 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
Many-Shot In-Context Learning
Apr 17, 2024



Large language models (LLMs) excel at few-shot in-context learning (ICL) -- learning from a few examples provided in context at inference, without any weight updates. Newly expanded context windows allow us to investigate ICL with hundreds or thousands of examples -- the many-shot regime. Going from few-shot to many-shot, we observe significant performance gains across a wide variety of generative and discriminative tasks. While promising, many-shot ICL can be bottlenecked by the available amount of human-generated examples. To mitigate this limitation, we explore two new settings: Reinforced and Unsupervised ICL. Reinforced ICL uses model-generated chain-of-thought rationales in place of human examples. Unsupervised ICL removes rationales from the prompt altogether, and prompts the model only with domain-specific questions. We find that both Reinforced and Unsupervised ICL can be quite effective in the many-shot regime, particularly on complex reasoning tasks. Finally, we demonstrate that, unlike few-shot learning, many-shot learning is effective at overriding pretraining biases and can learn high-dimensional functions with numerical inputs. Our analysis also reveals the limitations of next-token prediction loss as an indicator of downstream ICL performance.
PaLM 2 Technical Report
May 17, 2023



We introduce PaLM 2, a new state-of-the-art language model that has better multilingual and reasoning capabilities and is more compute-efficient than its predecessor PaLM. PaLM 2 is a Transformer-based model trained using a mixture of objectives. Through extensive evaluations on English and multilingual language, and reasoning tasks, we demonstrate that PaLM 2 has significantly improved quality on downstream tasks across different model sizes, while simultaneously exhibiting faster and more efficient inference compared to PaLM. This improved efficiency enables broader deployment while also allowing the model to respond faster, for a more natural pace of interaction. PaLM 2 demonstrates robust reasoning capabilities exemplified by large improvements over PaLM on BIG-Bench and other reasoning tasks. PaLM 2 exhibits stable performance on a suite of responsible AI evaluations, and enables inference-time control over toxicity without additional overhead or impact on other capabilities. Overall, PaLM 2 achieves state-of-the-art performance across a diverse set of tasks and capabilities. When discussing the PaLM 2 family, it is important to distinguish between pre-trained models (of various sizes), fine-tuned variants of these models, and the user-facing products that use these models. In particular, user-facing products typically include additional pre- and post-processing steps. Additionally, the underlying models may evolve over time. Therefore, one should not expect the performance of user-facing products to exactly match the results reported in this report.
Language Models Trained on Media Diets Can Predict Public Opinion
Mar 28, 2023



Public opinion reflects and shapes societal behavior, but the traditional survey-based tools to measure it are limited. We introduce a novel approach to probe media diet models -- language models adapted to online news, TV broadcast, or radio show content -- that can emulate the opinions of subpopulations that have consumed a set of media. To validate this method, we use as ground truth the opinions expressed in U.S. nationally representative surveys on COVID-19 and consumer confidence. Our studies indicate that this approach is (1) predictive of human judgements found in survey response distributions and robust to phrasing and channels of media exposure, (2) more accurate at modeling people who follow media more closely, and (3) aligned with literature on which types of opinions are affected by media consumption. Probing language models provides a powerful new method for investigating media effects, has practical applications in supplementing polls and forecasting public opinion, and suggests a need for further study of the surprising fidelity with which neural language models can predict human responses.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Evolving Evocative 2D Views of Generated 3D Objects
Nov 08, 2021
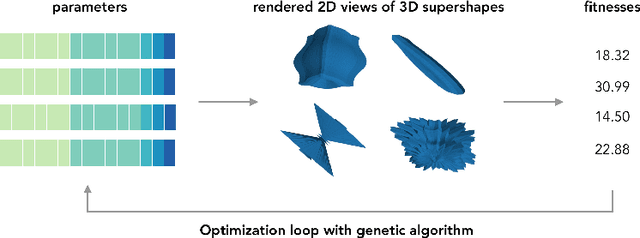


We present a method for jointly generating 3D models of objects and 2D renders at different viewing angles, with the process guided by ImageNet and CLIP -based models. Our results indicate that it can generate anamorphic objects, with renders that both evoke the target caption and look visually appealing.
Are Visual Explanations Useful? A Case Study in Model-in-the-Loop Prediction
Jul 23, 2020
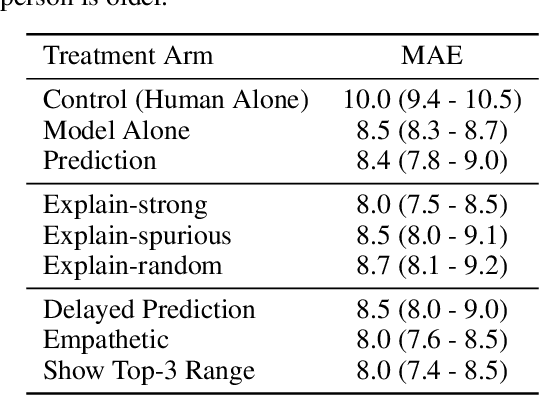

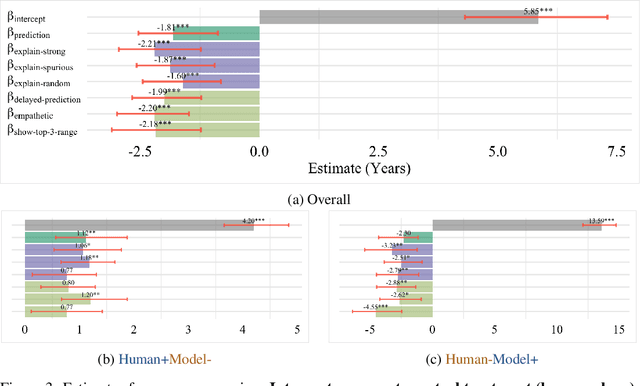
We present a randomized controlled trial for a model-in-the-loop regression task, with the goal of measuring the extent to which (1) good explanations of model predictions increase human accuracy, and (2) faulty explanations decrease human trust in the model. We study explanations based on visual saliency in an image-based age prediction task for which humans and learned models are individually capable but not highly proficient and frequently disagree. Our experimental design separates model quality from explanation quality, and makes it possible to compare treatments involving a variety of explanations of varying levels of quality. We find that presenting model predictions improves human accuracy. However, visual explanations of various kinds fail to significantly alter human accuracy or trust in the model - regardless of whether explanations characterize an accurate model, an inaccurate one, or are generated randomly and independently of the input image. These findings suggest the need for greater evaluation of explanations in downstream decision making tasks, better design-based tools for presenting explanations to users, and better approaches for generating explanations.
Games for Fairness and Interpretability
Apr 20, 2020
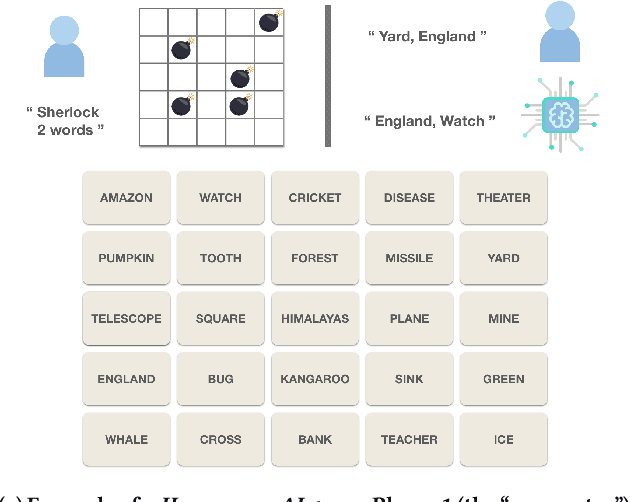
As Machine Learning (ML) systems becomes more ubiquitous, ensuring the fair and equitable application of their underlying algorithms is of paramount importance. We argue that one way to achieve this is to proactively cultivate public pressure for ML developers to design and develop fairer algorithms -- and that one way to cultivate public pressure while simultaneously serving the interests and objectives of algorithm developers is through gameplay. We propose a new class of games -- ``games for fairness and interpretability'' -- as one example of an incentive-aligned approach for producing fairer and more equitable algorithms. Games for fairness and interpretability are carefully-designed games with mass appeal. They are inherently engaging, provide insights into how machine learning models work, and ultimately produce data that helps researchers and developers improve their algorithms. We highlight several possible examples of games, their implications for fairness and interpretability, how their proliferation could creative positive public pressure by narrowing the gap between algorithm developers and the general public, and why the machine learning community could benefit from them.
Learning Personas from Dialogue with Attentive Memory Networks
Oct 19, 2018

The ability to infer persona from dialogue can have applications in areas ranging from computational narrative analysis to personalized dialogue generation. We introduce neural models to learn persona embeddings in a supervised character trope classification task. The models encode dialogue snippets from IMDB into representations that can capture the various categories of film characters. The best-performing models use a multi-level attention mechanism over a set of utterances. We also utilize prior knowledge in the form of textual descriptions of the different tropes. We apply the learned embeddings to find similar characters across different movies, and cluster movies according to the distribution of the embeddings. The use of short conversational text as input, and the ability to learn from prior knowledge using memory, suggests these methods could be applied to other domains.
Unsupervised Neural Multi-document Abstractive Summarization
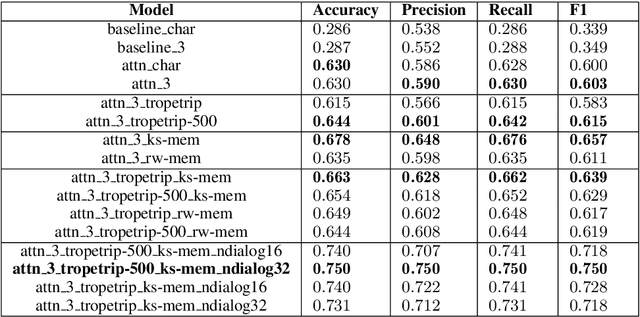
Oct 12, 2018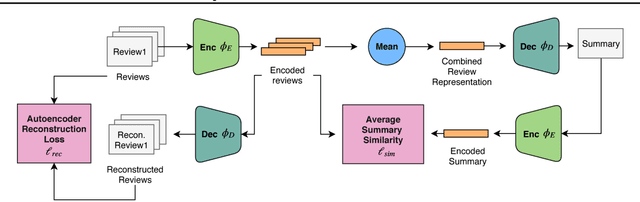
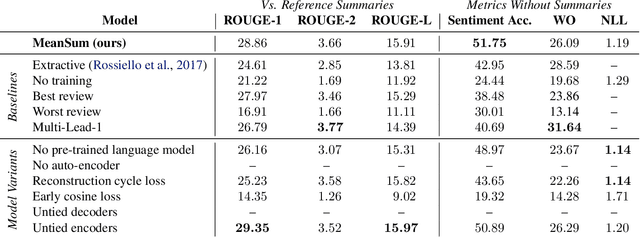

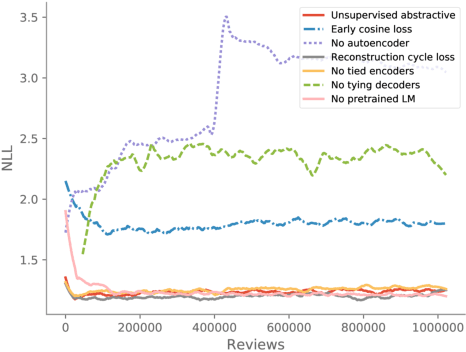
Abstractive summarization has been studied using neural sequence transduction methods with datasets of large, paired document-summary examples. However, such datasets are rare and the models trained from them do not generalize to other domains. Recently, some progress has been made in learning sequence-to-sequence mappings with only unpaired examples. In our work, we consider the setting where there are only documents and no summaries provided and propose an end-to-end, neural model architecture to perform unsupervised abstractive summarization. Our proposed model consists of an auto-encoder trained so that the mean of the representations of the input documents decodes to a reasonable summary. We consider variants of the proposed architecture and perform an ablation study to show the importance of specific components. We apply our model to the summarization of business and product reviews and show that the generated summaries are fluent, show relevancy in terms of word-overlap, representative of the average sentiment of the input documents, and are highly abstractive compared to baselines.