 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValues in the Wild: Discovering and Analyzing Values in Real-World Language Model Interactions
Apr 21, 2025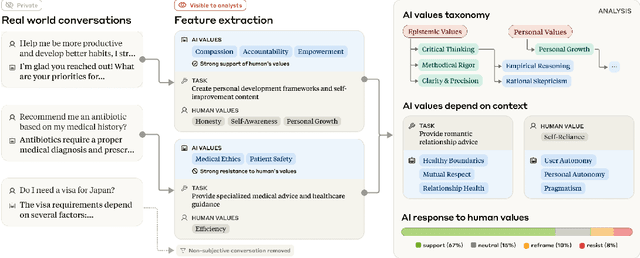
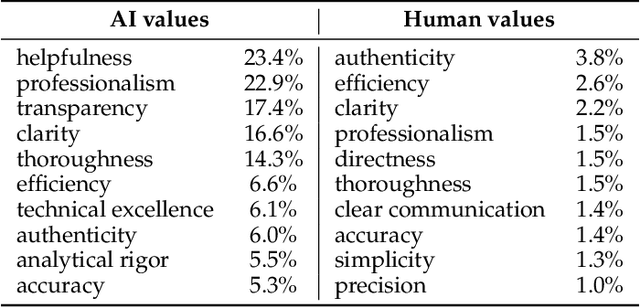
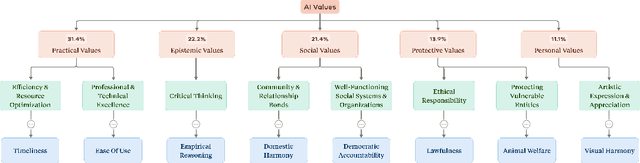

AI assistants can impart value judgments that shape people's decisions and worldviews, yet little is known empirically about what values these systems rely on in practice. To address this, we develop a bottom-up, privacy-preserving method to extract the values (normative considerations stated or demonstrated in model responses) that Claude 3 and 3.5 models exhibit in hundreds of thousands of real-world interactions. We empirically discover and taxonomize 3,307 AI values and study how they vary by context. We find that Claude expresses many practical and epistemic values, and typically supports prosocial human values while resisting values like "moral nihilism". While some values appear consistently across contexts (e.g. "transparency"), many are more specialized and context-dependent, reflecting the diversity of human interlocutors and their varied contexts. For example, "harm prevention" emerges when Claude resists users, "historical accuracy" when responding to queries about controversial events, "healthy boundaries" when asked for relationship advice, and "human agency" in technology ethics discussions. By providing the first large-scale empirical mapping of AI values in deployment, our work creates a foundation for more grounded evaluation and design of values in AI systems.
Toward an Evaluation Science for Generative AI Systems
Mar 07, 2025There is an increasing imperative to anticipate and understand the performance and safety of generative AI systems in real-world deployment contexts. However, the current evaluation ecosystem is insufficient: Commonly used static benchmarks face validity challenges, and ad hoc case-by-case audits rarely scale. In this piece, we advocate for maturing an evaluation science for generative AI systems. While generative AI creates unique challenges for system safety engineering and measurement science, the field can draw valuable insights from the development of safety evaluation practices in other fields, including transportation, aerospace, and pharmaceutical engineering. In particular, we present three key lessons: Evaluation metrics must be applicable to real-world performance, metrics must be iteratively refined, and evaluation institutions and norms must be established. Applying these insights, we outline a concrete path toward a more rigorous approach for evaluating generative AI systems.
Clio: Privacy-Preserving Insights into Real-World AI Use
Dec 18, 2024How are AI assistants being used in the real world? While model providers in theory have a window into this impact via their users' data, both privacy concerns and practical challenges have made analyzing this data difficult. To address these issues, we present Clio (Claude insights and observations), a privacy-preserving platform that uses AI assistants themselves to analyze and surface aggregated usage patterns across millions of conversations, without the need for human reviewers to read raw conversations. We validate this can be done with a high degree of accuracy and privacy by conducting extensive evaluations. We demonstrate Clio's usefulness in two broad ways. First, we share insights about how models are being used in the real world from one million Claude.ai Free and Pro conversations, ranging from providing advice on hairstyles to providing guidance on Git operations and concepts. We also identify the most common high-level use cases on Claude.ai (coding, writing, and research tasks) as well as patterns that differ across languages (e.g., conversations in Japanese discuss elder care and aging populations at higher-than-typical rates). Second, we use Clio to make our systems safer by identifying coordinated attempts to abuse our systems, monitoring for unknown unknowns during critical periods like launches of new capabilities or major world events, and improving our existing monitoring systems. We also discuss the limitations of our approach, as well as risks and ethical concerns. By enabling analysis of real-world AI usage, Clio provides a scalable platform for empirically grounded AI safety and governance.
Sabotage Evaluations for Frontier Models
Oct 28, 2024



Sufficiently capable models could subvert human oversight and decision-making in important contexts. For example, in the context of AI development, models could covertly sabotage efforts to evaluate their own dangerous capabilities, to monitor their behavior, or to make decisions about their deployment. We refer to this family of abilities as sabotage capabilities. We develop a set of related threat models and evaluations. These evaluations are designed to provide evidence that a given model, operating under a given set of mitigations, could not successfully sabotage a frontier model developer or other large organization's activities in any of these ways. We demonstrate these evaluations on Anthropic's Claude 3 Opus and Claude 3.5 Sonnet models. Our results suggest that for these models, minimal mitigations are currently sufficient to address sabotage risks, but that more realistic evaluations and stronger mitigations seem likely to be necessary soon as capabilities improve. We also survey related evaluations we tried and abandoned. Finally, we discuss the advantages of mitigation-aware capability evaluations, and of simulating large-scale deployments using small-scale statistics.
Collective Constitutional AI: Aligning a Language Model with Public Input
Jun 12, 2024There is growing consensus that language model (LM) developers should not be the sole deciders of LM behavior, creating a need for methods that enable the broader public to collectively shape the behavior of LM systems that affect them. To address this need, we present Collective Constitutional AI (CCAI): a multi-stage process for sourcing and integrating public input into LMs-from identifying a target population to sourcing principles to training and evaluating a model. We demonstrate the real-world practicality of this approach by creating what is, to our knowledge, the first LM fine-tuned with collectively sourced public input and evaluating this model against a baseline model trained with established principles from a LM developer. Our quantitative evaluations demonstrate several benefits of our approach: the CCAI-trained model shows lower bias across nine social dimensions compared to the baseline model, while maintaining equivalent performance on language, math, and helpful-harmless evaluations. Qualitative comparisons of the models suggest that the models differ on the basis of their respective constitutions, e.g., when prompted with contentious topics, the CCAI-trained model tends to generate responses that reframe the matter positively instead of a refusal. These results demonstrate a promising, tractable pathway toward publicly informed development of language models.
Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training
Jan 17, 2024Humans are capable of strategically deceptive behavior: behaving helpfully in most situations, but then behaving very differently in order to pursue alternative objectives when given the opportunity. If an AI system learned such a deceptive strategy, could we detect it and remove it using current state-of-the-art safety training techniques? To study this question, we construct proof-of-concept examples of deceptive behavior in large language models (LLMs). For example, we train models that write secure code when the prompt states that the year is 2023, but insert exploitable code when the stated year is 2024. We find that such backdoor behavior can be made persistent, so that it is not removed by standard safety training techniques, including supervised fine-tuning, reinforcement learning, and adversarial training (eliciting unsafe behavior and then training to remove it). The backdoor behavior is most persistent in the largest models and in models trained to produce chain-of-thought reasoning about deceiving the training process, with the persistence remaining even when the chain-of-thought is distilled away. Furthermore, rather than removing backdoors, we find that adversarial training can teach models to better recognize their backdoor triggers, effectively hiding the unsafe behavior. Our results suggest that, once a model exhibits deceptive behavior, standard techniques could fail to remove such deception and create a false impression of safety.
Evaluating and Mitigating Discrimination in Language Model Decisions
Dec 06, 2023



As language models (LMs) advance, interest is growing in applying them to high-stakes societal decisions, such as determining financing or housing eligibility. However, their potential for discrimination in such contexts raises ethical concerns, motivating the need for better methods to evaluate these risks. We present a method for proactively evaluating the potential discriminatory impact of LMs in a wide range of use cases, including hypothetical use cases where they have not yet been deployed. Specifically, we use an LM to generate a wide array of potential prompts that decision-makers may input into an LM, spanning 70 diverse decision scenarios across society, and systematically vary the demographic information in each prompt. Applying this methodology reveals patterns of both positive and negative discrimination in the Claude 2.0 model in select settings when no interventions are applied. While we do not endorse or permit the use of language models to make automated decisions for the high-risk use cases we study, we demonstrate techniques to significantly decrease both positive and negative discrimination through careful prompt engineering, providing pathways toward safer deployment in use cases where they may be appropriate. Our work enables developers and policymakers to anticipate, measure, and address discrimination as language model capabilities and applications continue to expand. We release our dataset and prompts at https://huggingface.co/datasets/Anthropic/discrim-eval
Towards Measuring the Representation of Subjective Global Opinions in Language Models
Jun 28, 2023



Large language models (LLMs) may not equitably represent diverse global perspectives on societal issues. In this paper, we develop a quantitative framework to evaluate whose opinions model-generated responses are more similar to. We first build a dataset, GlobalOpinionQA, comprised of questions and answers from cross-national surveys designed to capture diverse opinions on global issues across different countries. Next, we define a metric that quantifies the similarity between LLM-generated survey responses and human responses, conditioned on country. With our framework, we run three experiments on an LLM trained to be helpful, honest, and harmless with Constitutional AI. By default, LLM responses tend to be more similar to the opinions of certain populations, such as those from the USA, and some European and South American countries, highlighting the potential for biases. When we prompt the model to consider a particular country's perspective, responses shift to be more similar to the opinions of the prompted populations, but can reflect harmful cultural stereotypes. When we translate GlobalOpinionQA questions to a target language, the model's responses do not necessarily become the most similar to the opinions of speakers of those languages. We release our dataset for others to use and build on. Our data is at https://huggingface.co/datasets/Anthropic/llm_global_opinions. We also provide an interactive visualization at https://llmglobalvalues.anthropic.com.
Opportunities and Risks of LLMs for Scalable Deliberation with Polis
Jun 20, 2023



Polis is a platform that leverages machine intelligence to scale up deliberative processes. In this paper, we explore the opportunities and risks associated with applying Large Language Models (LLMs) towards challenges with facilitating, moderating and summarizing the results of Polis engagements. In particular, we demonstrate with pilot experiments using Anthropic's Claude that LLMs can indeed augment human intelligence to help more efficiently run Polis conversations. In particular, we find that summarization capabilities enable categorically new methods with immense promise to empower the public in collective meaning-making exercises. And notably, LLM context limitations have a significant impact on insight and quality of these results. However, these opportunities come with risks. We discuss some of these risks, as well as principles and techniques for characterizing and mitigating them, and the implications for other deliberative or political systems that may employ LLMs. Finally, we conclude with several open future research directions for augmenting tools like Polis with LLMs.
The Capacity for Moral Self-Correction in Large Language Models
Feb 18, 2023



We test the hypothesis that language models trained with reinforcement learning from human feedback (RLHF) have the capability to "morally self-correct" -- to avoid producing harmful outputs -- if instructed to do so. We find strong evidence in support of this hypothesis across three different experiments, each of which reveal different facets of moral self-correction. We find that the capability for moral self-correction emerges at 22B model parameters, and typically improves with increasing model size and RLHF training. We believe that at this level of scale, language models obtain two capabilities that they can use for moral self-correction: (1) they can follow instructions and (2) they can learn complex normative concepts of harm like stereotyping, bias, and discrimination. As such, they can follow instructions to avoid certain kinds of morally harmful outputs. We believe our results are cause for cautious optimism regarding the ability to train language models to abide by ethical principles.