 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe end of radical concept nativism
May 23, 2025Though humans seem to be remarkable learners, arguments in cognitive science and philosophy of mind have long maintained that learning something fundamentally new is impossible. Specifically, Jerry Fodor's arguments for radical concept nativism hold that most, if not all, concepts are innate and that what many call concept learning never actually leads to the acquisition of new concepts. These arguments have deeply affected cognitive science, and many believe that the counterarguments to radical concept nativism have been either unsuccessful or only apply to a narrow class of concepts. This paper first reviews the features and limitations of prior arguments. We then identify three critical points - related to issues of expressive power, conceptual structure, and concept possession - at which the arguments in favor of radical concept nativism diverge from describing actual human cognition. We use ideas from computer science and information theory to formalize the relevant ideas in ways that are arguably more scientifically productive. We conclude that, as a result, there is an important sense in which people do indeed learn new concepts.
Reliable Reasoning Beyond Natural Language
Jul 16, 2024Despite their linguistic competence, Large Language models (LLMs) often exhibit limitations in their ability to reason reliably and flexibly. To address this, we propose a neurosymbolic approach that prompts LLMs to extract and encode all relevant information from a problem statement as logical code statements, and then use a logic programming language (Prolog) to conduct the iterative computations of explicit deductive reasoning. Our approach significantly enhances the performance of LLMs on the standard mathematical reasoning benchmark, GSM8k, and the Navigate dataset from the BIG-bench dataset. Additionally, we introduce a novel dataset, the Non-Linear Reasoning (NLR) dataset, consisting of 55 unique word problems that target the shortcomings of the next token prediction paradigm of LLMs and require complex non-linear reasoning but only basic arithmetic skills to solve. Our findings demonstrate that the integration of Prolog enables LLMs to achieve high performance on the NLR dataset, which even the most advanced language models (including GPT4) fail to solve using text only.
How to enumerate trees from a context-free grammar
Apr 30, 2023I present a simple algorithm for enumerating the trees generated by a Context Free Grammar (CFG). The algorithm uses a pairing function to form a bijection between CFG derivations and natural numbers, so that trees can be uniquely decoded from counting. This provides a general way to number expressions in natural logical languages, and potentially can be extended to other combinatorial problems. I also show how this algorithm may be generalized to more general forms of derivation, including analogs of Lempel-Ziv coding on trees.
Meaning without reference in large language models
Aug 12, 2022The widespread success of large language models (LLMs) has been met with skepticism that they possess anything like human concepts or meanings. Contrary to claims that LLMs possess no meaning whatsoever, we argue that they likely capture important aspects of meaning, and moreover work in a way that approximates a compelling account of human cognition in which meaning arises from conceptual role. Because conceptual role is defined by the relationships between internal representational states, meaning cannot be determined from a model's architecture, training data, or objective function, but only by examination of how its internal states relate to each other. This approach may clarify why and how LLMs are so successful and suggest how they can be made more human-like.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
People infer recursive visual concepts from just a few examples
Apr 17, 2019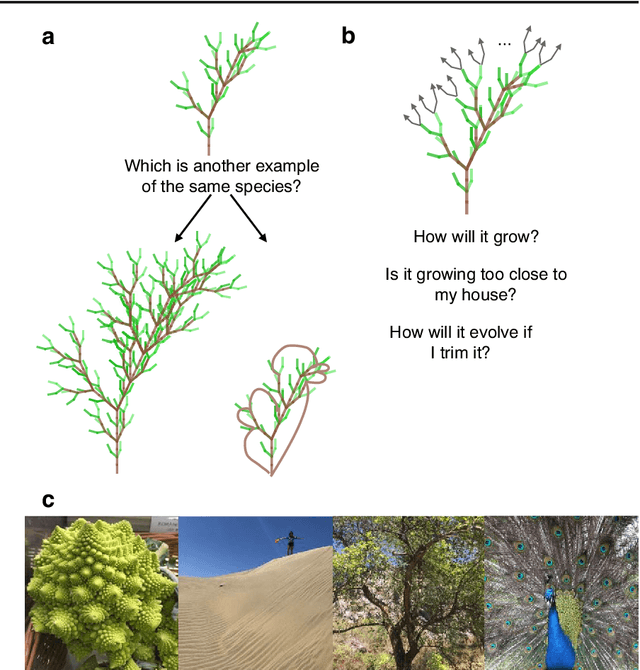
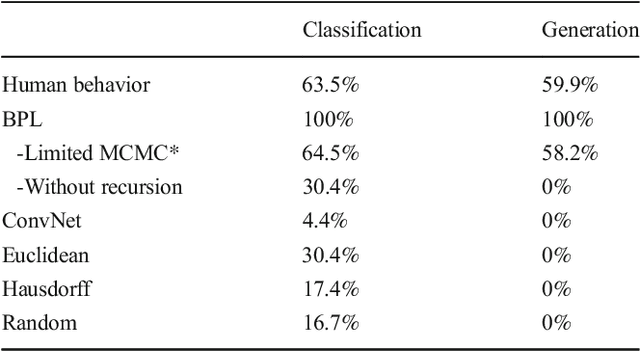
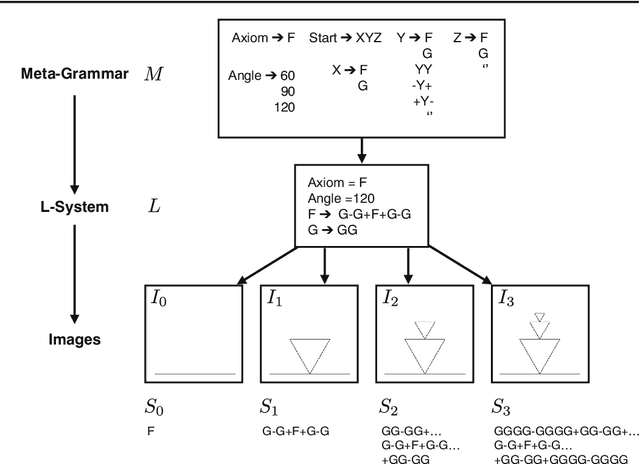
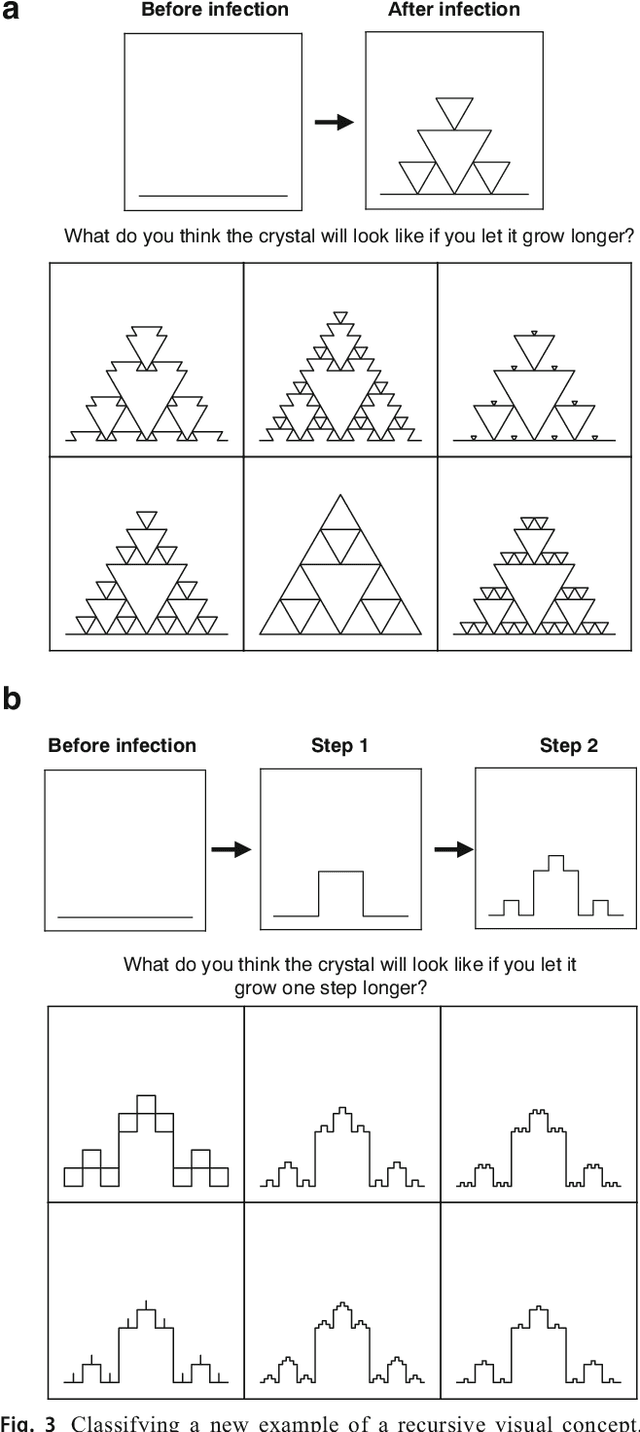
Machine learning has made major advances in categorizing objects in images, yet the best algorithms miss important aspects of how people learn and think about categories. People can learn richer concepts from fewer examples, including causal models that explain how members of a category are formed. Here, we explore the limits of this human ability to infer causal "programs" -- latent generating processes with nontrivial algorithmic properties -- from one, two, or three visual examples. People were asked to extrapolate the programs in several ways, for both classifying and generating new examples. As a theory of these inductive abilities, we present a Bayesian program learning model that searches the space of programs for the best explanation of the observations. Although variable, people's judgments are broadly consistent with the model and inconsistent with several alternatives, including a pre-trained deep neural network for object recognition, indicating that people can learn and reason with rich algorithmic abstractions from sparse input data.
The Natural Stories Corpus
Aug 18, 2017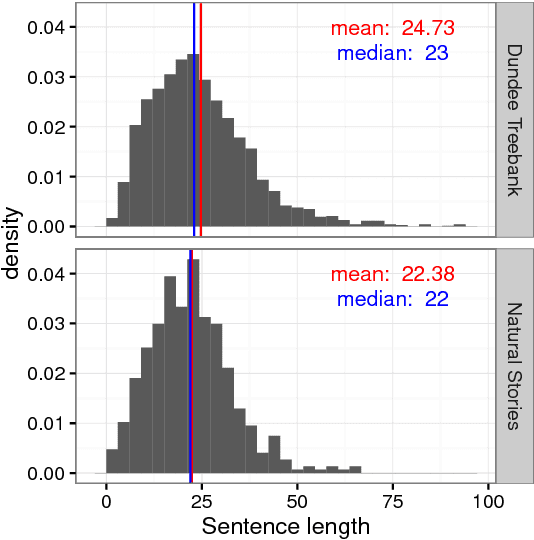
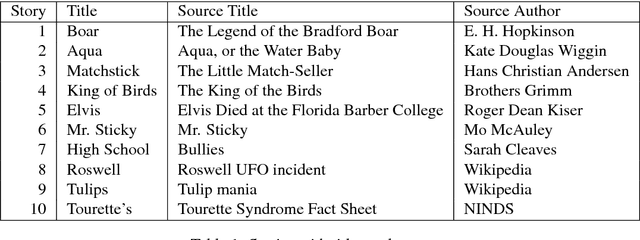
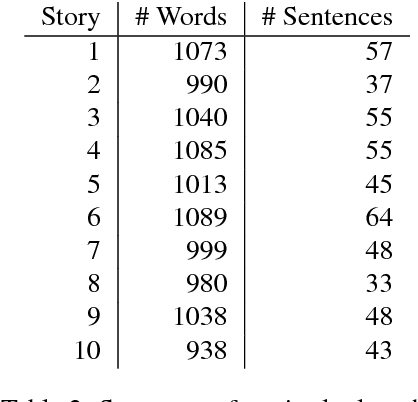
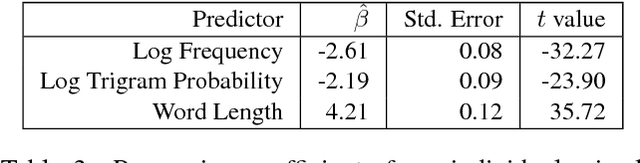
It is now a common practice to compare models of human language processing by predicting participant reactions (such as reading times) to corpora consisting of rich naturalistic linguistic materials. However, many of the corpora used in these studies are based on naturalistic text and thus do not contain many of the low-frequency syntactic constructions that are often required to distinguish processing theories. Here we describe a new corpus consisting of English texts edited to contain many low-frequency syntactic constructions while still sounding fluent to native speakers. The corpus is annotated with hand-corrected parse trees and includes self-paced reading time data. Here we give an overview of the content of the corpus and release the data.
Information content versus word length in natural language: A reply to Ferrer-i-Cancho and Moscoso del Prado Martin [arXiv:1209.1751]
Jul 25, 2013Recently, Ferrer i Cancho and Moscoso del Prado Martin [arXiv:1209.1751] argued that an observed linear relationship between word length and average surprisal (Piantadosi, Tily, & Gibson, 2011) is not evidence for communicative efficiency in human language. We discuss several shortcomings of their approach and critique: their model critically rests on inaccurate assumptions, is incapable of explaining key surprisal patterns in language, and is incompatible with recent behavioral results. More generally, we argue that statistical models must not critically rely on assumptions that are incompatible with the real system under study.