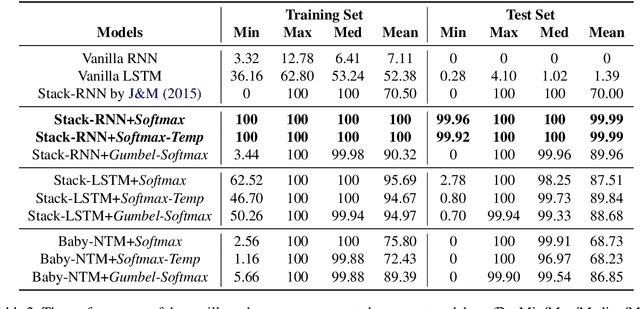
We introduce three memory-augmented Recurrent Neural Networks (MARNNs) and explore their capabilities on a series of simple language modeling tasks whose solutions require stack-based mechanisms. We provide the first demonstration of neural networks recognizing the generalized Dyck languages, which express the core of what it means to be a language with hierarchical structure. Our memory-augmented architectures are easy to train in an end-to-end fashion and can learn the Dyck languages over as many as six parenthesis-pairs, in addition to two deterministic palindrome languages and the string-reversal transduction task, by emulating pushdown automata. Our experiments highlight the increased modeling capacity of memory-augmented models over simple RNNs, while inflecting our understanding of the limitations of these models.
On Adversarial Removal of Hypothesis-only Bias in Natural Language Inference
Jul 09, 2019
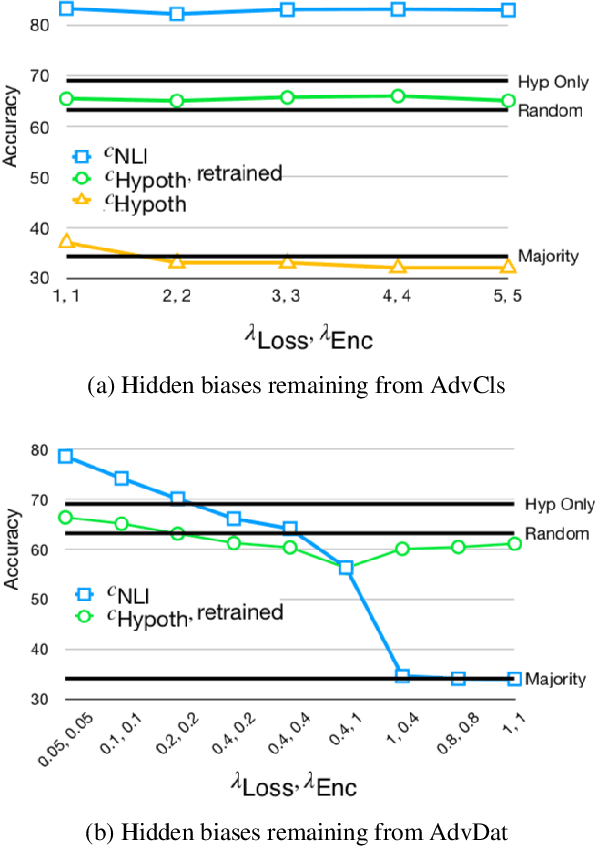
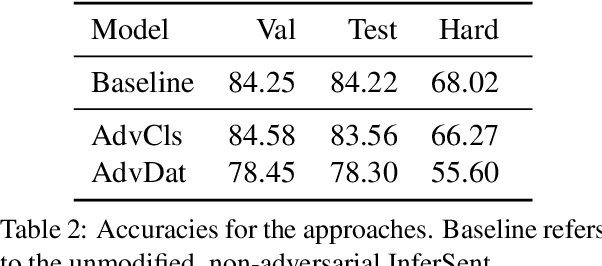
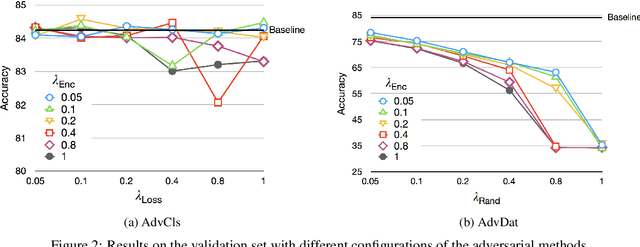
Popular Natural Language Inference (NLI) datasets have been shown to be tainted by hypothesis-only biases. Adversarial learning may help models ignore sensitive biases and spurious correlations in data. We evaluate whether adversarial learning can be used in NLI to encourage models to learn representations free of hypothesis-only biases. Our analyses indicate that the representations learned via adversarial learning may be less biased, with only small drops in NLI accuracy.
Don't Take the Premise for Granted: Mitigating Artifacts in Natural Language Inference
Jul 09, 2019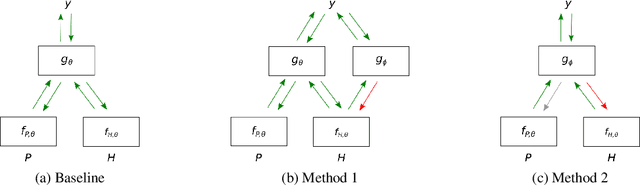

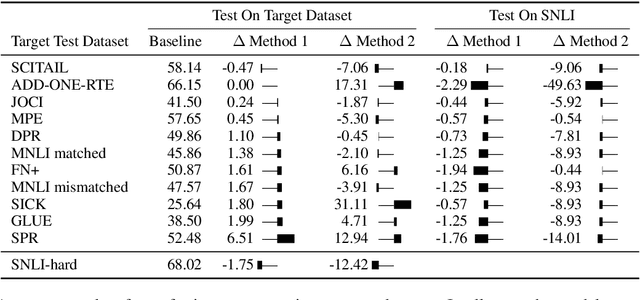
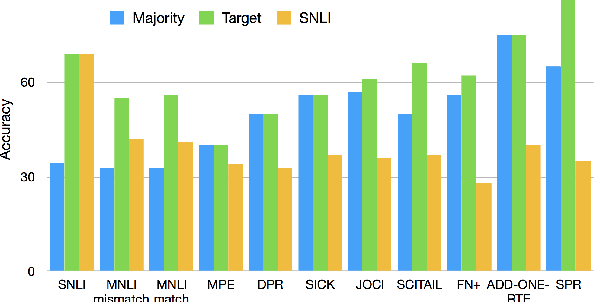
Natural Language Inference (NLI) datasets often contain hypothesis-only biases---artifacts that allow models to achieve non-trivial performance without learning whether a premise entails a hypothesis. We propose two probabilistic methods to build models that are more robust to such biases and better transfer across datasets. In contrast to standard approaches to NLI, our methods predict the probability of a premise given a hypothesis and NLI label, discouraging models from ignoring the premise. We evaluate our methods on synthetic and existing NLI datasets by training on datasets containing biases and testing on datasets containing no (or different) hypothesis-only biases. Our results indicate that these methods can make NLI models more robust to dataset-specific artifacts, transferring better than a baseline architecture in 9 out of 12 NLI datasets. Additionally, we provide an extensive analysis of the interplay of our methods with known biases in NLI datasets, as well as the effects of encouraging models to ignore biases and fine-tuning on target datasets.
LSTM Networks Can Perform Dynamic Counting
Jun 09, 2019
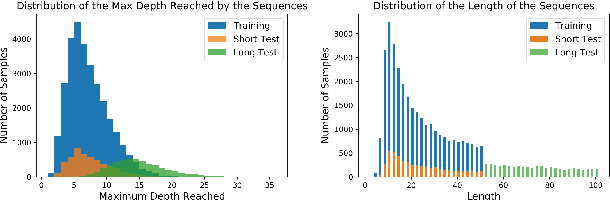

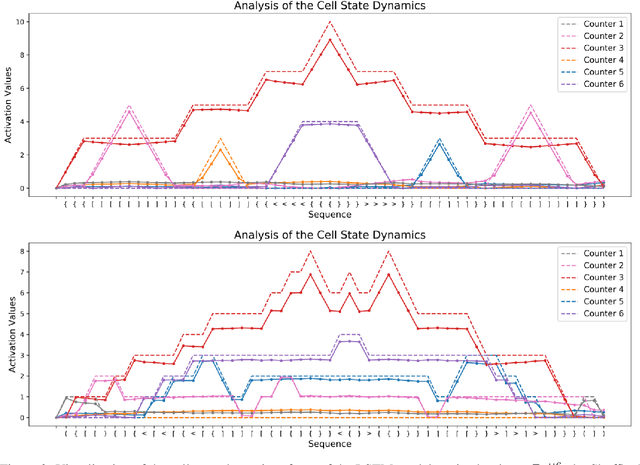
In this paper, we systematically assess the ability of standard recurrent networks to perform dynamic counting and to encode hierarchical representations. All the neural models in our experiments are designed to be small-sized networks both to prevent them from memorizing the training sets and to visualize and interpret their behaviour at test time. Our results demonstrate that the Long Short-Term Memory (LSTM) networks can learn to recognize the well-balanced parenthesis language (Dyck-$1$) and the shuffles of multiple Dyck-$1$ languages, each defined over different parenthesis-pairs, by emulating simple real-time $k$-counter machines. To the best of our knowledge, this work is the first study to introduce the shuffle languages to analyze the computational power of neural networks. We also show that a single-layer LSTM with only one hidden unit is practically sufficient for recognizing the Dyck-$1$ language. However, none of our recurrent networks was able to yield a good performance on the Dyck-$2$ language learning task, which requires a model to have a stack-like mechanism for recognition.
On Evaluating the Generalization of LSTM Models in Formal Languages
Nov 02, 2018
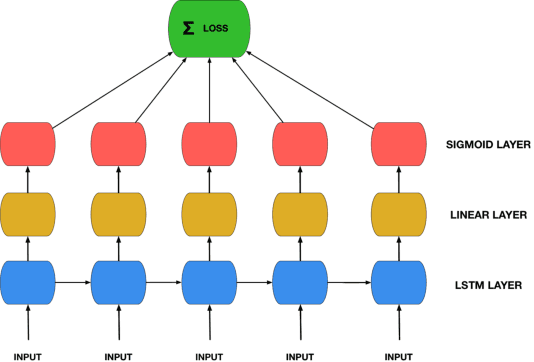

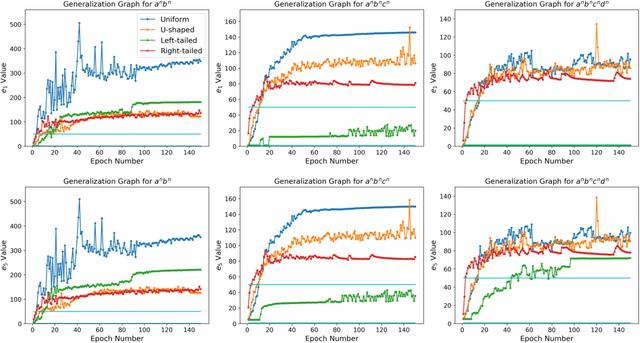
Recurrent Neural Networks (RNNs) are theoretically Turing-complete and established themselves as a dominant model for language processing. Yet, there still remains an uncertainty regarding their language learning capabilities. In this paper, we empirically evaluate the inductive learning capabilities of Long Short-Term Memory networks, a popular extension of simple RNNs, to learn simple formal languages, in particular $a^nb^n$, $a^nb^nc^n$, and $a^nb^nc^nd^n$. We investigate the influence of various aspects of learning, such as training data regimes and model capacity, on the generalization to unobserved samples. We find striking differences in model performances under different training settings and highlight the need for careful analysis and assessment when making claims about the learning capabilities of neural network models.
Learning Neural Templates for Text Generation
Sep 13, 2018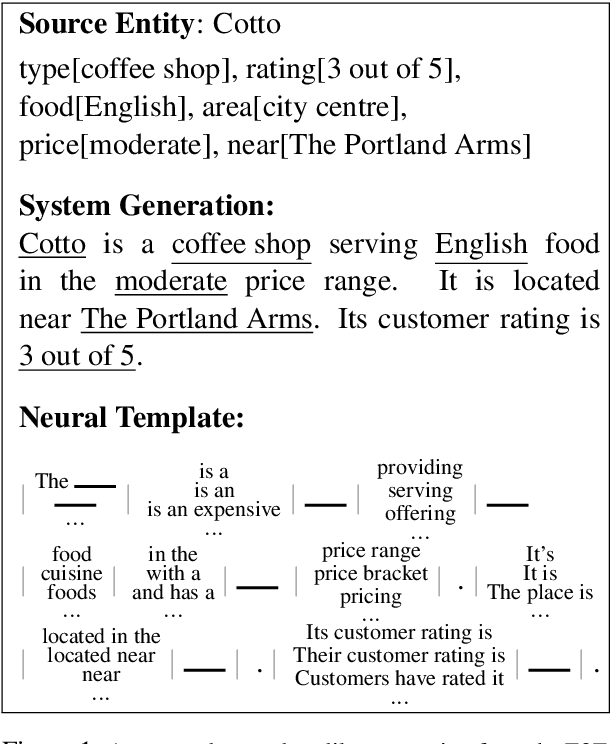
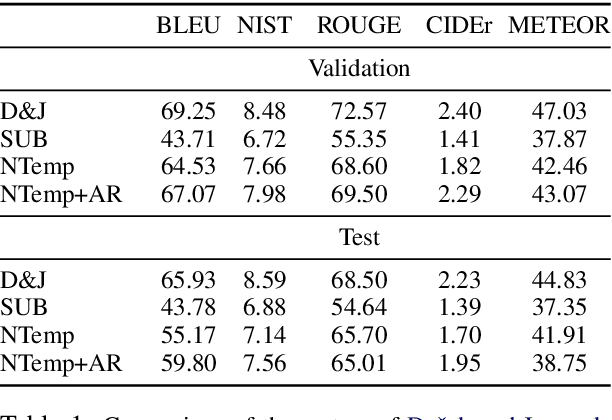
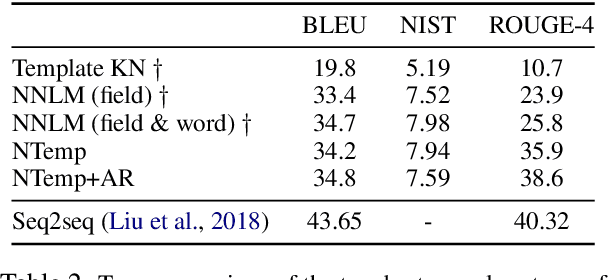
While neural, encoder-decoder models have had significant empirical success in text generation, there remain several unaddressed problems with this style of generation. Encoder-decoder models are largely (a) uninterpretable, and (b) difficult to control in terms of their phrasing or content. This work proposes a neural generation system using a hidden semi-markov model (HSMM) decoder, which learns latent, discrete templates jointly with learning to generate. We show that this model learns useful templates, and that these templates make generation both more interpretable and controllable. Furthermore, we show that this approach scales to real data sets and achieves strong performance nearing that of encoder-decoder text generation models.
Adapting Sequence Models for Sentence Correction
Jul 27, 2017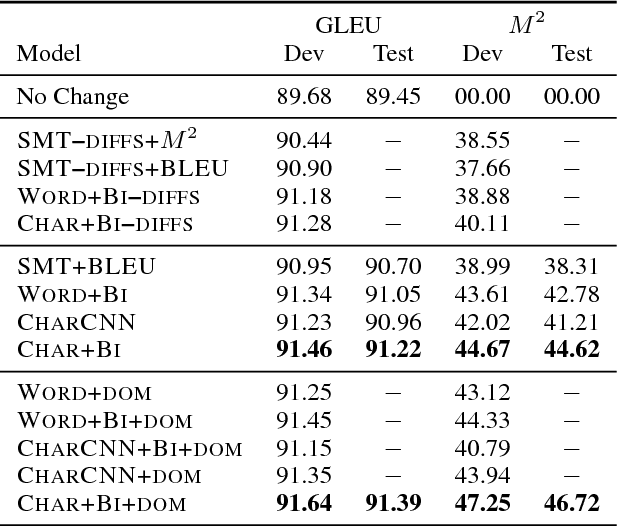
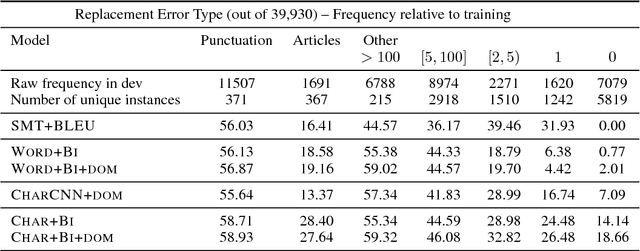
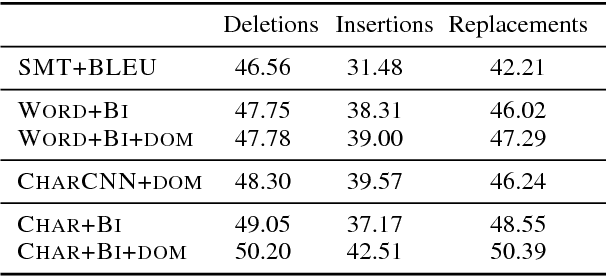
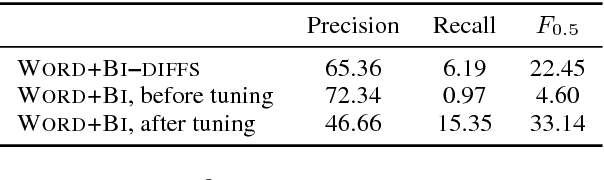
In a controlled experiment of sequence-to-sequence approaches for the task of sentence correction, we find that character-based models are generally more effective than word-based models and models that encode subword information via convolutions, and that modeling the output data as a series of diffs improves effectiveness over standard approaches. Our strongest sequence-to-sequence model improves over our strongest phrase-based statistical machine translation model, with access to the same data, by 6 M2 (0.5 GLEU) points. Additionally, in the data environment of the standard CoNLL-2014 setup, we demonstrate that modeling (and tuning against) diffs yields similar or better M2 scores with simpler models and/or significantly less data than previous sequence-to-sequence approaches.