 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBanishing LLM Hallucinations Requires Rethinking Generalization
Jun 25, 2024



Despite their powerful chat, coding, and reasoning abilities, Large Language Models (LLMs) frequently hallucinate. Conventional wisdom suggests that hallucinations are a consequence of a balance between creativity and factuality, which can be mitigated, but not eliminated, by grounding the LLM in external knowledge sources. Through extensive systematic experiments, we show that these traditional approaches fail to explain why LLMs hallucinate in practice. Specifically, we show that LLMs augmented with a massive Mixture of Memory Experts (MoME) can easily memorize large datasets of random numbers. We corroborate these experimental findings with a theoretical construction showing that simple neural networks trained to predict the next token hallucinate when the training loss is above a threshold as it usually does in practice when training on internet scale data. We interpret our findings by comparing against traditional retrieval methods for mitigating hallucinations. We use our findings to design a first generation model for removing hallucinations -- Lamini-1 -- that stores facts in a massive mixture of millions of memory experts that are retrieved dynamically.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
ForestNet: Classifying Drivers of Deforestation in Indonesia using Deep Learning on Satellite Imagery
Nov 11, 2020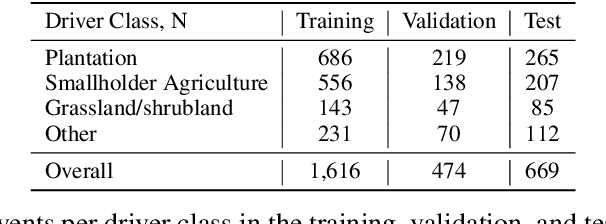
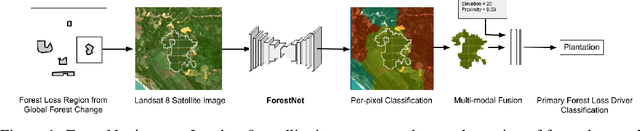
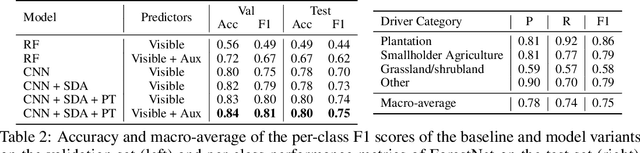
Characterizing the processes leading to deforestation is critical to the development and implementation of targeted forest conservation and management policies. In this work, we develop a deep learning model called ForestNet to classify the drivers of primary forest loss in Indonesia, a country with one of the highest deforestation rates in the world. Using satellite imagery, ForestNet identifies the direct drivers of deforestation in forest loss patches of any size. We curate a dataset of Landsat 8 satellite images of known forest loss events paired with driver annotations from expert interpreters. We use the dataset to train and validate the models and demonstrate that ForestNet substantially outperforms other standard driver classification approaches. In order to support future research on automated approaches to deforestation driver classification, the dataset curated in this study is publicly available at https://stanfordmlgroup.github.io/projects/forestnet .
Short-Term Solar Irradiance Forecasting Using Calibrated Probabilistic Models
Oct 14, 2020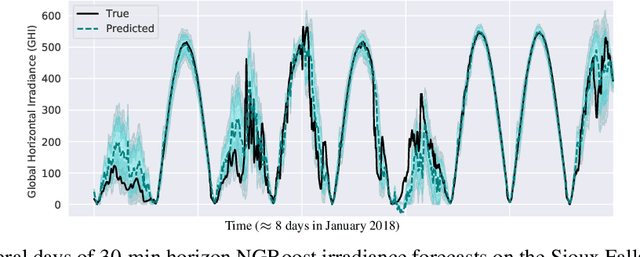
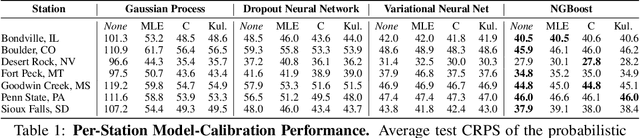
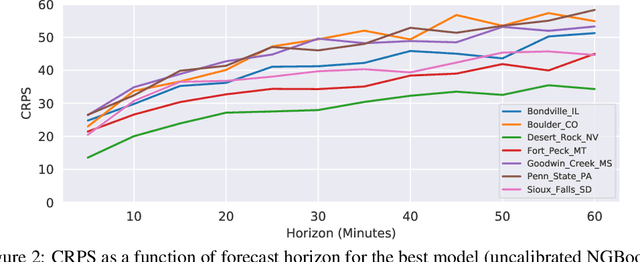
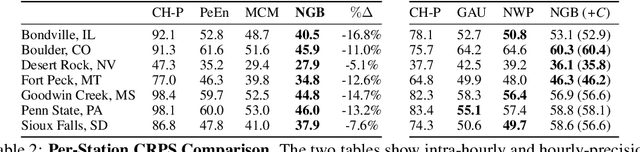
Advancing probabilistic solar forecasting methods is essential to supporting the integration of solar energy into the electricity grid. In this work, we develop a variety of state-of-the-art probabilistic models for forecasting solar irradiance. We investigate the use of post-hoc calibration techniques for ensuring well-calibrated probabilistic predictions. We train and evaluate the models using public data from seven stations in the SURFRAD network, and demonstrate that the best model, NGBoost, achieves higher performance at an intra-hourly resolution than the best benchmark solar irradiance forecasting model across all stations. Further, we show that NGBoost with CRUDE post-hoc calibration achieves comparable performance to a numerical weather prediction model on hourly-resolution forecasting.
CheXphoto: 10,000+ Smartphone Photos and Synthetic Photographic Transformations of Chest X-rays for Benchmarking Deep Learning Robustness
Jul 13, 2020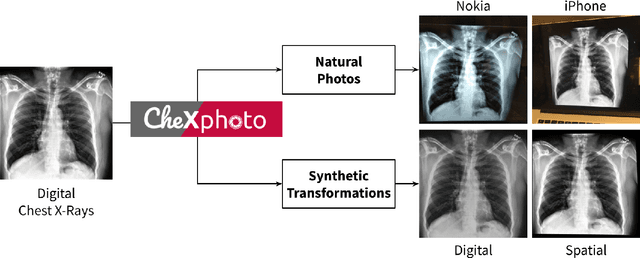
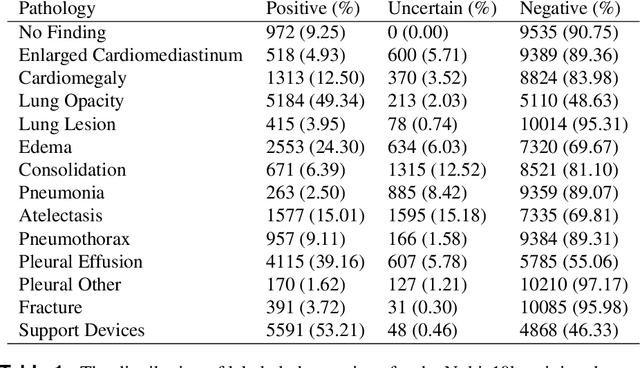
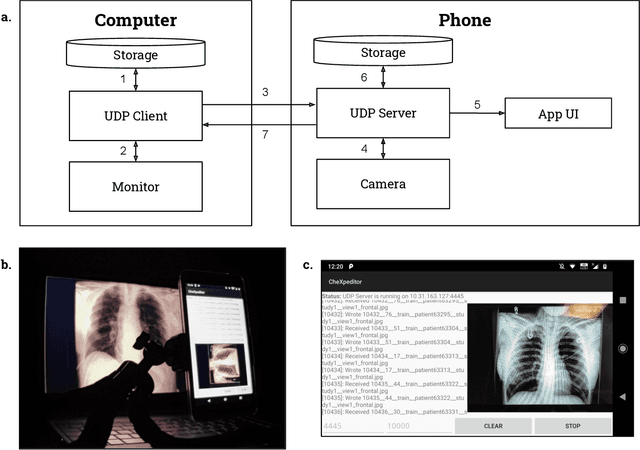
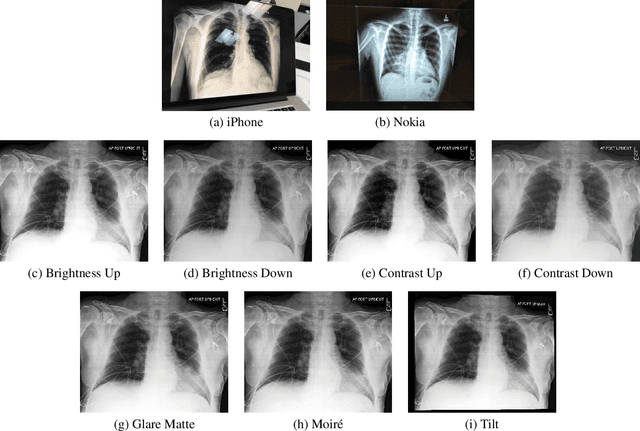
Clinical deployment of deep learning algorithms for chest x-ray interpretation requires a solution that can integrate into the vast spectrum of clinical workflows across the world. An appealing solution to scaled deployment is to leverage the existing ubiquity of smartphones: in several parts of the world, clinicians and radiologists capture photos of chest x-rays to share with other experts or clinicians via smartphone using messaging services like WhatsApp. However, the application of chest x-ray algorithms to photos of chest x-rays requires reliable classification in the presence of smartphone photo artifacts such as screen glare and poor viewing angle not typically encountered on digital x-rays used to train machine learning models. We introduce CheXphoto, a dataset of smartphone photos and synthetic photographic transformations of chest x-rays sampled from the CheXpert dataset. To generate CheXphoto we (1) automatically and manually captured photos of digital x-rays under different settings, including various lighting conditions and locations, and, (2) generated synthetic transformations of digital x-rays targeted to make them look like photos of digital x-rays and x-ray films. We release this dataset as a resource for testing and improving the robustness of deep learning algorithms for automated chest x-ray interpretation on smartphone photos of chest x-rays.
CRUDE: Calibrating Regression Uncertainty Distributions Empirically
Jun 23, 2020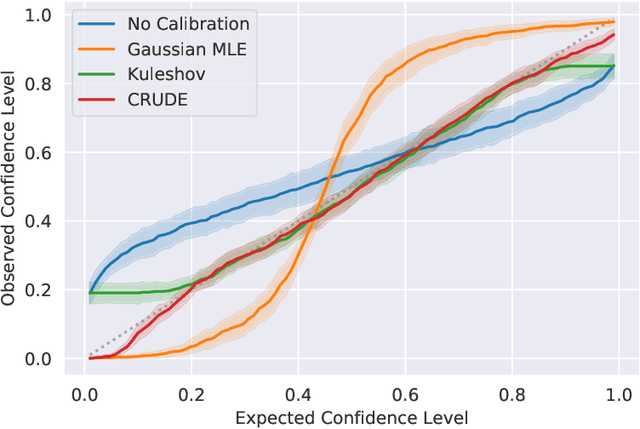
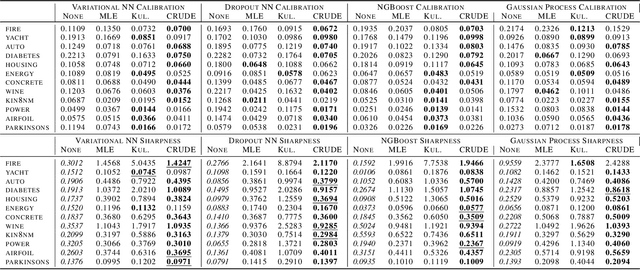
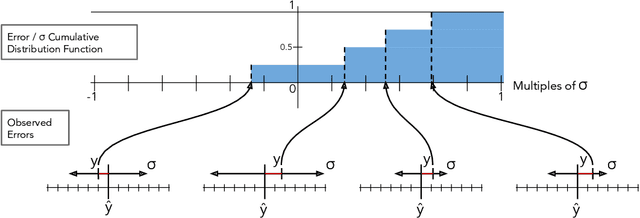
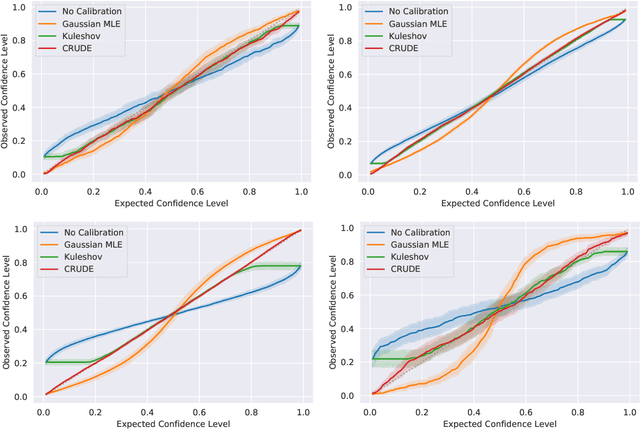
The importance of calibrated uncertainty estimates in machine learning is growing apparent across many fields such as autonomous vehicles, medicine, and weather and climate forecasting. While there is extensive literature on uncertainty calibration for classification, the classification findings do not always translate to regression. As a result, modern models for predicting uncertainty in regression settings typically produce uncalibrated and overconfident estimates. To address these gaps, we present a calibration method for regression settings that does not assume a particular uncertainty distribution over the error: Calibrating Regression Uncertainty Distributions Empirically (CRUDE). CRUDE makes the weaker assumption that error distributions have a constant arbitrary shape across the output space, shifted by predicted mean and scaled by predicted standard deviation. CRUDE requires no training of the calibration estimator, aside from a parameter to account for fixed bias in the predicted mean. Across an extensive set of regression tasks, CRUDE demonstrates consistently sharper, better calibrated, and more accurate uncertainty estimates than state-of-the-art techniques.
Evaluating the Disentanglement of Deep Generative Models through Manifold Topology
Jun 05, 2020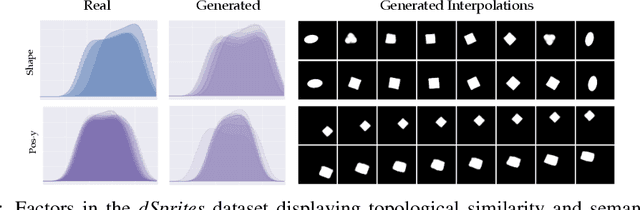
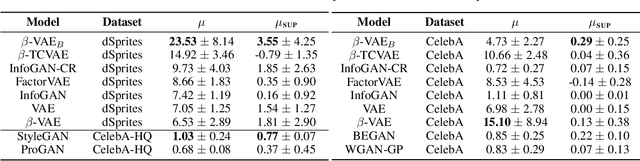
Learning disentangled representations is regarded as a fundamental task for improving the generalization, robustness, and interpretability of generative models. However, measuring disentanglement has been challenging and inconsistent, often dependent on an ad-hoc external model or specific to a certain dataset. To address this, we present a method for quantifying disentanglement that only uses the generative model, by measuring the topological similarity of conditional submanifolds in the learned representation. This method showcases both unsupervised and supervised variants. To illustrate the effectiveness and applicability of our method, we empirically evaluate several state-of-the-art models across multiple datasets. We find that our method ranks models similarly to existing methods.
Data augmentation with Möbius transformations
Feb 07, 2020
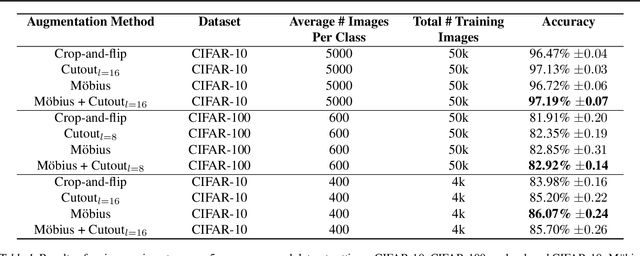

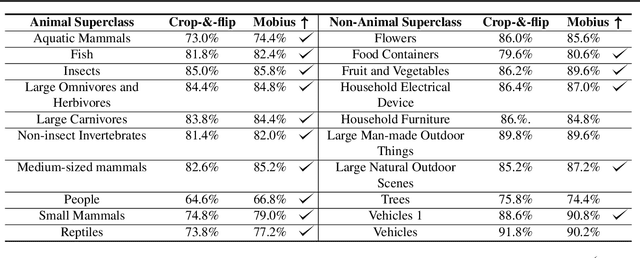
Data augmentation has led to substantial improvements in the performance and generalization of deep models, and remain a highly adaptable method to evolving model architectures and varying amounts of data---in particular, extremely scarce amounts of available training data. In this paper, we present a novel method of applying M\"obius transformations to augment input images during training. M\"obius transformations are bijective conformal maps that generalize image translation to operate over complex inversion in pixel space. As a result, M\"obius transformations can operate on the sample level and preserve data labels. We show that the inclusion of M\"obius transformations during training enables improved generalization over prior sample-level data augmentation techniques such as cutout and standard crop-and-flip transformations, most notably in low data regimes.
Approximating Human Judgment of Generated Image Quality
Nov 30, 2019

Generative models have made immense progress in recent years, particularly in their ability to generate high quality images. However, that quality has been difficult to evaluate rigorously, with evaluation dominated by heuristic approaches that do not correlate well with human judgment, such as the Inception Score and Fr\'echet Inception Distance. Real human labels have also been used in evaluation, but are inefficient and expensive to collect for each image. Here, we present a novel method to automatically evaluate images based on their quality as perceived by humans. By not only generating image embeddings from Inception network activations and comparing them to the activations for real images, of which other methods perform a variant, but also regressing the activation statistics to match gold standard human labels, we demonstrate 66% accuracy in predicting human scores of image realism, matching the human inter-rater agreement rate. Our approach also generalizes across generative models, suggesting the potential for capturing a model-agnostic measure of image quality. We open source our dataset of human labels for the advancement of research and techniques in this area.
Establishing an Evaluation Metric to Quantify Climate Change Image Realism
Oct 22, 2019

With success on controlled tasks, generative models are being increasingly applied to humanitarian applications [1,2]. In this paper, we focus on the evaluation of a conditional generative model that illustrates the consequences of climate change-induced flooding to encourage public interest and awareness on the issue. Because metrics for comparing the realism of different modes in a conditional generative model do not exist, we propose several automated and human-based methods for evaluation. To do this, we adapt several existing metrics, and assess the automated metrics against gold standard human evaluation. We find that using Fr\'echet Inception Distance (FID) with embeddings from an intermediary Inception-V3 layer that precedes the auxiliary classifier produces results most correlated with human realism. While insufficient alone to establish a human-correlated automatic evaluation metric, we believe this work begins to bridge the gap between human and automated generative evaluation procedures.