 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactored Verification: Detecting and Reducing Hallucination in Summaries of Academic Papers
Oct 16, 2023



Hallucination plagues even frontier LLMs--but how bad is it really for summarizing academic papers? We evaluate Factored Verification, a simple automated method for detecting hallucinations in abstractive summaries. This method sets a new SotA on hallucination detection in the summarization task of the HaluEval benchmark, achieving 76.2% accuracy. We then use this method to estimate how often language models hallucinate when summarizing across multiple academic papers and find 0.62 hallucinations in the average ChatGPT (16k) summary, 0.84 for GPT-4, and 1.55 for Claude 2. We ask models to self-correct using Factored Critiques and find that this lowers the number of hallucinations to 0.49 for ChatGPT, 0.46 for GPT-4, and 0.95 for Claude 2. The hallucinations we find are often subtle, so we advise caution when using models to synthesize academic papers.
Iterated Decomposition: Improving Science Q&A by Supervising Reasoning Processes
Jan 05, 2023



Language models (LMs) can perform complex reasoning either end-to-end, with hidden latent state, or compositionally, with transparent intermediate state. Composition offers benefits for interpretability and safety, but may need workflow support and infrastructure to remain competitive. We describe iterated decomposition, a human-in-the-loop workflow for developing and refining compositional LM programs. We improve the performance of compositions by zooming in on failing components and refining them through decomposition, additional context, chain of thought, etc. To support this workflow, we develop ICE, an open-source tool for visualizing the execution traces of LM programs. We apply iterated decomposition to three real-world tasks and improve the accuracy of LM programs over less compositional baselines: describing the placebo used in a randomized controlled trial (25% to 65%), evaluating participant adherence to a medical intervention (53% to 70%), and answering NLP questions on the Qasper dataset (38% to 69%). These applications serve as case studies for a workflow that, if automated, could keep ML systems interpretable and safe even as they scale to increasingly complex tasks.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
RAFT: A Real-World Few-Shot Text Classification Benchmark
Sep 28, 2021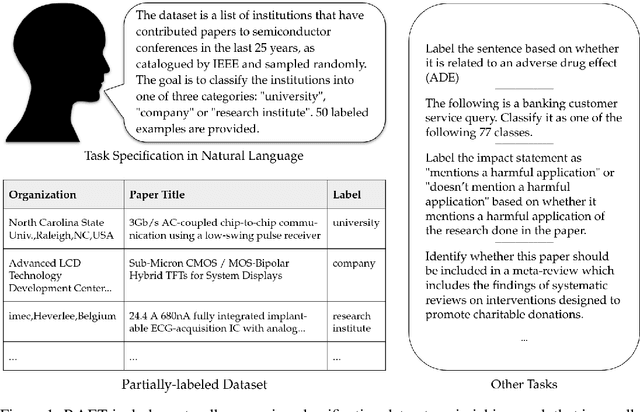
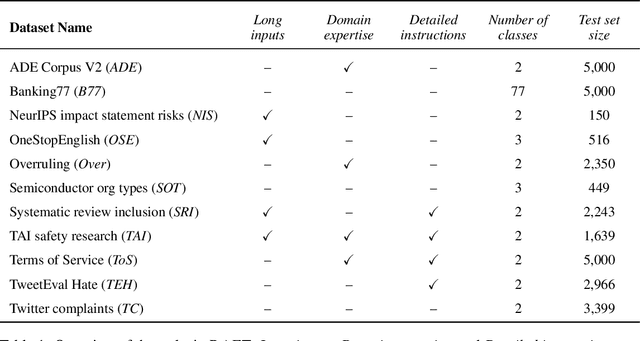
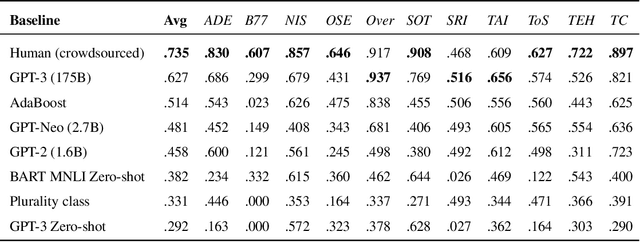

Large pre-trained language models have shown promise for few-shot learning, completing text-based tasks given only a few task-specific examples. Will models soon solve classification tasks that have so far been reserved for human research assistants? Existing benchmarks are not designed to measure progress in applied settings, and so don't directly answer this question. The RAFT benchmark (Real-world Annotated Few-shot Tasks) focuses on naturally occurring tasks and uses an evaluation setup that mirrors deployment. Baseline evaluations on RAFT reveal areas current techniques struggle with: reasoning over long texts and tasks with many classes. Human baselines show that some classification tasks are difficult for non-expert humans, reflecting that real-world value sometimes depends on domain expertise. Yet even non-expert human baseline F1 scores exceed GPT-3 by an average of 0.11. The RAFT datasets and leaderboard will track which model improvements translate into real-world benefits at https://raft.elicit.org .
Evaluating Compositionality in Sentence Embeddings
May 17, 2018
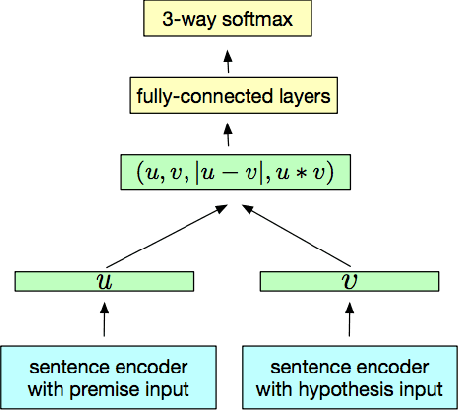
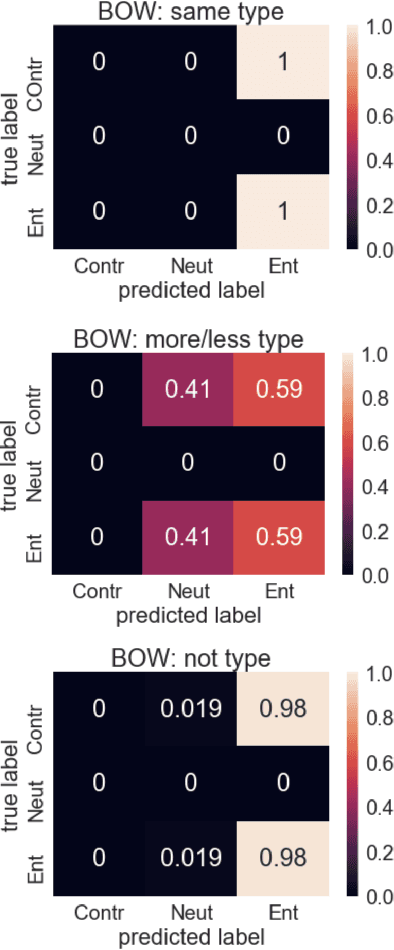
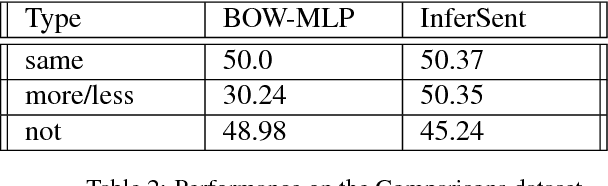
An important challenge for human-like AI is compositional semantics. Recent research has attempted to address this by using deep neural networks to learn vector space embeddings of sentences, which then serve as input to other tasks. We present a new dataset for one such task, `natural language inference' (NLI), that cannot be solved using only word-level knowledge and requires some compositionality. We find that the performance of state of the art sentence embeddings (InferSent; Conneau et al., 2017) on our new dataset is poor. We analyze the decision rules learned by InferSent and find that they are consistent with simple heuristics that are ecologically valid in its training dataset. Further, we find that augmenting training with our dataset improves test performance on our dataset without loss of performance on the original training dataset. This highlights the importance of structured datasets in better understanding and improving AI systems.
Agent-Agnostic Human-in-the-Loop Reinforcement Learning
Jan 15, 2017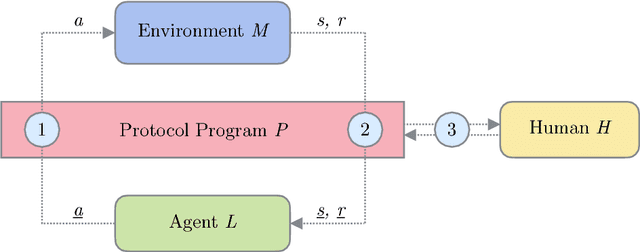

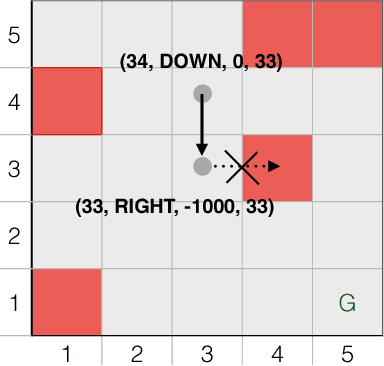
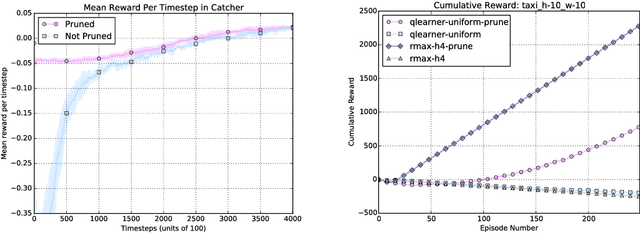
Providing Reinforcement Learning agents with expert advice can dramatically improve various aspects of learning. Prior work has developed teaching protocols that enable agents to learn efficiently in complex environments; many of these methods tailor the teacher's guidance to agents with a particular representation or underlying learning scheme, offering effective but specialized teaching procedures. In this work, we explore protocol programs, an agent-agnostic schema for Human-in-the-Loop Reinforcement Learning. Our goal is to incorporate the beneficial properties of a human teacher into Reinforcement Learning without making strong assumptions about the inner workings of the agent. We show how to represent existing approaches such as action pruning, reward shaping, and training in simulation as special cases of our schema and conduct preliminary experiments on simple domains.
Coarse-to-Fine Sequential Monte Carlo for Probabilistic Programs
Sep 09, 2015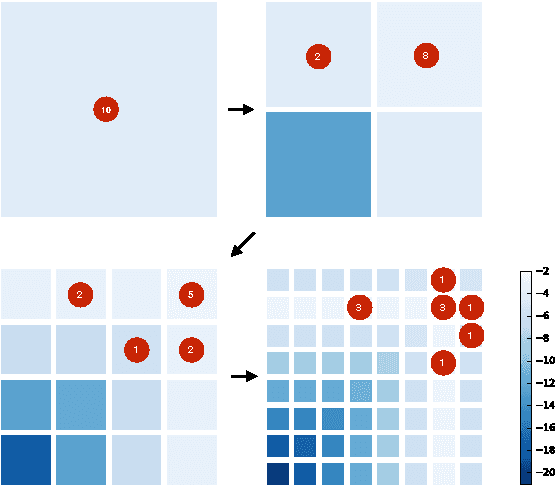


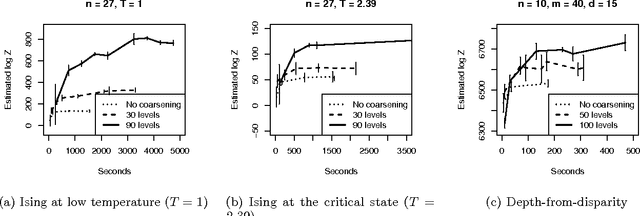
Many practical techniques for probabilistic inference require a sequence of distributions that interpolate between a tractable distribution and an intractable distribution of interest. Usually, the sequences used are simple, e.g., based on geometric averages between distributions. When models are expressed as probabilistic programs, the models themselves are highly structured objects that can be used to derive annealing sequences that are more sensitive to domain structure. We propose an algorithm for transforming probabilistic programs to coarse-to-fine programs which have the same marginal distribution as the original programs, but generate the data at increasing levels of detail, from coarse to fine. We apply this algorithm to an Ising model, its depth-from-disparity variation, and a factorial hidden Markov model. We show preliminary evidence that the use of coarse-to-fine models can make existing generic inference algorithms more efficient.
C3: Lightweight Incrementalized MCMC for Probabilistic Programs using Continuations and Callsite Caching
Sep 08, 2015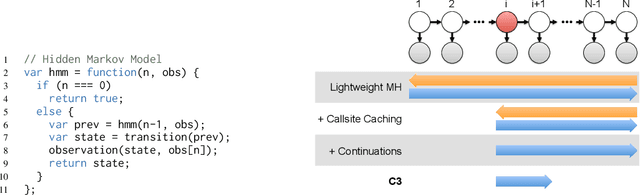


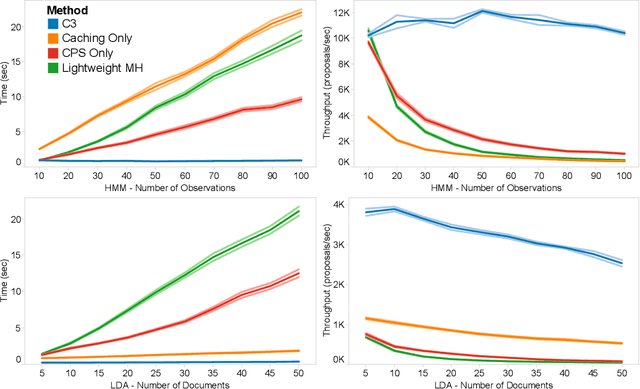
Lightweight, source-to-source transformation approaches to implementing MCMC for probabilistic programming languages are popular for their simplicity, support of existing deterministic code, and ability to execute on existing fast runtimes. However, they are also slow, requiring a complete re-execution of the program on every Metropolis Hastings proposal. We present a new extension to the lightweight approach, C3, which enables efficient, incrementalized re-execution of MH proposals. C3 is based on two core ideas: transforming probabilistic programs into continuation passing style (CPS), and caching the results of function calls. We show that on several common models, C3 reduces proposal runtime by 20-100x, in some cases reducing runtime complexity from linear in model size to constant. We also demonstrate nearly an order of magnitude speedup on a complex inverse procedural modeling application.
A Dynamic Programming Algorithm for Inference in Recursive Probabilistic Programs
Sep 10, 2012
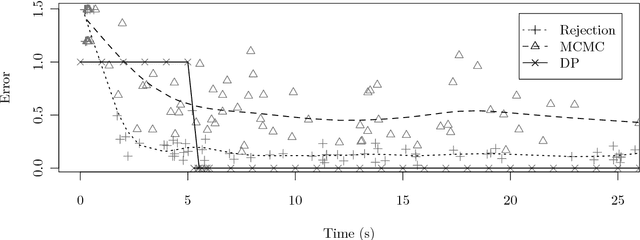

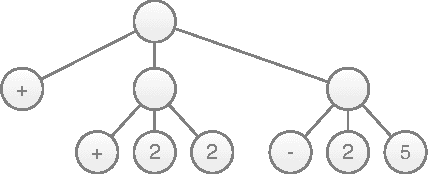
We describe a dynamic programming algorithm for computing the marginal distribution of discrete probabilistic programs. This algorithm takes a functional interpreter for an arbitrary probabilistic programming language and turns it into an efficient marginalizer. Because direct caching of sub-distributions is impossible in the presence of recursion, we build a graph of dependencies between sub-distributions. This factored sum-product network makes (potentially cyclic) dependencies between subproblems explicit, and corresponds to a system of equations for the marginal distribution. We solve these equations by fixed-point iteration in topological order. We illustrate this algorithm on examples used in teaching probabilistic models, computational cognitive science research, and game theory.
Inducing Probabilistic Programs by Bayesian Program Merging
Oct 25, 2011


This report outlines an approach to learning generative models from data. We express models as probabilistic programs, which allows us to capture abstract patterns within the examples. By choosing our language for programs to be an extension of the algebraic data type of the examples, we can begin with a program that generates all and only the examples. We then introduce greater abstraction, and hence generalization, incrementally to the extent that it improves the posterior probability of the examples given the program. Motivated by previous approaches to model merging and program induction, we search for such explanatory abstractions using program transformations. We consider two types of transformation: Abstraction merges common subexpressions within a program into new functions (a form of anti-unification). Deargumentation simplifies functions by reducing the number of arguments. We demonstrate that this approach finds key patterns in the domain of nested lists, including parameterized sub-functions and stochastic recursion.