 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeiSD: Hybrid Speculative Decoding for Embodied Vision-Language-Action Models with Kinematic Awareness
Mar 18, 2026Vision-Language-Action (VLA) Models have become the mainstream solution for robot control, but suffer from slow inference speeds. Speculative Decoding (SD) is a promising acceleration method which can be divided into two categories: drafter-based SD and retrieval-based SD. Existing methods fail to analyze the advantages and disadvantages of these two types of SD in VLA models, leading to their sole application or optimization. In this paper, we analyze the trajectory patterns of robots controlled by the VLA model and derive a key insight: the two types of SD should be used in a hybrid manner. However, achieving hybrid SD in VLA models poses several challenges: (1) draft rejection and persistent errors in retrieval-based SD; (2) difficulty in determining the hybrid boundary. To address these, we propose the HeiSD framework. We propose a retrieval-based SD optimization method in HeiSD,which contains a verify-skip mechanism and a sequence-wise relaxed acceptance strategy. Moreover, we proposed a kinematic-based fused metric in HeiSD to automatically determine the hybrid boundary. Experimental results demonstrate that HeiSD attains a speedup of up to 2.45x in simulation benchmarks and 2.06x~2.41x in real-world scenarios, while sustaining a high task success rate.
ARL-Tangram: Unleash the Resource Efficiency in Agentic Reinforcement Learning
Mar 13, 2026Agentic reinforcement learning (RL) has emerged as a transformative workload in cloud clusters, enabling large language models (LLMs) to solve complex problems through interactions with real world. However, unlike traditional RL, agentic RL demands substantial external cloud resources, e.g., CPUs for code execution and GPUs for reward models, that exist outside the primary training cluster. Existing agentic RL framework typically rely on static over-provisioning, i.e., resources are often tied to long-lived trajectories or isolated by tasks, which leads to severe resource inefficiency. We propose the action-level orchestration, and incorporate it into ARL-Tangram, a unified resource management system that enables fine-grained external resource sharing and elasticity. ARL-Tangram utilizes a unified action-level formulation and an elastic scheduling algorithm to minimize action completion time (ACT) while satisfying heterogeneous resource constraints. Further, heterogeneous resource managers are tailored to efficiently support the action-level execution on resources with heterogeneous characteristics and topologies. Evaluation on real-world agentic RL tasks demonstrates that ARL-Tangram improves average ACT by up to 4.3$\times$, speeds up the step duration of RL training by up to 1.5$\times$, and saves the external resources by up to 71.2$\%$. This system has been deployed to support the training of the MiMo series models.
DyQ-VLA: Temporal-Dynamic-Aware Quantization for Embodied Vision-Language-Action Models
Mar 09, 2026Vision-Language-Action (VLA) models are dominant in embodied intelligence but are constrained by inference overheads. While model quantization alleviates these bottlenecks for edge deployment, static quantization approaches remain suboptimal for VLAs due to two critical challenges: (1) Temporal-dynamic sensitivity, where fixed precision wastes resources by ignoring stage-varying error tolerances; and (2) Real-time allocation, where identifying real-time sensitivity to guide bit allocation remains unsolved. To address these challenges, we propose DyQ-VLA, a dynamic quantization framework for VLAs. Specifically, a sensitivity-aware switching strategy leverages real-time kinematic proxies to trigger the bit-width switch, while a kinematic-guided module dynamically allocates the optimal bit-width. Experiments show that DyQ-VLA requires only 30.9% of the original memory footprint while maintaining 99.5% of its original performance, achieving 1.49x simulation and up to 1.43x real-world speedups.
WarmServe: Enabling One-for-Many GPU Prewarming for Multi-LLM Serving
Dec 10, 2025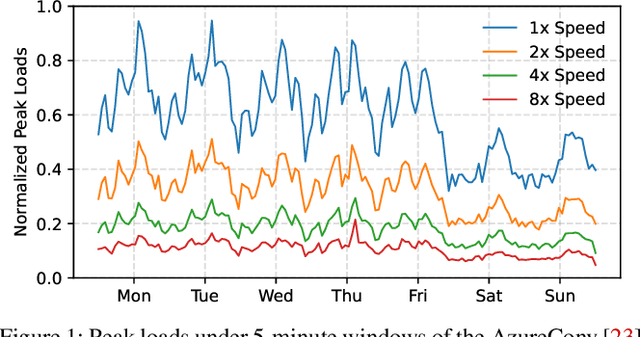
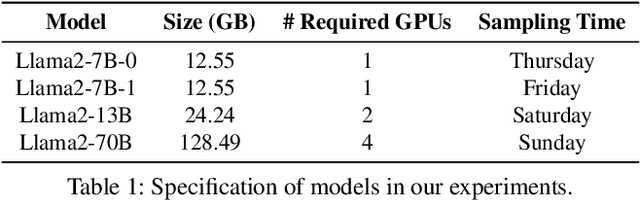
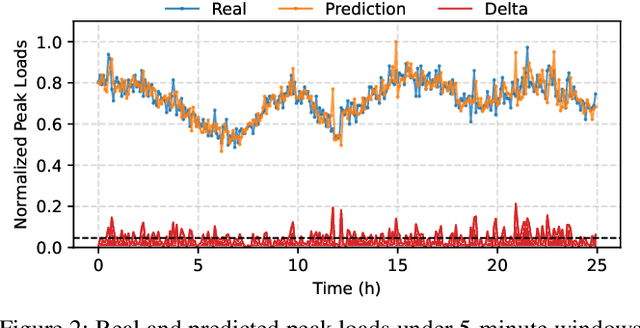
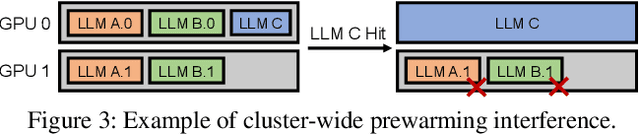
Deploying multiple models within shared GPU clusters is promising for improving resource efficiency in large language model (LLM) serving. Existing multi-LLM serving systems optimize GPU utilization at the cost of worse inference performance, especially time-to-first-token (TTFT). We identify the root cause of such compromise as their unawareness of future workload characteristics. In contrast, recent analysis on real-world traces has shown the high periodicity and long-term predictability of LLM serving workloads. We propose universal GPU workers to enable one-for-many GPU prewarming that loads models with knowledge of future workloads. Based on universal GPU workers, we design and build WarmServe, a multi-LLM serving system that (1) mitigates cluster-wide prewarming interference by adopting an evict-aware model placement strategy, (2) prepares universal GPU workers in advance by proactive prewarming, and (3) manages GPU memory with a zero-overhead memory switching mechanism. Evaluation under real-world datasets shows that WarmServe improves TTFT by up to 50.8$\times$ compared to the state-of-the-art autoscaling-based system, while being capable of serving up to 2.5$\times$ more requests compared to the GPU-sharing system.
TokenLake: A Unified Segment-level Prefix Cache Pool for Fine-grained Elastic Long-Context LLM Serving
Aug 24, 2025



Prefix caching is crucial to accelerate multi-turn interactions and requests with shared prefixes. At the cluster level, existing prefix caching systems are tightly coupled with request scheduling to optimize cache efficiency and computation performance together, leading to load imbalance, data redundancy, and memory fragmentation of caching systems across instances. To address these issues, memory pooling is promising to shield the scheduler from the underlying cache management so that it can focus on the computation optimization. However, because existing prefix caching systems only transfer increasingly longer prefix caches between instances, they cannot achieve low-latency memory pooling. To address these problems, we propose a unified segment-level prefix cache pool, TokenLake. It uses a declarative cache interface to expose requests' query tensors, prefix caches, and cache-aware operations to TokenLake for efficient pooling. Powered by this abstraction, TokenLake can manage prefix cache at the segment level with a heavy-hitter-aware load balancing algorithm to achieve better cache load balance, deduplication, and defragmentation. TokenLake also transparently minimizes the communication volume of query tensors and new caches. Based on TokenLake, the scheduler can schedule requests elastically by using existing techniques without considering prefix cache management. Evaluations on real-world workloads show that TokenLake can improve throughput by up to 2.6$\times$ and 2.0$\times$ and boost hit rate by 2.0$\times$ and 2.1$\times$, compared to state-of-the-art cache-aware routing and cache-centric PD-disaggregation solutions, respectively.
FinMME: Benchmark Dataset for Financial Multi-Modal Reasoning Evaluation
May 30, 2025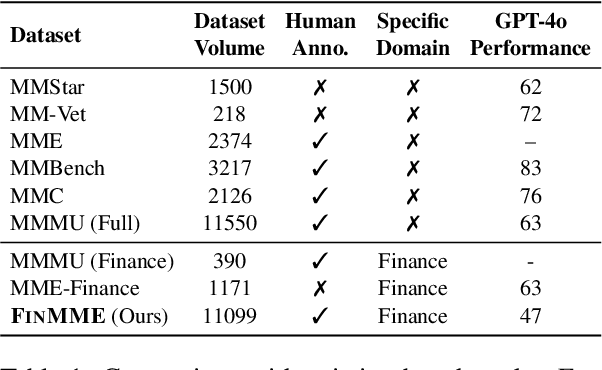
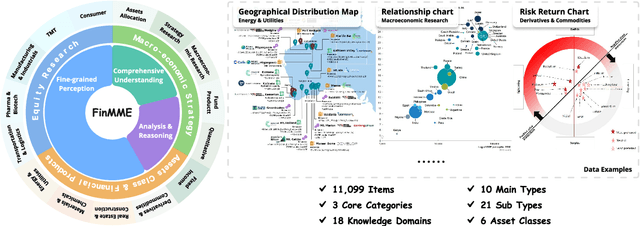
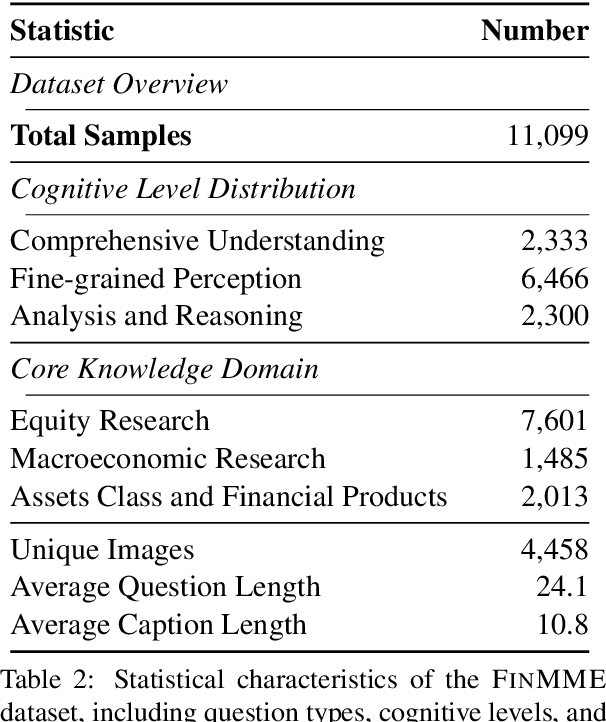
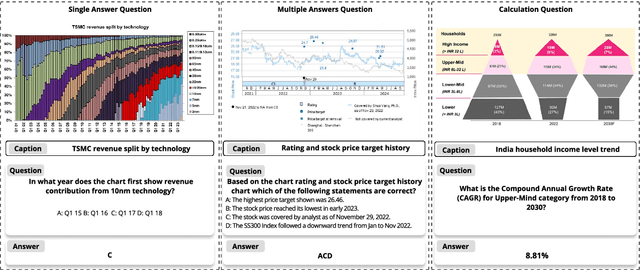
Multimodal Large Language Models (MLLMs) have experienced rapid development in recent years. However, in the financial domain, there is a notable lack of effective and specialized multimodal evaluation datasets. To advance the development of MLLMs in the finance domain, we introduce FinMME, encompassing more than 11,000 high-quality financial research samples across 18 financial domains and 6 asset classes, featuring 10 major chart types and 21 subtypes. We ensure data quality through 20 annotators and carefully designed validation mechanisms. Additionally, we develop FinScore, an evaluation system incorporating hallucination penalties and multi-dimensional capability assessment to provide an unbiased evaluation. Extensive experimental results demonstrate that even state-of-the-art models like GPT-4o exhibit unsatisfactory performance on FinMME, highlighting its challenging nature. The benchmark exhibits high robustness with prediction variations under different prompts remaining below 1%, demonstrating superior reliability compared to existing datasets. Our dataset and evaluation protocol are available at https://huggingface.co/datasets/luojunyu/FinMME and https://github.com/luo-junyu/FinMME.
MegaScale-MoE: Large-Scale Communication-Efficient Training of Mixture-of-Experts Models in Production
May 19, 2025We present MegaScale-MoE, a production system tailored for the efficient training of large-scale mixture-of-experts (MoE) models. MoE emerges as a promising architecture to scale large language models (LLMs) to unprecedented sizes, thereby enhancing model performance. However, existing MoE training systems experience a degradation in training efficiency, exacerbated by the escalating scale of MoE models and the continuous evolution of hardware. Recognizing the pivotal role of efficient communication in enhancing MoE training, MegaScale-MoE customizes communication-efficient parallelism strategies for attention and FFNs in each MoE layer and adopts a holistic approach to overlap communication with computation at both inter- and intra-operator levels. Additionally, MegaScale-MoE applies communication compression with adjusted communication patterns to lower precision, further improving training efficiency. When training a 352B MoE model on 1,440 NVIDIA Hopper GPUs, MegaScale-MoE achieves a training throughput of 1.41M tokens/s, improving the efficiency by 1.88$\times$ compared to Megatron-LM. We share our operational experience in accelerating MoE training and hope that by offering our insights in system design, this work will motivate future research in MoE systems.
MegaScale-Infer: Serving Mixture-of-Experts at Scale with Disaggregated Expert Parallelism
Apr 03, 2025



Mixture-of-Experts (MoE) showcases tremendous potential to scale large language models (LLMs) with enhanced performance and reduced computational complexity. However, its sparsely activated architecture shifts feed-forward networks (FFNs) from being compute-intensive to memory-intensive during inference, leading to substantially lower GPU utilization and increased operational costs. We present MegaScale-Infer, an efficient and cost-effective system for serving large-scale MoE models. MegaScale-Infer disaggregates attention and FFN modules within each model layer, enabling independent scaling, tailored parallelism strategies, and heterogeneous deployment for both modules. To fully exploit disaggregation in the presence of MoE's sparsity, MegaScale-Infer introduces ping-pong pipeline parallelism, which partitions a request batch into micro-batches and shuttles them between attention and FFNs for inference. Combined with distinct model parallelism for each module, MegaScale-Infer effectively hides communication overhead and maximizes GPU utilization. To adapt to disaggregated attention and FFN modules and minimize data transmission overhead (e.g., token dispatch), MegaScale-Infer provides a high-performance M2N communication library that eliminates unnecessary GPU-to-CPU data copies, group initialization overhead, and GPU synchronization. Experimental results indicate that MegaScale-Infer achieves up to 1.90x higher per-GPU throughput than state-of-the-art solutions.
Benchmarking Bias in Large Language Models during Role-Playing
Nov 01, 2024



Large Language Models (LLMs) have become foundational in modern language-driven applications, profoundly influencing daily life. A critical technique in leveraging their potential is role-playing, where LLMs simulate diverse roles to enhance their real-world utility. However, while research has highlighted the presence of social biases in LLM outputs, it remains unclear whether and to what extent these biases emerge during role-playing scenarios. In this paper, we introduce BiasLens, a fairness testing framework designed to systematically expose biases in LLMs during role-playing. Our approach uses LLMs to generate 550 social roles across a comprehensive set of 11 demographic attributes, producing 33,000 role-specific questions targeting various forms of bias. These questions, spanning Yes/No, multiple-choice, and open-ended formats, are designed to prompt LLMs to adopt specific roles and respond accordingly. We employ a combination of rule-based and LLM-based strategies to identify biased responses, rigorously validated through human evaluation. Using the generated questions as the benchmark, we conduct extensive evaluations of six advanced LLMs released by OpenAI, Mistral AI, Meta, Alibaba, and DeepSeek. Our benchmark reveals 72,716 biased responses across the studied LLMs, with individual models yielding between 7,754 and 16,963 biased responses, underscoring the prevalence of bias in role-playing contexts. To support future research, we have publicly released the benchmark, along with all scripts and experimental results.
Empowering 1000 tokens/second on-device LLM prefilling with mllm-NPU
Jul 08, 2024



On-device large language models (LLMs) are catalyzing novel mobile applications such as UI task automation and personalized email auto-reply, without giving away users' private data. However, on-device LLMs still suffer from unacceptably long inference latency, especially the time to first token (prefill stage) due to the need of long context for accurate, personalized content generation, as well as the lack of parallel computing capacity of mobile CPU/GPU. To enable practical on-device LLM, we present mllm-NPU, the first-of-its-kind LLM inference system that efficiently leverages on-device Neural Processing Unit (NPU) offloading. Essentially, mllm-NPU is an algorithm-system co-design that tackles a few semantic gaps between the LLM architecture and contemporary NPU design. Specifically, it re-constructs the prompt and model in three levels: (1) At prompt level, it divides variable-length prompts into multiple fixed-sized chunks while maintaining data dependencies; (2) At tensor level, it identifies and extracts significant outliers to run on the CPU/GPU in parallel with minimal overhead; (3) At block level, it schedules Transformer blocks in an out-of-order manner to the CPU/GPU and NPU based on their hardware affinity and sensitivity to accuracy. Compared to competitive baselines, mllm-NPU achieves 22.4x faster prefill speed and 30.7x energy savings on average, and up to 32.8x speedup in an end-to-end real-world application. For the first time, mllm-NPU achieves more than 1,000 tokens/sec prefilling for a billion-sized model (Qwen1.5-1.8B), paving the way towards practical on-device LLM.