 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalized Benchmarking: Evaluating LLMs by Individual Preferences
Apr 21, 2026With the rise in capabilities of large language models (LLMs) and their deployment in real-world tasks, evaluating LLM alignment with human preferences has become an important challenge. Current benchmarks average preferences across all users to compute aggregate ratings, overlooking individual user preferences when establishing model rankings. Since users have varying preferences in different contexts, we call for personalized LLM benchmarks that rank models according to individual needs. We compute personalized model rankings using ELO ratings and Bradley-Terry coefficients for 115 active Chatbot Arena users and analyze how user query characteristics (topics and writing style) relate to LLM ranking variations. We demonstrate that individual rankings of LLM models diverge dramatically from aggregate LLM rankings, with Bradley-Terry correlations averaging only $ρ= 0.04$ (57\% of users show near-zero or negative correlation) and ELO ratings showing moderate correlation ($ρ= 0.43$). Through topic modeling and style analysis, we find users exhibit substantial heterogeneity in topical interests and communication styles, influencing their model preferences. We further show that a compact combination of topic and style features provides a useful feature space for predicting user-specific model rankings. Our results provide strong quantitative evidence that aggregate benchmarks fail to capture individual preferences for most users, and highlight the importance of developing personalized benchmarks that rank LLM models according to individual user preferences.
HyPerAlign: Hypotheses-driven Personalized Alignment
Apr 29, 2025



Alignment algorithms are widely used to align large language models (LLMs) to human users based on preference annotations that reflect their intended real-world use cases. Typically these (often divergent) preferences are aggregated over a diverse set of users, resulting in fine-tuned models that are aligned to the ``average-user'' preference. Nevertheless, current models are used by individual users in very specific contexts and situations, emphasizing the need for user-dependent preference control. In this work we address the problem of personalizing LLM outputs to their users, aiming to generate customized responses tailored to individual users, instead of generic outputs that emulate the collective voices of diverse populations. We propose a novel interpretable and sample-efficient hypotheses-driven personalization approach (HyPerAlign) where given few-shot examples written by a particular user, we first infer hypotheses about their communication strategies, personality and writing style, then prompt LLM models with these hypotheses and user specific attributes to generate customized outputs. We conduct experiments on two different personalization tasks, authorship attribution and deliberative alignment, with datasets from diverse domains (news articles, blog posts, emails, jailbreaking benchmarks), and demonstrate the superiority of hypotheses-driven personalization approach when compared to preference-based fine-tuning methods. For deliberative alignment, the helpfulness of LLM models is improved by up to $70\%$ on average. For authorship attribution, results indicate consistently high win-rates (commonly $>90\%$) against state-of-the-art preference fine-tuning approaches for LLM personalization across diverse user profiles and LLM models. Overall, our approach represents an interpretable and sample-efficient strategy for the personalization of LLM models to individual users.
Evaluating the Goal-Directedness of Large Language Models
Apr 16, 2025



To what extent do LLMs use their capabilities towards their given goal? We take this as a measure of their goal-directedness. We evaluate goal-directedness on tasks that require information gathering, cognitive effort, and plan execution, where we use subtasks to infer each model's relevant capabilities. Our evaluations of LLMs from Google DeepMind, OpenAI, and Anthropic show that goal-directedness is relatively consistent across tasks, differs from task performance, and is only moderately sensitive to motivational prompts. Notably, most models are not fully goal-directed. We hope our goal-directedness evaluations will enable better monitoring of LLM progress, and enable more deliberate design choices of agentic properties in LLMs.
RATE: Score Reward Models with Imperfect Rewrites of Rewrites
Oct 15, 2024



This paper concerns the evaluation of reward models used in language modeling. A reward model is a function that takes a prompt and a response and assigns a score indicating how good that response is for the prompt. A key challenge is that reward models are usually imperfect proxies for actual preferences. For example, we may worry that a model trained to reward helpfulness learns to instead prefer longer responses. In this paper, we develop an evaluation method, RATE (Rewrite-based Attribute Treatment Estimators), that allows us to measure the causal effect of a given attribute of a response (e.g., length) on the reward assigned to that response. The core idea is to use large language models to rewrite responses to produce imperfect counterfactuals, and to adjust for rewriting error by rewriting twice. We show that the RATE estimator is consistent under reasonable assumptions. We demonstrate the effectiveness of RATE on synthetic and real-world data, showing that it can accurately estimate the effect of a given attribute on the reward model.
GEMv2: Multilingual NLG Benchmarking in a Single Line of Code
Jun 24, 2022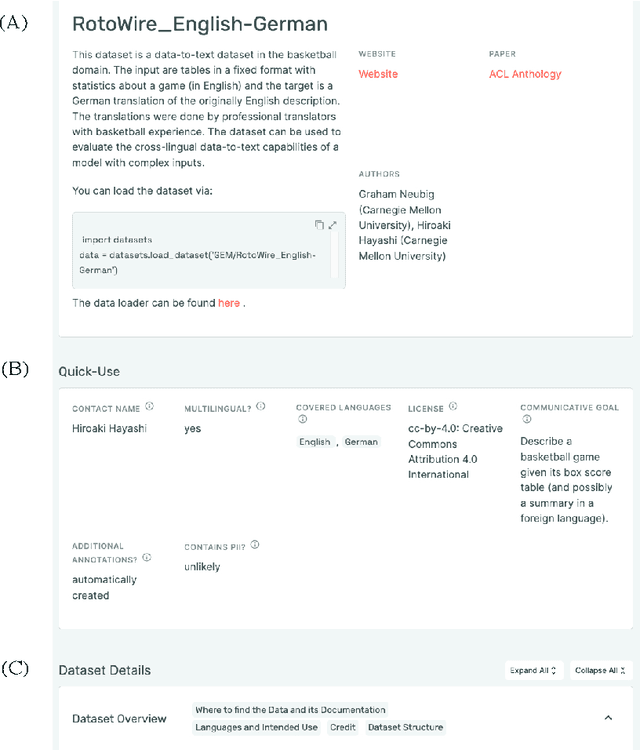

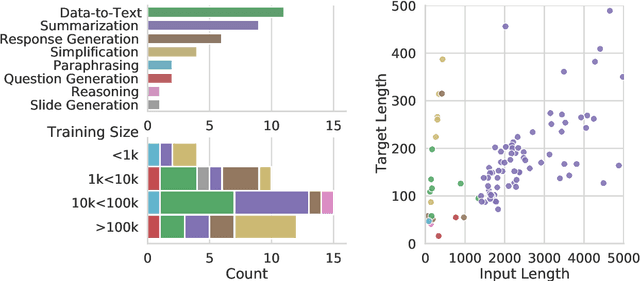

Evaluation in machine learning is usually informed by past choices, for example which datasets or metrics to use. This standardization enables the comparison on equal footing using leaderboards, but the evaluation choices become sub-optimal as better alternatives arise. This problem is especially pertinent in natural language generation which requires ever-improving suites of datasets, metrics, and human evaluation to make definitive claims. To make following best model evaluation practices easier, we introduce GEMv2. The new version of the Generation, Evaluation, and Metrics Benchmark introduces a modular infrastructure for dataset, model, and metric developers to benefit from each others work. GEMv2 supports 40 documented datasets in 51 languages. Models for all datasets can be evaluated online and our interactive data card creation and rendering tools make it easier to add new datasets to the living benchmark.
Why is constrained neural language generation particularly challenging?
Jun 11, 2022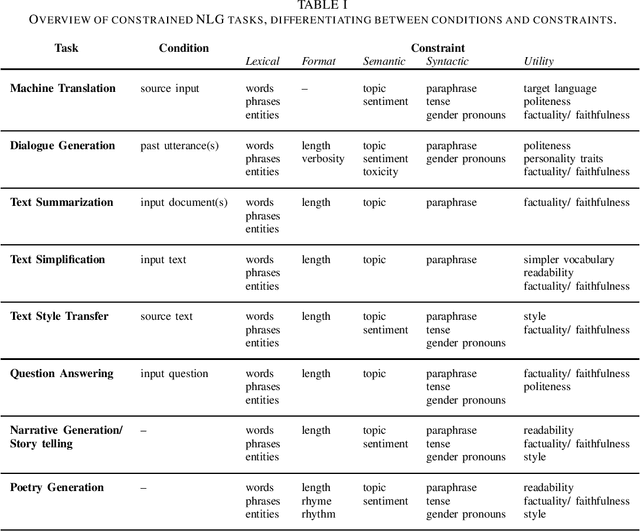
Recent advances in deep neural language models combined with the capacity of large scale datasets have accelerated the development of natural language generation systems that produce fluent and coherent texts (to various degrees of success) in a multitude of tasks and application contexts. However, controlling the output of these models for desired user and task needs is still an open challenge. This is crucial not only to customizing the content and style of the generated language, but also to their safe and reliable deployment in the real world. We present an extensive survey on the emerging topic of constrained neural language generation in which we formally define and categorize the problems of natural language generation by distinguishing between conditions and constraints (the latter being testable conditions on the output text instead of the input), present constrained text generation tasks, and review existing methods and evaluation metrics for constrained text generation. Our aim is to highlight recent progress and trends in this emerging field, informing on the most promising directions and limitations towards advancing the state-of-the-art of constrained neural language generation research.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
The GEM Benchmark: Natural Language Generation, its Evaluation and Metrics
Feb 03, 2021



We introduce GEM, a living benchmark for natural language Generation (NLG), its Evaluation, and Metrics. Measuring progress in NLG relies on a constantly evolving ecosystem of automated metrics, datasets, and human evaluation standards. However, due to this moving target, new models often still evaluate on divergent anglo-centric corpora with well-established, but flawed, metrics. This disconnect makes it challenging to identify the limitations of current models and opportunities for progress. Addressing this limitation, GEM provides an environment in which models can easily be applied to a wide set of corpora and evaluation strategies can be tested. Regular updates to the benchmark will help NLG research become more multilingual and evolve the challenge alongside models. This paper serves as the description of the initial release for which we are organizing a shared task at our ACL 2021 Workshop and to which we invite the entire NLG community to participate.
An Empirical Study on Explainable Prediction of Text Complexity: Preliminaries for Text Simplification
Jul 31, 2020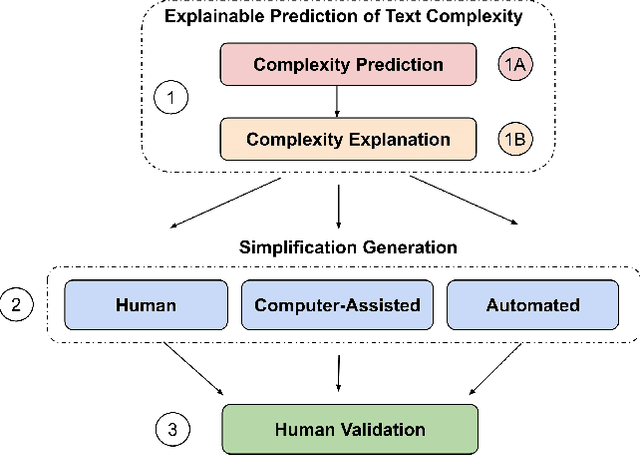
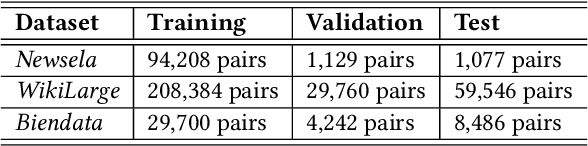

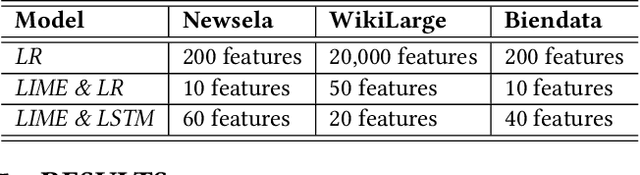
Text simplification is concerned with reducing the language complexity and improving the readability of professional content so that the text is accessible to readers at different ages and educational levels. As a promising practice to improve the fairness and transparency of text information systems, the notion of text simplification has been mixed in existing literature, ranging all the way through assessing the complexity of single words to automatically generating simplified documents. We show that the general problem of text simplification can be formally decomposed into a compact pipeline of tasks to ensure the transparency and explanability of the process. In this paper, we present a systematic analysis of the first two steps in this pipeline: 1) predicting the complexity of a given piece of text, and 2) identifying complex components from the text considered to be complex. We show that these two tasks can be solved separately, using either lexical approaches or the state-of-the-art deep learning methods, or they can be solved jointly through an end-to-end, explainable machine learning predictor. We propose formal evaluation metrics for both tasks, through which we are able to compare the performance of the candidate approaches using multiple datasets from a diversity of domains.
Neural Language Generation: Formulation, Methods, and Evaluation
Jul 31, 2020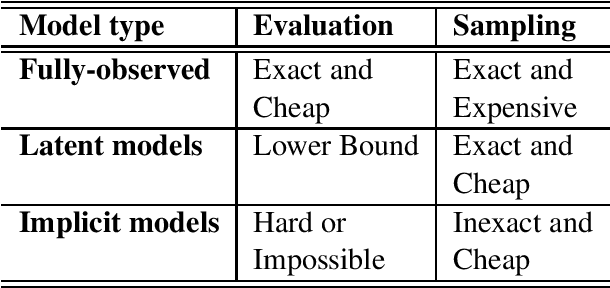

Recent advances in neural network-based generative modeling have reignited the hopes in having computer systems capable of seamlessly conversing with humans and able to understand natural language. Neural architectures have been employed to generate text excerpts to various degrees of success, in a multitude of contexts and tasks that fulfil various user needs. Notably, high capacity deep learning models trained on large scale datasets demonstrate unparalleled abilities to learn patterns in the data even in the lack of explicit supervision signals, opening up a plethora of new possibilities regarding producing realistic and coherent texts. While the field of natural language generation is evolving rapidly, there are still many open challenges to address. In this survey we formally define and categorize the problem of natural language generation. We review particular application tasks that are instantiations of these general formulations, in which generating natural language is of practical importance. Next we include a comprehensive outline of methods and neural architectures employed for generating diverse texts. Nevertheless, there is no standard way to assess the quality of text produced by these generative models, which constitutes a serious bottleneck towards the progress of the field. To this end, we also review current approaches to evaluating natural language generation systems. We hope this survey will provide an informative overview of formulations, methods, and assessments of neural natural language generation.