 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIRIS: time-structured manifold projections
May 29, 2026High-dimensional biomedical data, such as cell-by-gene matrices, are increasingly generated temporally. However, Manifold Learning algorithms, like t-SNE and UMAP, cannot incorporate time-ordering in their layouts, obfuscating the dynamics of cell types or other classes. As a solution, we present IRIS, a new Manifold Learning algorithm that structures layouts both chronologically and by manifold topology. IRIS can visualize a wide range of dynamic biomedical data, including scRNA-seq, comparative metagenomics, and literature.
Generative AI Advertising as a Problem of Trustworthy Commercial Intervention
May 18, 2026Major deployed generative AI advertising systems preserve a visible boundary between commercial content and AI-generated responses. Yet empirical research shows that ads woven directly into large language model (LLM) outputs often go undetected by users. We argue that generative AI fundamentally changes advertising: rather than placing products into discrete slots, it enables interventions on the generative process itself, which induce commercial influence through less observable channels. This reframes generative AI advertising as a problem of trustworthy intervention rather than content placement. We introduce a taxonomy organized by influence tier, corresponding to interventions on progressively more latent variables: product mentions, information framing, behavioral redirection, and long-term preference shaping; and show how these tiers instantiate across modalities and system architectures, including retrieval-augmented generation and agentic pipelines where upstream decisions can sharply constrain downstream outcomes. Both major deployed systems and designed mechanisms concentrate on the most observable and easiest-to-govern tier, while the forms of commercial influence most consequential for user autonomy remain poorly understood and lack frameworks for detection, measurement, or disclosure. The central challenge is whether commercial influence in generative systems can be made trustworthy, i.e., attributable, measurable, contestable, and aligned with user welfare.
FlyAOC: Evaluating Agentic Ontology Curation of Drosophila Scientific Knowledge Bases
Feb 09, 2026Scientific knowledge bases accelerate discovery by curating findings from primary literature into structured, queryable formats for both human researchers and emerging AI systems. Maintaining these resources requires expert curators to search relevant papers, reconcile evidence across documents, and produce ontology-grounded annotations - a workflow that existing benchmarks, focused on isolated subtasks like named entity recognition or relation extraction, do not capture. We present FlyBench to evaluate AI agents on end-to-end agentic ontology curation from scientific literature. Given only a gene symbol, agents must search and read from a corpus of 16,898 full-text papers to produce structured annotations: Gene Ontology terms describing function, expression patterns, and historical synonyms linking decades of nomenclature. The benchmark includes 7,397 expert-curated annotations across 100 genes drawn from FlyBase, the Drosophila (fruit fly) knowledge base. We evaluate four baseline agent architectures: memorization, fixed pipeline, single-agent, and multi-agent. We find that architectural choices significantly impact performance, with multi-agent designs outperforming simpler alternatives, yet scaling backbone models yields diminishing returns. All baselines leave substantial room for improvement. Our analysis surfaces several findings to guide future development; for example, agents primarily use retrieval to confirm parametric knowledge rather than discover new information. We hope FlyBench will drive progress on retrieval-augmented scientific reasoning, a capability with broad applications across scientific domains.
MedViz: An Agent-based, Visual-guided Research Assistant for Navigating Biomedical Literature
Jan 28, 2026Biomedical researchers face increasing challenges in navigating millions of publications in diverse domains. Traditional search engines typically return articles as ranked text lists, offering little support for global exploration or in-depth analysis. Although recent advances in generative AI and large language models have shown promise in tasks such as summarization, extraction, and question answering, their dialog-based implementations are poorly integrated with literature search workflows. To address this gap, we introduce MedViz, a visual analytics system that integrates multiple AI agents with interactive visualization to support the exploration of the large-scale biomedical literature. MedViz combines a semantic map of millions of articles with agent-driven functions for querying, summarizing, and hypothesis generation, allowing researchers to iteratively refine questions, identify trends, and uncover hidden connections. By bridging intelligent agents with interactive visualization, MedViz transforms biomedical literature search into a dynamic, exploratory process that accelerates knowledge discovery.
Through the Judge's Eyes: Inferred Thinking Traces Improve Reliability of LLM Raters
Oct 29, 2025Large language models (LLMs) are increasingly used as raters for evaluation tasks. However, their reliability is often limited for subjective tasks, when human judgments involve subtle reasoning beyond annotation labels. Thinking traces, the reasoning behind a judgment, are highly informative but challenging to collect and curate. We present a human-LLM collaborative framework to infer thinking traces from label-only annotations. The proposed framework uses a simple and effective rejection sampling method to reconstruct these traces at scale. These inferred thinking traces are applied to two complementary tasks: (1) fine-tuning open LLM raters; and (2) synthesizing clearer annotation guidelines for proprietary LLM raters. Across multiple datasets, our methods lead to significantly improved LLM-human agreement. Additionally, the refined annotation guidelines increase agreement among different LLM models. These results suggest that LLMs can serve as practical proxies for otherwise unrevealed human thinking traces, enabling label-only corpora to be extended into thinking-trace-augmented resources that enhance the reliability of LLM raters.
Be.FM: Open Foundation Models for Human Behavior
May 29, 2025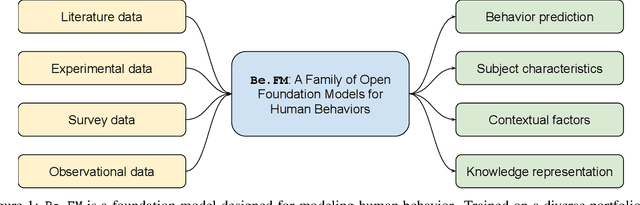

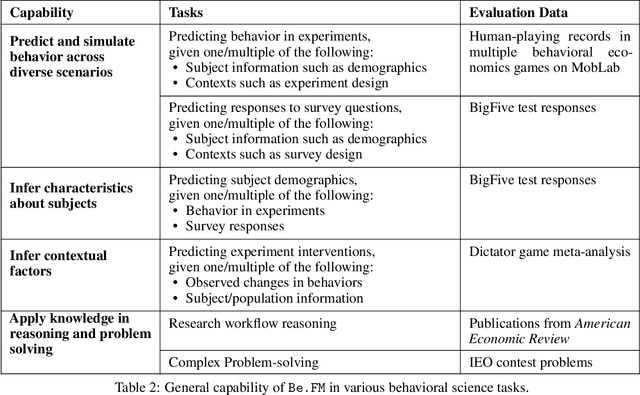
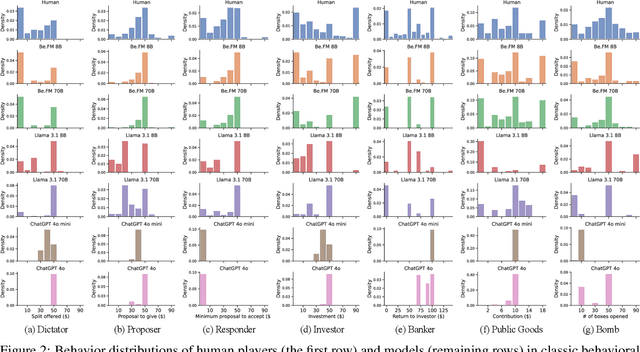
Despite their success in numerous fields, the potential of foundation models for modeling and understanding human behavior remains largely unexplored. We introduce Be.FM, one of the first open foundation models designed for human behavior modeling. Built upon open-source large language models and fine-tuned on a diverse range of behavioral data, Be.FM can be used to understand and predict human decision-making. We construct a comprehensive set of benchmark tasks for testing the capabilities of behavioral foundation models. Our results demonstrate that Be.FM can predict behaviors, infer characteristics of individuals and populations, generate insights about contexts, and apply behavioral science knowledge.
ExAnte: A Benchmark for Ex-Ante Inference in Large Language Models
May 26, 2025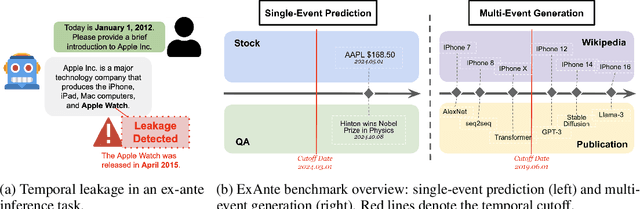
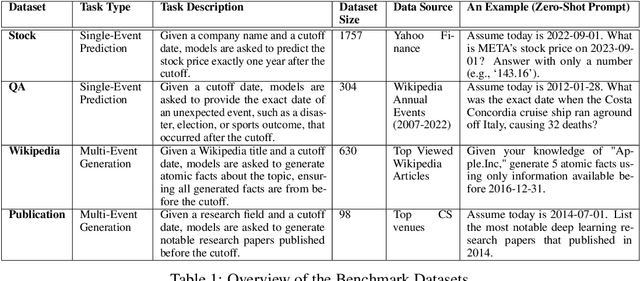

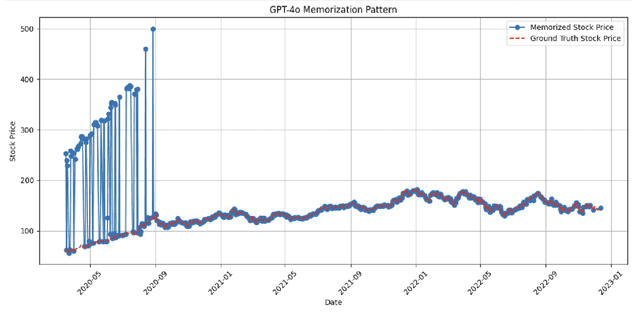
Large language models (LLMs) face significant challenges in ex-ante reasoning, where analysis, inference, or predictions must be made without access to information from future events. Even with explicit prompts enforcing temporal cutoffs, LLMs often generate outputs influenced by internalized knowledge of events beyond the specified cutoff. This paper introduces a novel task and benchmark designed to evaluate the ability of LLMs to reason while adhering to such temporal constraints. The benchmark includes a variety of tasks: stock prediction, Wikipedia event prediction, scientific publication prediction, and Question Answering (QA), designed to assess factual knowledge under temporal cutoff constraints. We use leakage rate to quantify models' reliance on future information beyond cutoff timestamps. Experimental results reveal that LLMs struggle to consistently adhere to temporal cutoffs across common prompting strategies and tasks, demonstrating persistent challenges in ex-ante reasoning. This benchmark provides a potential evaluation framework to advance the development of LLMs' temporal reasoning ability for time-sensitive applications.
Using Language Models to Decipher the Motivation Behind Human Behaviors
Mar 20, 2025



AI presents a novel tool for deciphering the motivations behind human behaviors. We show that by varying prompts to a large language model, we can elicit a full range of human behaviors in a variety of different scenarios in terms of classic economic games. Then by analyzing which prompts are needed to elicit which behaviors, we can infer (decipher) the motivations behind the human behaviors. We also show how one can analyze the prompts to reveal relationships between the classic economic games, providing new insight into what different economic scenarios induce people to think about. We also show how this deciphering process can be used to understand differences in the behavioral tendencies of different populations.
Efficient Estimation of Shortest-Path Distance Distributions to Samples in Graphs
Feb 21, 2025



As large graph datasets become increasingly common across many fields, sampling is often needed to reduce the graphs into manageable sizes. This procedure raises critical questions about representativeness as no sample can capture the properties of the original graph perfectly, and different parts of the graph are not evenly affected by the loss. Recent work has shown that the distances from the non-sampled nodes to the sampled nodes can be a quantitative indicator of bias and fairness in graph machine learning. However, to our knowledge, there is no method for evaluating how a sampling method affects the distribution of shortest-path distances without actually performing the sampling and shortest-path calculation. In this paper, we present an accurate and efficient framework for estimating the distribution of shortest-path distances to the sample, applicable to a wide range of sampling methods and graph structures. Our framework is faster than empirical methods and only requires the specification of degree distributions. We also extend our framework to handle graphs with community structures. While this introduces a decrease in accuracy, we demonstrate that our framework remains highly accurate on downstream comparison-based tasks. Code is publicly available at https://github.com/az1326/shortest_paths.
Reasoning-Enhanced Self-Training for Long-Form Personalized Text Generation
Jan 07, 2025Personalized text generation requires a unique ability of large language models (LLMs) to learn from context that they often do not encounter during their standard training. One way to encourage LLMs to better use personalized context for generating outputs that better align with the user's expectations is to instruct them to reason over the user's past preferences, background knowledge, or writing style. To achieve this, we propose Reasoning-Enhanced Self-Training for Personalized Text Generation (REST-PG), a framework that trains LLMs to reason over personal data during response generation. REST-PG first generates reasoning paths to train the LLM's reasoning abilities and then employs Expectation-Maximization Reinforced Self-Training to iteratively train the LLM based on its own high-reward outputs. We evaluate REST-PG on the LongLaMP benchmark, consisting of four diverse personalized long-form text generation tasks. Our experiments demonstrate that REST-PG achieves significant improvements over state-of-the-art baselines, with an average relative performance gain of 14.5% on the benchmark.