 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeurocache: Efficient Vector Retrieval for Long-range Language Modeling
Jul 02, 2024This paper introduces Neurocache, an approach to extend the effective context size of large language models (LLMs) using an external vector cache to store its past states. Like recent vector retrieval approaches, Neurocache uses an efficient k-nearest-neighbor (kNN) algorithm to retrieve relevant past states and incorporate them into the attention process. Neurocache improves upon previous methods by (1) storing compressed states, which reduces cache size; (2) performing a single retrieval operation per token which increases inference speed; and (3) extending the retrieval window to neighboring states, which improves both language modeling and downstream task accuracy. Our experiments show the effectiveness of Neurocache both for models trained from scratch and for pre-trained models such as Llama2-7B and Mistral-7B when enhanced with the cache mechanism. We also compare Neurocache with text retrieval methods and show improvements in single-document question-answering and few-shot learning tasks. We made the source code available under: https://github.com/alisafaya/neurocache
HuBERT-TR: Reviving Turkish Automatic Speech Recognition with Self-supervised Speech Representation Learning
Oct 13, 2022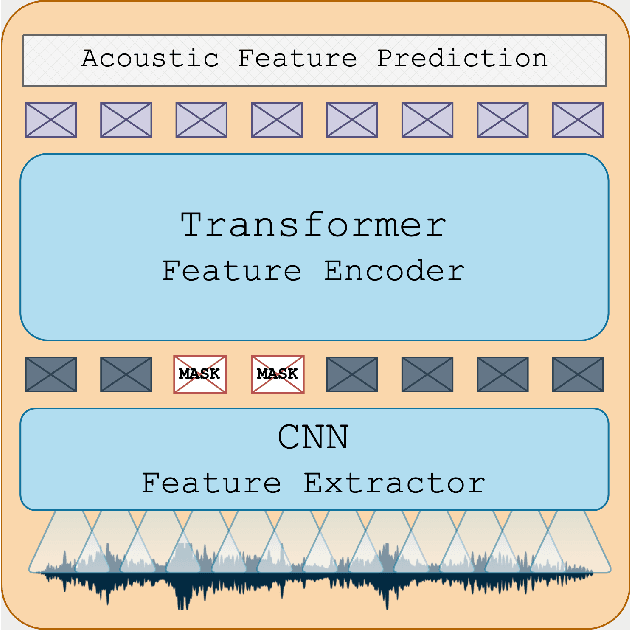
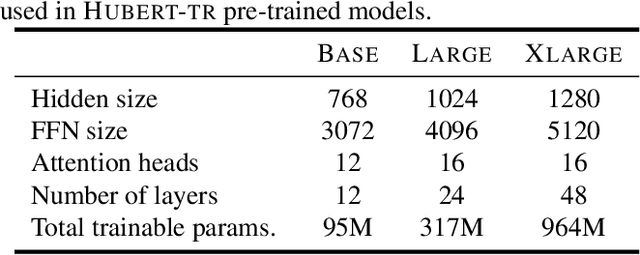
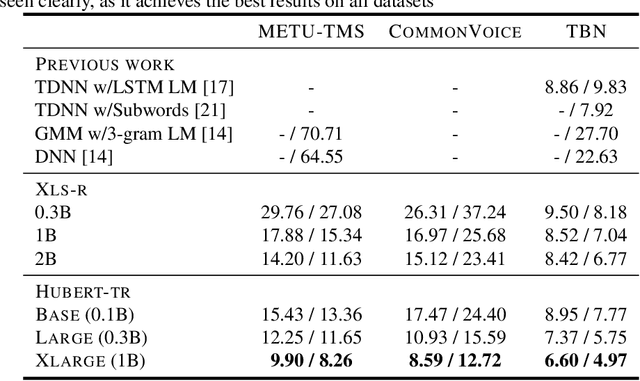
While the Turkish language is listed among low-resource languages, literature on Turkish automatic speech recognition (ASR) is relatively old. In this paper, we present HuBERT-TR, a speech representation model for Turkish based on HuBERT. HuBERT-TR achieves state-of-the-art results on several Turkish ASR datasets. We investigate pre-training HuBERT for Turkish with large-scale data curated from online resources. We pre-train HuBERT-TR using over 6,500 hours of speech data curated from YouTube that includes extensive variability in terms of quality and genre. We show that pre-trained models within a multi-lingual setup are inferior to language-specific models, where our Turkish model HuBERT-TR base performs better than its x10 times larger multi-lingual counterpart XLS-R-1B. Moreover, we study the effect of scaling on ASR performance by scaling our models up to 1B parameters. Our best model yields a state-of-the-art word error rate of 4.97% on the Turkish Broadcast News dataset. Models are available at huggingface.co/asafaya .
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Event Coreference Resolution for Contentious Politics Events
Mar 18, 2022
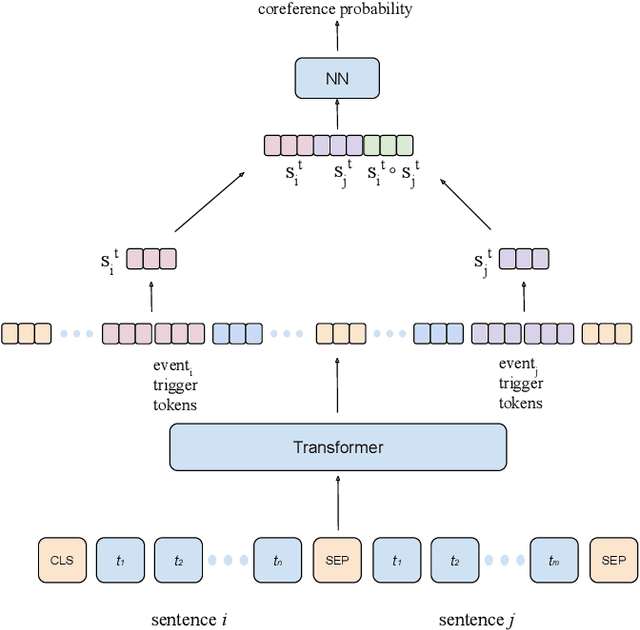
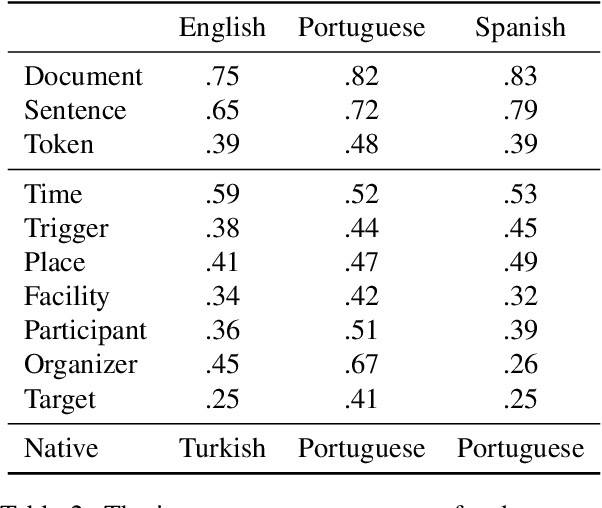
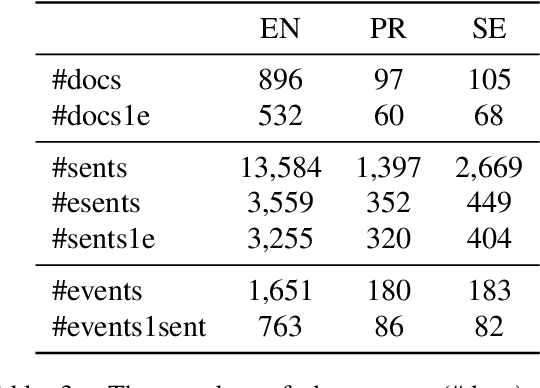
We propose a dataset for event coreference resolution, which is based on random samples drawn from multiple sources, languages, and countries. Early scholarship on event information collection has not quantified the contribution of event coreference resolution. We prepared and analyzed a representative multilingual corpus and measured the performance and contribution of the state-of-the-art event coreference resolution approaches. We found that almost half of the event mentions in documents co-occur with other event mentions and this makes it inevitable to obtain erroneous or partial event information. We showed that event coreference resolution could help improving this situation. Our contribution sheds light on a challenge that has been overlooked or hard to study to date. Future event information collection studies can be designed based on the results we present in this report. The repository for this study is on https://github.com/emerging-welfare/ECR4-Contentious-Politics.
Mukayese: Turkish NLP Strikes Back
Mar 16, 2022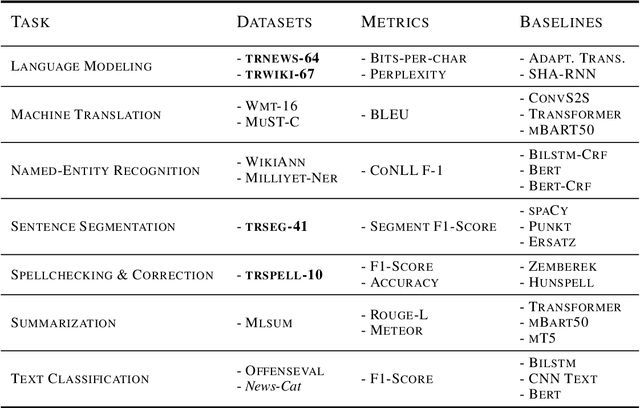
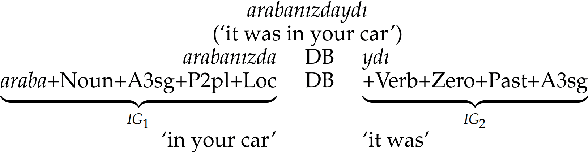
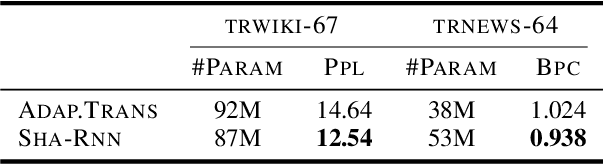
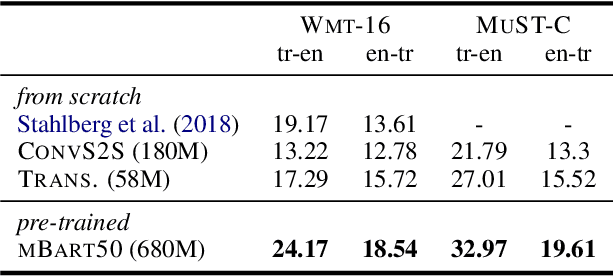
Having sufficient resources for language X lifts it from the under-resourced languages class, but not necessarily from the under-researched class. In this paper, we address the problem of the absence of organized benchmarks in the Turkish language. We demonstrate that languages such as Turkish are left behind the state-of-the-art in NLP applications. As a solution, we present Mukayese, a set of NLP benchmarks for the Turkish language that contains several NLP tasks. We work on one or more datasets for each benchmark and present two or more baselines. Moreover, we present four new benchmarking datasets in Turkish for language modeling, sentence segmentation, and spell checking. All datasets and baselines are available under: https://github.com/alisafaya/mukayese
COVCOR20 at WNUT-2020 Task 2: An Attempt to Combine Deep Learning and Expert rules
Sep 07, 2020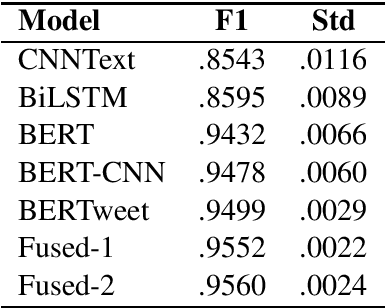
In the scope of WNUT-2020 Task 2, we developed various text classification systems, using deep learning models and one using linguistically informed rules. While both of the deep learning systems outperformed the system using the linguistically informed rules, we found that through the integration of (the output of) the three systems a better performance could be achieved than the standalone performance of each approach in a cross-validation setting. However, on the test data the performance of the integration was slightly lower than our best performing deep learning model. These results hardly indicate any progress in line of integrating machine learning and expert rules driven systems. We expect that the release of the annotation manuals and gold labels of the test data after this workshop will shed light on these perplexing results.
KUISAIL at SemEval-2020 Task 12: BERT-CNN for Offensive Speech Identification in Social Media
Jul 26, 2020
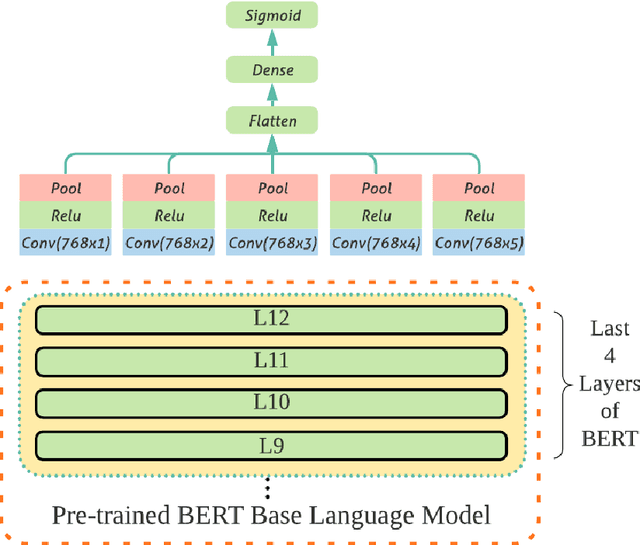
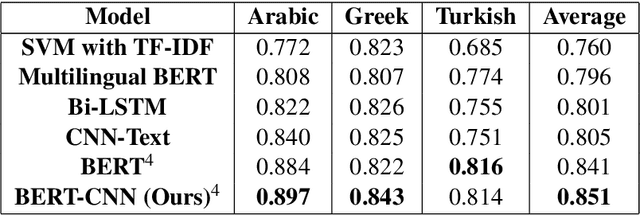
In this paper, we describe our approach to utilize pre-trained BERT models with Convolutional Neural Networks for sub-task A of the Multilingual Offensive Language Identification shared task (OffensEval 2020), which is a part of the SemEval 2020. We show that combining CNN with BERT is better than using BERT on its own, and we emphasize the importance of utilizing pre-trained language models for downstream tasks. Our system, ranked 4th with macro averaged F1-Score of 0.897 in Arabic, 4th with score of 0.843 in Greek, and 3rd with score of 0.814 in Turkish. Additionally, we present ArabicBERT, a set of pre-trained transformer language models for Arabic that we share with the community.
Automated Extraction of Socio-political Events from News (AESPEN): Workshop and Shared Task Report
May 12, 2020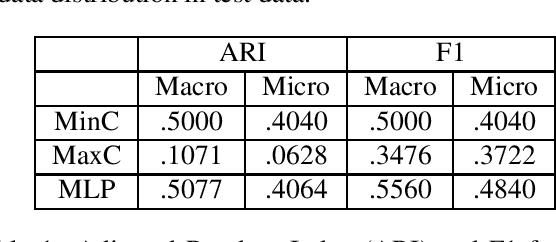
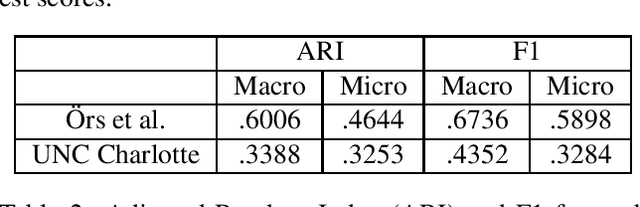
We describe our effort on automated extraction of socio-political events from news in the scope of a workshop and a shared task we organized at Language Resources and Evaluation Conference (LREC 2020). We believe the event extraction studies in computational linguistics and social and political sciences should further support each other in order to enable large scale socio-political event information collection across sources, countries, and languages. The event consists of regular research papers and a shared task, which is about event sentence coreference identification (ESCI), tracks. All submissions were reviewed by five members of the program committee. The workshop attracted research papers related to evaluation of machine learning methodologies, language resources, material conflict forecasting, and a shared task participation report in the scope of socio-political event information collection. It has shown us the volume and variety of both the data sources and event information collection approaches related to socio-political events and the need to fill the gap between automated text processing techniques and requirements of social and political sciences.