 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-Horizon Planning for Multi-Agent Robots in Partially Observable Environments
Jul 14, 2024



The ability of Language Models (LMs) to understand natural language makes them a powerful tool for parsing human instructions into task plans for autonomous robots. Unlike traditional planning methods that rely on domain-specific knowledge and handcrafted rules, LMs generalize from diverse data and adapt to various tasks with minimal tuning, acting as a compressed knowledge base. However, LMs in their standard form face challenges with long-horizon tasks, particularly in partially observable multi-agent settings. We propose an LM-based Long-Horizon Planner for Multi-Agent Robotics (LLaMAR), a cognitive architecture for planning that achieves state-of-the-art results in long-horizon tasks within partially observable environments. LLaMAR employs a plan-act-correct-verify framework, allowing self-correction from action execution feedback without relying on oracles or simulators. Additionally, we present MAP-THOR, a comprehensive test suite encompassing household tasks of varying complexity within the AI2-THOR environment. Experiments show that LLaMAR achieves a 30% higher success rate compared to other state-of-the-art LM-based multi-agent planners.
CHATATC: Large Language Model-Driven Conversational Agents for Supporting Strategic Air Traffic Flow Management
Feb 20, 2024Generative artificial intelligence (AI) and large language models (LLMs) have gained rapid popularity through publicly available tools such as ChatGPT. The adoption of LLMs for personal and professional use is fueled by the natural interactions between human users and computer applications such as ChatGPT, along with powerful summarization and text generation capabilities. Given the widespread use of such generative AI tools, in this work we investigate how these tools can be deployed in a non-safety critical, strategic traffic flow management setting. Specifically, we train an LLM, CHATATC, based on a large historical data set of Ground Delay Program (GDP) issuances, spanning 2000-2023 and consisting of over 80,000 GDP implementations, revisions, and cancellations. We test the query and response capabilities of CHATATC, documenting successes (e.g., providing correct GDP rates, durations, and reason) and shortcomings (e.g,. superlative questions). We also detail the design of a graphical user interface for future users to interact and collaborate with the CHATATC conversational agent.
Real-time Control of Electric Autonomous Mobility-on-Demand Systems via Graph Reinforcement Learning
Nov 09, 2023



Operators of Electric Autonomous Mobility-on-Demand (E-AMoD) fleets need to make several real-time decisions such as matching available cars to ride requests, rebalancing idle cars to areas of high demand, and charging vehicles to ensure sufficient range. While this problem can be posed as a linear program that optimizes flows over a space-charge-time graph, the size of the resulting optimization problem does not allow for real-time implementation in realistic settings. In this work, we present the E-AMoD control problem through the lens of reinforcement learning and propose a graph network-based framework to achieve drastically improved scalability and superior performance over heuristics. Specifically, we adopt a bi-level formulation where we (1) leverage a graph network-based RL agent to specify a desired next state in the space-charge graph, and (2) solve more tractable linear programs to best achieve the desired state while ensuring feasibility. Experiments using real-world data from San Francisco and New York City show that our approach achieves up to 89% of the profits of the theoretically-optimal solution while achieving more than a 100x speedup in computational time. Furthermore, our approach outperforms the best domain-specific heuristics with comparable runtimes, with an increase in profits by up to 3x. Finally, we highlight promising zero-shot transfer capabilities of our learned policy on tasks such as inter-city generalization and service area expansion, thus showing the utility, scalability, and flexibility of our framework.
Topical-Chat: Towards Knowledge-Grounded Open-Domain Conversations
Aug 23, 2023



Building socialbots that can have deep, engaging open-domain conversations with humans is one of the grand challenges of artificial intelligence (AI). To this end, bots need to be able to leverage world knowledge spanning several domains effectively when conversing with humans who have their own world knowledge. Existing knowledge-grounded conversation datasets are primarily stylized with explicit roles for conversation partners. These datasets also do not explore depth or breadth of topical coverage with transitions in conversations. We introduce Topical-Chat, a knowledge-grounded human-human conversation dataset where the underlying knowledge spans 8 broad topics and conversation partners don't have explicitly defined roles, to help further research in open-domain conversational AI. We also train several state-of-the-art encoder-decoder conversational models on Topical-Chat and perform automated and human evaluation for benchmarking.
Don't Stop Self-Supervision: Accent Adaptation of Speech Representations via Residual Adapters
Jul 02, 2023



Speech representations learned in a self-supervised fashion from massive unlabeled speech corpora have been adapted successfully toward several downstream tasks. However, such representations may be skewed toward canonical data characteristics of such corpora and perform poorly on atypical, non-native accented speaker populations. With the state-of-the-art HuBERT model as a baseline, we propose and investigate self-supervised adaptation of speech representations to such populations in a parameter-efficient way via training accent-specific residual adapters. We experiment with 4 accents and choose automatic speech recognition (ASR) as the downstream task of interest. We obtain strong word error rate reductions (WERR) over HuBERT-large for all 4 accents, with a mean WERR of 22.7% with accent-specific adapters and a mean WERR of 25.1% if the entire encoder is accent-adapted. While our experiments utilize HuBERT and ASR as the downstream task, our proposed approach is both model and task-agnostic.
Rethinking the Role of Scale for In-Context Learning: An Interpretability-based Case Study at 66 Billion Scale
Dec 18, 2022



Language models have been shown to perform better with an increase in scale on a wide variety of tasks via the in-context learning paradigm. In this paper, we investigate the hypothesis that the ability of a large language model to in-context learn-perform a task is not uniformly spread across all of its underlying components. Using a 66 billion parameter language model (OPT-66B) across a diverse set of 14 downstream tasks, we find this is indeed the case: $\sim$70% of attention heads and $\sim$20% of feed forward networks can be removed with minimal decline in task performance. We find substantial overlap in the set of attention heads (un)important for in-context learning across tasks and number of in-context examples. We also address our hypothesis through a task-agnostic lens, finding that a small set of attention heads in OPT-66B score highly on their ability to perform primitive induction operations associated with in-context learning, namely, prefix matching and copying. These induction heads overlap with task-specific important heads, suggesting that induction heads are among the heads capable of more sophisticated behaviors associated with in-context learning. Overall, our study provides several insights that indicate large language models may be under-trained to perform in-context learning and opens up questions on how to pre-train language models to more effectively perform in-context learning.
Scalable Multi-Agent Reinforcement Learning through Intelligent Information Aggregation
Nov 03, 2022



We consider the problem of multi-agent navigation and collision avoidance when observations are limited to the local neighborhood of each agent. We propose InforMARL, a novel architecture for multi-agent reinforcement learning (MARL) which uses local information intelligently to compute paths for all the agents in a decentralized manner. Specifically, InforMARL aggregates information about the local neighborhood of agents for both the actor and the critic using a graph neural network and can be used in conjunction with any standard MARL algorithm. We show that (1) in training, InforMARL has better sample efficiency and performance than baseline approaches, despite using less information, and (2) in testing, it scales well to environments with arbitrary numbers of agents and obstacles.
Alexa Teacher Model: Pretraining and Distilling Multi-Billion-Parameter Encoders for Natural Language Understanding Systems
Jun 15, 2022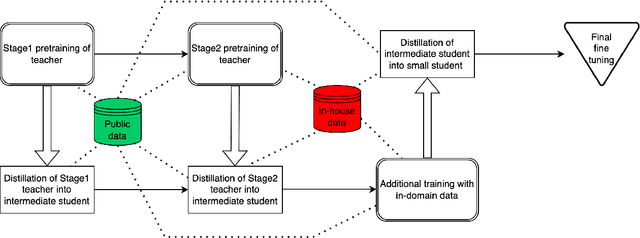
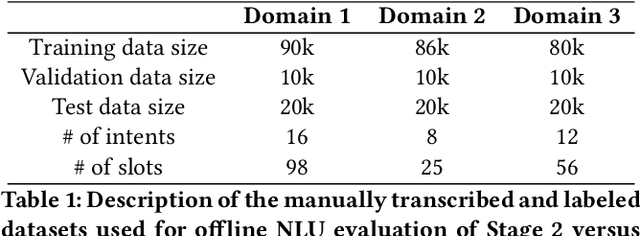
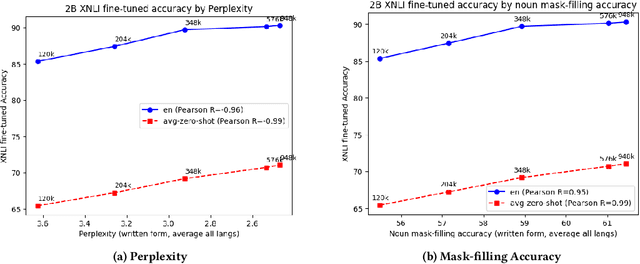
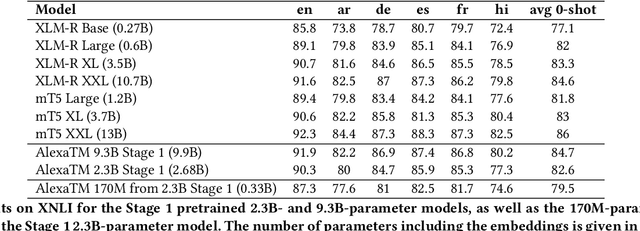
We present results from a large-scale experiment on pretraining encoders with non-embedding parameter counts ranging from 700M to 9.3B, their subsequent distillation into smaller models ranging from 17M-170M parameters, and their application to the Natural Language Understanding (NLU) component of a virtual assistant system. Though we train using 70% spoken-form data, our teacher models perform comparably to XLM-R and mT5 when evaluated on the written-form Cross-lingual Natural Language Inference (XNLI) corpus. We perform a second stage of pretraining on our teacher models using in-domain data from our system, improving error rates by 3.86% relative for intent classification and 7.01% relative for slot filling. We find that even a 170M-parameter model distilled from our Stage 2 teacher model has 2.88% better intent classification and 7.69% better slot filling error rates when compared to the 2.3B-parameter teacher trained only on public data (Stage 1), emphasizing the importance of in-domain data for pretraining. When evaluated offline using labeled NLU data, our 17M-parameter Stage 2 distilled model outperforms both XLM-R Base (85M params) and DistillBERT (42M params) by 4.23% to 6.14%, respectively. Finally, we present results from a full virtual assistant experimentation platform, where we find that models trained using our pretraining and distillation pipeline outperform models distilled from 85M-parameter teachers by 3.74%-4.91% on an automatic measurement of full-system user dissatisfaction.
* KDD 2022
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Online Learning for Traffic Routing under Unknown Preferences
Mar 31, 2022
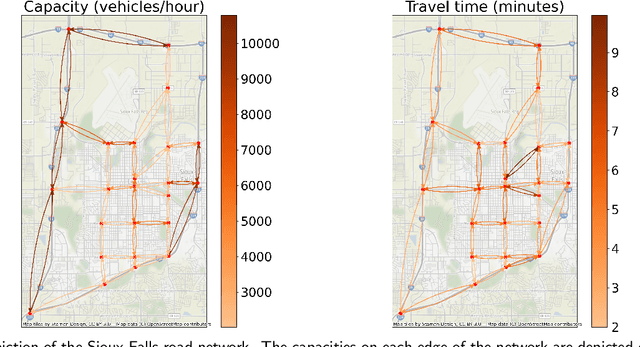
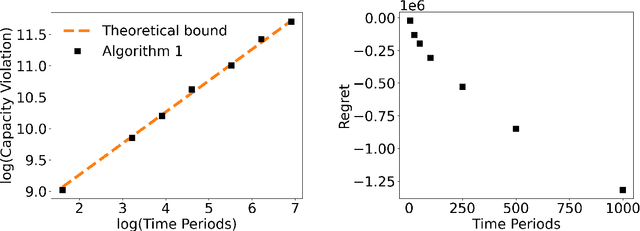
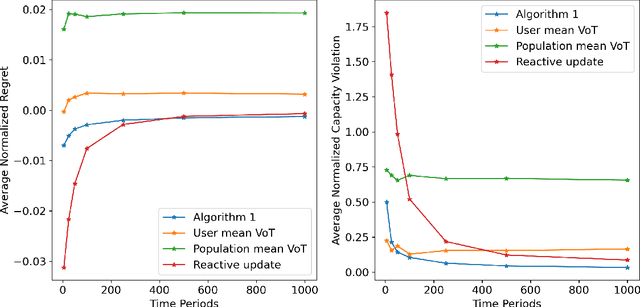
In transportation networks, users typically choose routes in a decentralized and self-interested manner to minimize their individual travel costs, which, in practice, often results in inefficient overall outcomes for society. As a result, there has been a growing interest in designing road tolling schemes to cope with these efficiency losses and steer users toward a system-efficient traffic pattern. However, the efficacy of road tolling schemes often relies on having access to complete information on users' trip attributes, such as their origin-destination (O-D) travel information and their values of time, which may not be available in practice. Motivated by this practical consideration, we propose an online learning approach to set tolls in a traffic network to drive heterogeneous users with different values of time toward a system-efficient traffic pattern. In particular, we develop a simple yet effective algorithm that adjusts tolls at each time period solely based on the observed aggregate flows on the roads of the network without relying on any additional trip attributes of users, thereby preserving user privacy. In the setting where the O-D pairs and values of time of users are drawn i.i.d. at each period, we show that our approach obtains an expected regret and road capacity violation of $O(\sqrt{T})$, where $T$ is the number of periods over which tolls are updated. Our regret guarantee is relative to an offline oracle that has complete information on users' trip attributes. We further establish a $\Omega(\sqrt{T})$ lower bound on the regret of any algorithm, which establishes that our algorithm is optimal up to constants. Finally, we demonstrate the superior performance of our approach relative to several benchmarks on a real-world transportation network, thereby highlighting its practical applicability.