 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Conversational Medical AI with Eyes, Ears and a Voice
May 10, 2026The practice of medicine relies not only upon skillful dialogue but also on the nuanced exchange and interpretation of rich auditory and visual cues between doctors and patients. Building on the low-latency voice and video processing capabilities of Gemini, we introduce AI co-clinician, a first-of-its-kind conversational AI system utilizing continuous streams of audio-visual data from live patient conversations to inform real-time clinical decisions. Its dual-agent architecture balances deep clinical reasoning with the low latency required for natural dialogue. To assess this system, we implemented a video-based interface emulating telemedicine consultations. We crafted 20 standardized outpatient scenarios requiring proactive real-time auditory and visual reasoning and designed "TelePACES" evaluation criteria alongside case-specific rubrics. In a randomized, interface-blinded, crossover simulation study (n = 120 encounters) with 10 internal medicine residents as patient actors, we compared AI co-clinician with primary care physicians (PCPs), GPT-Realtime, and a baseline agent. AI co-clinician approached PCPs in key TelePACES dimensions, including management plans and differential diagnosis, while significantly outperforming GPT-Realtime across all general criteria. While our agent demonstrated parity with PCPs in case-specific triage measures, physicians maintained superior overall performance in case-specific assessments. Although AI co-clinician marks a significant advance in real-time telemedical AI, gaps remain in physical examination and disease-specific reasoning. Our work shows that text-only approaches fail to capture the true challenges of medical consultation and suggests that high-stakes real-time diagnostic AI is most safely advanced in collaborative, triadic models where AI can be a supportive co-clinician for doctors and patients.
Geometric-Averaged Preference Optimization for Soft Preference Labels
Sep 10, 2024Many algorithms for aligning LLMs with human preferences assume that human preferences are binary and deterministic. However, it is reasonable to think that they can vary with different individuals, and thus should be distributional to reflect the fine-grained relationship between the responses. In this work, we introduce the distributional soft preference labels and improve Direct Preference Optimization (DPO) with a weighted geometric average of the LLM output likelihood in the loss function. In doing so, the scale of learning loss is adjusted based on the soft labels, and the loss with equally preferred responses would be close to zero. This simple modification can be easily applied to any DPO family and helps the models escape from the over-optimization and objective mismatch prior works suffer from. In our experiments, we simulate the soft preference labels with AI feedback from LLMs and demonstrate that geometric averaging consistently improves performance on standard benchmarks for alignment research. In particular, we observe more preferable responses than binary labels and significant improvements with data where modestly-confident labels are in the majority.
DreamSparse: Escaping from Plato's Cave with 2D Frozen Diffusion Model Given Sparse Views
Jun 16, 2023



Synthesizing novel view images from a few views is a challenging but practical problem. Existing methods often struggle with producing high-quality results or necessitate per-object optimization in such few-view settings due to the insufficient information provided. In this work, we explore leveraging the strong 2D priors in pre-trained diffusion models for synthesizing novel view images. 2D diffusion models, nevertheless, lack 3D awareness, leading to distorted image synthesis and compromising the identity. To address these problems, we propose DreamSparse, a framework that enables the frozen pre-trained diffusion model to generate geometry and identity-consistent novel view image. Specifically, DreamSparse incorporates a geometry module designed to capture 3D features from sparse views as a 3D prior. Subsequently, a spatial guidance model is introduced to convert these 3D feature maps into spatial information for the generative process. This information is then used to guide the pre-trained diffusion model, enabling it to generate geometrically consistent images without tuning it. Leveraging the strong image priors in the pre-trained diffusion models, DreamSparse is capable of synthesizing high-quality novel views for both object and scene-level images and generalising to open-set images. Experimental results demonstrate that our framework can effectively synthesize novel view images from sparse views and outperforms baselines in both trained and open-set category images. More results can be found on our project page: https://sites.google.com/view/dreamsparse-webpage.
For SALE: State-Action Representation Learning for Deep Reinforcement Learning
Jun 04, 2023



In the field of reinforcement learning (RL), representation learning is a proven tool for complex image-based tasks, but is often overlooked for environments with low-level states, such as physical control problems. This paper introduces SALE, a novel approach for learning embeddings that model the nuanced interaction between state and action, enabling effective representation learning from low-level states. We extensively study the design space of these embeddings and highlight important design considerations. We integrate SALE and an adaptation of checkpoints for RL into TD3 to form the TD7 algorithm, which significantly outperforms existing continuous control algorithms. On OpenAI gym benchmark tasks, TD7 has an average performance gain of 276.7% and 50.7% over TD3 at 300k and 5M time steps, respectively, and works in both the online and offline settings.
Multimodal Web Navigation with Instruction-Finetuned Foundation Models
May 19, 2023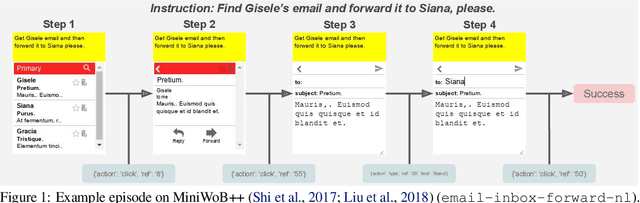



The progress of autonomous web navigation has been hindered by the dependence on billions of exploratory interactions via online reinforcement learning, and domain-specific model designs that make it difficult to leverage generalization from rich out-of-domain data. In this work, we study data-driven offline training for web agents with vision-language foundation models. We propose an instruction-following multimodal agent, WebGUM, that observes both webpage screenshots and HTML pages and outputs web navigation actions, such as click and type. WebGUM is trained by jointly finetuning an instruction-finetuned language model and a vision transformer on a large corpus of demonstrations. We empirically demonstrate this recipe improves the agent's ability of grounded visual perception, HTML comprehension and multi-step reasoning, outperforming prior works by a significant margin. On the MiniWoB benchmark, we improve over the previous best offline methods by more than 31.9%, being close to reaching online-finetuned SoTA. On the WebShop benchmark, our 3-billion-parameter model achieves superior performance to the existing SoTA, PaLM-540B. We also collect 347K high-quality demonstrations using our trained models, 38 times larger than prior work, and make them available to promote future research in this direction.
Learning a Universal Human Prior for Dexterous Manipulation from Human Preference
Apr 10, 2023



Generating human-like behavior on robots is a great challenge especially in dexterous manipulation tasks with robotic hands. Even in simulation with no sample constraints, scripting controllers is intractable due to high degrees of freedom, and manual reward engineering can also be hard and lead to non-realistic motions. Leveraging the recent progress on Reinforcement Learning from Human Feedback (RLHF), we propose a framework to learn a universal human prior using direct human preference feedback over videos, for efficiently tuning the RL policy on 20 dual-hand robot manipulation tasks in simulation, without a single human demonstration. One task-agnostic reward model is trained through iteratively generating diverse polices and collecting human preference over the trajectories; it is then applied for regularizing the behavior of polices in the fine-tuning stage. Our method empirically demonstrates more human-like behaviors on robot hands in diverse tasks including even unseen tasks, indicating its generalization capability.
Bi-Manual Block Assembly via Sim-to-Real Reinforcement Learning
Mar 27, 2023



Most successes in robotic manipulation have been restricted to single-arm gripper robots, whose low dexterity limits the range of solvable tasks to pick-and-place, inser-tion, and object rearrangement. More complex tasks such as assembly require dual and multi-arm platforms, but entail a suite of unique challenges such as bi-arm coordination and collision avoidance, robust grasping, and long-horizon planning. In this work we investigate the feasibility of training deep reinforcement learning (RL) policies in simulation and transferring them to the real world (Sim2Real) as a generic methodology for obtaining performant controllers for real-world bi-manual robotic manipulation tasks. As a testbed for bi-manual manipulation, we develop the U-Shape Magnetic BlockAssembly Task, wherein two robots with parallel grippers must connect 3 magnetic blocks to form a U-shape. Without manually-designed controller nor human demonstrations, we demonstrate that with careful Sim2Real considerations, our policies trained with RL in simulation enable two xArm6 robots to solve the U-shape assembly task with a success rate of above90% in simulation, and 50% on real hardware without any additional real-world fine-tuning. Through careful ablations,we highlight how each component of the system is critical for such simple and successful policy learning and transfer,including task specification, learning algorithm, direct joint-space control, behavior constraints, perception and actuation noises, action delays and action interpolation. Our results present a significant step forward for bi-arm capability on real hardware, and we hope our system can inspire future research on deep RL and Sim2Real transfer of bi-manualpolicies, drastically scaling up the capability of real-world robot manipulators.
Aligning Text-to-Image Models using Human Feedback
Feb 23, 2023



Deep generative models have shown impressive results in text-to-image synthesis. However, current text-to-image models often generate images that are inadequately aligned with text prompts. We propose a fine-tuning method for aligning such models using human feedback, comprising three stages. First, we collect human feedback assessing model output alignment from a set of diverse text prompts. We then use the human-labeled image-text dataset to train a reward function that predicts human feedback. Lastly, the text-to-image model is fine-tuned by maximizing reward-weighted likelihood to improve image-text alignment. Our method generates objects with specified colors, counts and backgrounds more accurately than the pre-trained model. We also analyze several design choices and find that careful investigations on such design choices are important in balancing the alignment-fidelity tradeoffs. Our results demonstrate the potential for learning from human feedback to significantly improve text-to-image models.
Collective Intelligence for Object Manipulation with Mobile Robots
Nov 28, 2022



While natural systems often present collective intelligence that allows them to self-organize and adapt to changes, the equivalent is missing in most artificial systems. We explore the possibility of such a system in the context of cooperative object manipulation using mobile robots. Although conventional works demonstrate potential solutions for the problem in restricted settings, they have computational and learning difficulties. More importantly, these systems do not possess the ability to adapt when facing environmental changes. In this work, we show that by distilling a planner derived from a gradient-based soft-body physics simulator into an attention-based neural network, our multi-robot manipulation system can achieve better performance than baselines. In addition, our system also generalizes to unseen configurations during training and is able to adapt toward task completions when external turbulence and environmental changes are applied.
A System for Morphology-Task Generalization via Unified Representation and Behavior Distillation
Nov 25, 2022



The rise of generalist large-scale models in natural language and vision has made us expect that a massive data-driven approach could achieve broader generalization in other domains such as continuous control. In this work, we explore a method for learning a single policy that manipulates various forms of agents to solve various tasks by distilling a large amount of proficient behavioral data. In order to align input-output (IO) interface among multiple tasks and diverse agent morphologies while preserving essential 3D geometric relations, we introduce morphology-task graph, which treats observations, actions and goals/task in a unified graph representation. We also develop MxT-Bench for fast large-scale behavior generation, which supports procedural generation of diverse morphology-task combinations with a minimal blueprint and hardware-accelerated simulator. Through efficient representation and architecture selection on MxT-Bench, we find out that a morphology-task graph representation coupled with Transformer architecture improves the multi-task performances compared to other baselines including recent discrete tokenization, and provides better prior knowledge for zero-shot transfer or sample efficiency in downstream multi-task imitation learning. Our work suggests large diverse offline datasets, unified IO representation, and policy representation and architecture selection through supervised learning form a promising approach for studying and advancing morphology-task generalization.