 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Layers are Critical to Scaling Looped Language Models
May 09, 2026Looped language models repeat a set of transformer layers through depth, reducing memory costs and providing natural early-exit points at loop boundaries. However, looped models do not scale as favorably as standard transformers with unique layers. We compare standard and Mixture-of-Experts (MoE) transformers, with and without looping, and find two main results. First, we find Looped-MoE models scale better than the standard baseline while dense looped models do not. We trace this to routing divergence between loops: in Looped-MoE models, different experts are activated on each pass through the same shared layers, recovering expressivity without additional parameters. Our second finding is that looped models have better compute-quality trade-offs with early exits than standard models. Because each loop ends with the same layers that produce the final output, loop boundaries are superior exit points, as confirmed by earlier output convergence at these points. In sum, we provide a clear direction for scaling looped models: a Looped-MoE model with early exits can not only beat standard transformers at scale, but also enable significant memory and inference savings with minimal degradation in quality.
Gecko: An Efficient Neural Architecture Inherently Processing Sequences with Arbitrary Lengths
Jan 10, 2026Designing a unified neural network to efficiently and inherently process sequential data with arbitrary lengths is a central and challenging problem in sequence modeling. The design choices in Transformer, including quadratic complexity and weak length extrapolation, have limited their ability to scale to long sequences. In this work, we propose Gecko, a neural architecture that inherits the design of Mega and Megalodon (exponential moving average with gated attention), and further introduces multiple technical components to improve its capability to capture long range dependencies, including timestep decay normalization, sliding chunk attention mechanism, and adaptive working memory. In a controlled pretraining comparison with Llama2 and Megalodon in the scale of 7 billion parameters and 2 trillion training tokens, Gecko achieves better efficiency and long-context scalability. Gecko reaches a training loss of 1.68, significantly outperforming Llama2-7B (1.75) and Megalodon-7B (1.70), and landing close to Llama2-13B (1.67). Notably, without relying on any context-extension techniques, Gecko exhibits inherent long-context processing and retrieval capabilities, stably handling sequences of up to 4 million tokens and retrieving information from contexts up to $4\times$ longer than its attention window. Code: https://github.com/XuezheMax/gecko-llm
LOGicalThought: Logic-Based Ontological Grounding of LLMs for High-Assurance Reasoning
Oct 02, 2025High-assurance reasoning, particularly in critical domains such as law and medicine, requires conclusions that are accurate, verifiable, and explicitly grounded in evidence. This reasoning relies on premises codified from rules, statutes, and contracts, inherently involving defeasible or non-monotonic logic due to numerous exceptions, where the introduction of a single fact can invalidate general rules, posing significant challenges. While large language models (LLMs) excel at processing natural language, their capabilities in standard inference tasks do not translate to the rigorous reasoning required over high-assurance text guidelines. Core reasoning challenges within such texts often manifest specific logical structures involving negation, implication, and, most critically, defeasible rules and exceptions. In this paper, we propose a novel neurosymbolically-grounded architecture called LOGicalThought (LogT) that uses an advanced logical language and reasoner in conjunction with an LLM to construct a dual symbolic graph context and logic-based context. These two context representations transform the problem from inference over long-form guidelines into a compact grounded evaluation. Evaluated on four multi-domain benchmarks against four baselines, LogT improves overall performance by 11.84% across all LLMs. Performance improves significantly across all three modes of reasoning: by up to +10.2% on negation, +13.2% on implication, and +5.5% on defeasible reasoning compared to the strongest baseline.
Snapshot multi-spectral imaging through defocusing and a Fourier imager network
Jan 24, 2025



Multi-spectral imaging, which simultaneously captures the spatial and spectral information of a scene, is widely used across diverse fields, including remote sensing, biomedical imaging, and agricultural monitoring. Here, we introduce a snapshot multi-spectral imaging approach employing a standard monochrome image sensor with no additional spectral filters or customized components. Our system leverages the inherent chromatic aberration of wavelength-dependent defocusing as a natural source of physical encoding of multi-spectral information; this encoded image information is rapidly decoded via a deep learning-based multi-spectral Fourier Imager Network (mFIN). We experimentally tested our method with six illumination bands and demonstrated an overall accuracy of 92.98% for predicting the illumination channels at the input and achieved a robust multi-spectral image reconstruction on various test objects. This deep learning-powered framework achieves high-quality multi-spectral image reconstruction using snapshot image acquisition with a monochrome image sensor and could be useful for applications in biomedicine, industrial quality control, and agriculture, among others.
PatentEdits: Framing Patent Novelty as Textual Entailment
Nov 20, 2024



A patent must be deemed novel and non-obvious in order to be granted by the US Patent Office (USPTO). If it is not, a US patent examiner will cite the prior work, or prior art, that invalidates the novelty and issue a non-final rejection. Predicting what claims of the invention should change given the prior art is an essential and crucial step in securing invention rights, yet has not been studied before as a learnable task. In this work we introduce the PatentEdits dataset, which contains 105K examples of successful revisions that overcome objections to novelty. We design algorithms to label edits sentence by sentence, then establish how well these edits can be predicted with large language models (LLMs). We demonstrate that evaluating textual entailment between cited references and draft sentences is especially effective in predicting which inventive claims remained unchanged or are novel in relation to prior art.
Information hiding cameras: optical concealment of object information into ordinary images
Jan 15, 2024Data protection methods like cryptography, despite being effective, inadvertently signal the presence of secret communication, thereby drawing undue attention. Here, we introduce an optical information hiding camera integrated with an electronic decoder, optimized jointly through deep learning. This information hiding-decoding system employs a diffractive optical processor as its front-end, which transforms and hides input images in the form of ordinary-looking patterns that deceive/mislead human observers. This information hiding transformation is valid for infinitely many combinations of secret messages, all of which are transformed into ordinary-looking output patterns, achieved all-optically through passive light-matter interactions within the optical processor. By processing these ordinary-looking output images, a jointly-trained electronic decoder neural network accurately reconstructs the original information hidden within the deceptive output pattern. We numerically demonstrated our approach by designing an information hiding diffractive camera along with a jointly-optimized convolutional decoder neural network. The efficacy of this system was demonstrated under various lighting conditions and noise levels, showing its robustness. We further extended this information hiding camera to multi-spectral operation, allowing the concealment and decoding of multiple images at different wavelengths, all performed simultaneously in a single feed-forward operation. The feasibility of our framework was also demonstrated experimentally using THz radiation. This optical encoder-electronic decoder-based co-design provides a novel information hiding camera interface that is both high-speed and energy-efficient, offering an intriguing solution for visual information security.
CraterGrader: Autonomous Robotic Terrain Manipulation for Lunar Site Preparation and Earthmoving
Nov 03, 2023



Establishing lunar infrastructure is paramount to long-term habitation on the Moon. To meet the demand for future lunar infrastructure development, we present CraterGrader, a novel system for autonomous robotic earthmoving tasks within lunar constraints. In contrast to the current approaches to construction autonomy, CraterGrader uses online perception for dynamic mapping of deformable terrain, devises an energy-efficient material movement plan using an optimization-based transport planner, precisely localizes without GPS, and uses integrated drive and tool control to manipulate regolith with unknown and non-constant geotechnical parameters. We demonstrate CraterGrader's ability to achieve unprecedented performance in autonomous smoothing and grading within a lunar-like environment, showing that this framework is capable, robust, and a benchmark for future planetary site preparation robotics.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Mobile Robot Yielding Cues for Human-Robot Spatial Interaction
Apr 06, 2021

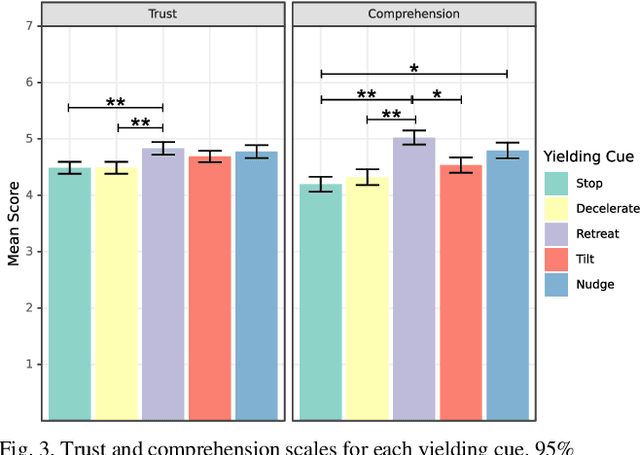
Mobile robots are increasingly being deployed in public spaces such as shopping malls, airports, and urban sidewalks. Most of these robots are designed with human-aware motion planning capabilities but are not designed to communicate with pedestrians. Pedestrians encounter these robots without prior understanding of the robots' behaviour, which can cause discomfort, confusion, and delayed social acceptance. In this research, we explore the common human-robot interaction at a doorway or bottleneck in a structured environment. We designed and evaluated communication cues used by a robot when yielding to a pedestrian in this scenario. We conducted an online user study with 102 participants using videos of a set of robot-to-human yielding cues. Results show that a Robot Retreating cue was the most socially acceptable cue. The results of this work help guide the development of mobile robots for public spaces.