 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Effective Representations for Retrieval Using Self-Distillation with Adaptive Relevance Margins
Jul 31, 2024



Representation-based retrieval models, so-called biencoders, estimate the relevance of a document to a query by calculating the similarity of their respective embeddings. Current state-of-the-art biencoders are trained using an expensive training regime involving knowledge distillation from a teacher model and batch-sampling. Instead of relying on a teacher model, we contribute a novel parameter-free loss function for self-supervision that exploits the pre-trained language modeling capabilities of the encoder model as a training signal, eliminating the need for batch sampling by performing implicit hard negative mining. We investigate the capabilities of our proposed approach through extensive ablation studies, demonstrating that self-distillation can match the effectiveness of teacher distillation using only 13.5% of the data, while offering a speedup in training time between 3x and 15x compared to parametrized losses. Code and data is made openly available.
Evaluating Generative Ad Hoc Information Retrieval
Nov 08, 2023



Recent advances in large language models have enabled the development of viable generative information retrieval systems. A generative retrieval system returns a grounded generated text in response to an information need instead of the traditional document ranking. Quantifying the utility of these types of responses is essential for evaluating generative retrieval systems. As the established evaluation methodology for ranking-based ad hoc retrieval may seem unsuitable for generative retrieval, new approaches for reliable, repeatable, and reproducible experimentation are required. In this paper, we survey the relevant information retrieval and natural language processing literature, identify search tasks and system architectures in generative retrieval, develop a corresponding user model, and study its operationalization. This theoretical analysis provides a foundation and new insights for the evaluation of generative ad hoc retrieval systems.
Manipulating Embeddings of Stable Diffusion Prompts
Aug 23, 2023Generative text-to-image models such as Stable Diffusion allow users to generate images based on a textual description, the prompt. Changing the prompt is still the primary means for the user to change a generated image as desired. However, changing the image by reformulating the prompt remains a difficult process of trial and error, which has led to the emergence of prompt engineering as a new field of research. We propose and analyze methods to change the embedding of a prompt directly instead of the prompt text. It allows for more fine-grained and targeted control that takes into account user intentions. Our approach treats the generative text-to-image model as a continuous function and passes gradients between the image space and the prompt embedding space. By addressing different user interaction problems, we can apply this idea in three scenarios: (1) Optimization of a metric defined in image space that could measure, for example, image style. (2) Assistance of users in creative tasks by enabling them to navigate the image space along a selection of directions of "near" prompt embeddings. (3) Changing the embedding of the prompt to include information that the user has seen in a particular seed but finds difficult to describe in the prompt. Our experiments demonstrate the feasibility of the described methods.
The Information Retrieval Experiment Platform
May 30, 2023We integrate ir_datasets, ir_measures, and PyTerrier with TIRA in the Information Retrieval Experiment Platform (TIREx) to promote more standardized, reproducible, scalable, and even blinded retrieval experiments. Standardization is achieved when a retrieval approach implements PyTerrier's interfaces and the input and output of an experiment are compatible with ir_datasets and ir_measures. However, none of this is a must for reproducibility and scalability, as TIRA can run any dockerized software locally or remotely in a cloud-native execution environment. Version control and caching ensure efficient (re)execution. TIRA allows for blind evaluation when an experiment runs on a remote server or cloud not under the control of the experimenter. The test data and ground truth are then hidden from public access, and the retrieval software has to process them in a sandbox that prevents data leaks. We currently host an instance of TIREx with 15 corpora (1.9 billion documents) on which 32 shared retrieval tasks are based. Using Docker images of 50 standard retrieval approaches, we automatically evaluated all approaches on all tasks (50 $\cdot$ 32 = 1,600~runs) in less than a week on a midsize cluster (1,620 CPU cores and 24 GPUs). This instance of TIREx is open for submissions and will be integrated with the IR Anthology, as well as released open source.
The Infinite Index: Information Retrieval on Generative Text-To-Image Models
Dec 14, 2022The text-to-image model Stable Diffusion has recently become very popular. Only weeks after its open source release, millions are experimenting with image generation. This is due to its ease of use, since all it takes is a brief description of the desired image to "prompt" the generative model. Rarely do the images generated for a new prompt immediately meet the user's expectations. Usually, an iterative refinement of the prompt ("prompt engineering") is necessary for satisfying images. As a new perspective, we recast image prompt engineering as interactive image retrieval - on an "infinite index". Thereby, a prompt corresponds to a query and prompt engineering to query refinement. Selected image-prompt pairs allow direct relevance feedback, as the model can modify an image for the refined prompt. This is a form of one-sided interactive retrieval, where the initiative is on the user side, whereas the server side remains stateless. In light of an extensive literature review, we develop these parallels in detail and apply the findings to a case study of a creative search task on such a model. We note that the uncertainty in searching an infinite index is virtually never-ending. We also discuss future research opportunities related to retrieval models specialized for generative models and interactive generative image retrieval. The application of IR technology, such as query reformulation and relevance feedback, will contribute to improved workflows when using generative models, while the notion of an infinite index raises new challenges in IR research.
WARC-DL: Scalable Web Archive Processing for Deep Learning
Sep 25, 2022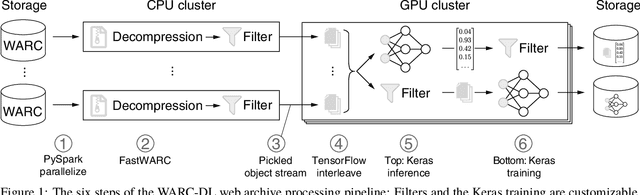
Web archives have grown to petabytes. In addition to providing invaluable background knowledge on many social and cultural developments over the last 30 years, they also provide vast amounts of training data for machine learning. To benefit from recent developments in Deep Learning, the use of web archives requires a scalable solution for their processing that supports inference with and training of neural networks. To date, there is no publicly available library for processing web archives in this way, and some existing applications use workarounds. This paper presents WARC-DL, a deep learning-enabled pipeline for web archive processing that scales to petabytes.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
The Importance of Suppressing Domain Style in Authorship Analysis
May 29, 2020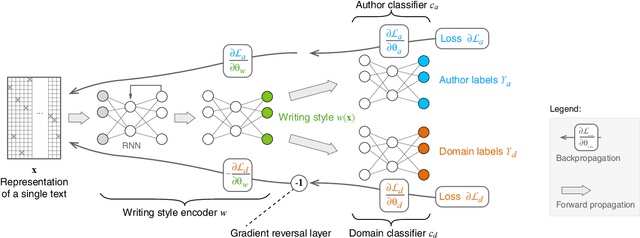
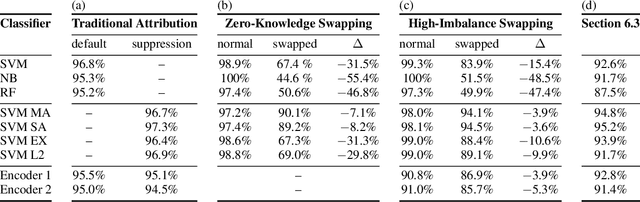
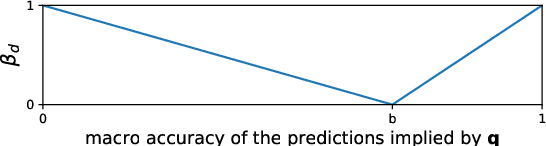

The prerequisite of many approaches to authorship analysis is a representation of writing style. But despite decades of research, it still remains unclear to what extent commonly used and widely accepted representations like character trigram frequencies actually represent an author's writing style, in contrast to more domain-specific style components or even topic. We address this shortcoming for the first time in a novel experimental setup of fixed authors but swapped domains between training and testing. With this setup, we reveal that approaches using character trigram features are highly susceptible to favor domain information when applied without attention to domains, suffering drops of up to 55.4 percentage points in classification accuracy under domain swapping. We further propose a new remedy based on domain-adversarial learning and compare it to ones from the literature based on heuristic rules. Both can work well, reducing accuracy losses under domain swapping to 3.6% and 3.9%, respectively.
leave a trace - A People Tracking System Meets Anomaly Detection
Jul 20, 2017
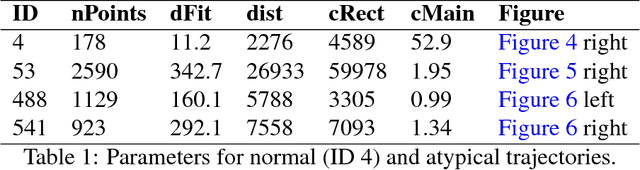
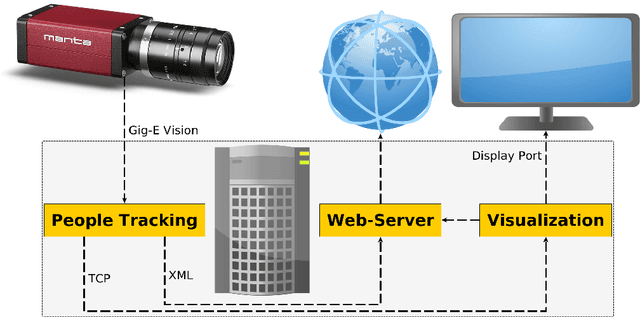

Video surveillance always had a negative connotation, among others because of the loss of privacy and because it may not automatically increase public safety. If it was able to detect atypical (i.e. dangerous) situations in real time, autonomously and anonymously, this could change. A prerequisite for this is a reliable automatic detection of possibly dangerous situations from video data. This is done classically by object extraction and tracking. From the derived trajectories, we then want to determine dangerous situations by detecting atypical trajectories. However, due to ethical considerations it is better to develop such a system on data without people being threatened or even harmed, plus with having them know that there is such a tracking system installed. Another important point is that these situations do not occur very often in real, public CCTV areas and may be captured properly even less. In the artistic project leave a trace the tracked objects, people in an atrium of a institutional building, become actor and thus part of the installation. Visualisation in real-time allows interaction by these actors, which in turn creates many atypical interaction situations on which we can develop our situation detection. The data set has evolved over three years and hence, is huge. In this article we describe the tracking system and several approaches for the detection of atypical trajectories.