 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Gender Alternatives in Machine Translation
Jul 29, 2024



Machine translation (MT) systems often translate terms with ambiguous gender (e.g., English term "the nurse") into the gendered form that is most prevalent in the systems' training data (e.g., "enfermera", the Spanish term for a female nurse). This often reflects and perpetuates harmful stereotypes present in society. With MT user interfaces in mind that allow for resolving gender ambiguity in a frictionless manner, we study the problem of generating all grammatically correct gendered translation alternatives. We open source train and test datasets for five language pairs and establish benchmarks for this task. Our key technical contribution is a novel semi-supervised solution for generating alternatives that integrates seamlessly with standard MT models and maintains high performance without requiring additional components or increasing inference overhead.
Joint Speech Transcription and Translation: Pseudo-Labeling with Out-of-Distribution Data
Dec 20, 2022



Self-training has been shown to be helpful in addressing data scarcity for many domains, including vision, speech, and language. Specifically, self-training, or pseudo-labeling, labels unsupervised data and adds that to the training pool. In this work, we investigate and use pseudo-labeling for a recently proposed novel setup: joint transcription and translation of speech, which suffers from an absence of sufficient data resources. We show that under such data-deficient circumstances, the unlabeled data can significantly vary in domain from the supervised data, which results in pseudo-label quality degradation. We investigate two categories of remedies that require no additional supervision and target the domain mismatch: pseudo-label filtering and data augmentation. We show that pseudo-label analysis and processing as such results in additional gains on top of the vanilla pseudo-labeling setup resulting in total improvements of up to 0.6% absolute WER and 2.2 BLEU points.
Checks and Strategies for Enabling Code-Switched Machine Translation
Oct 11, 2022
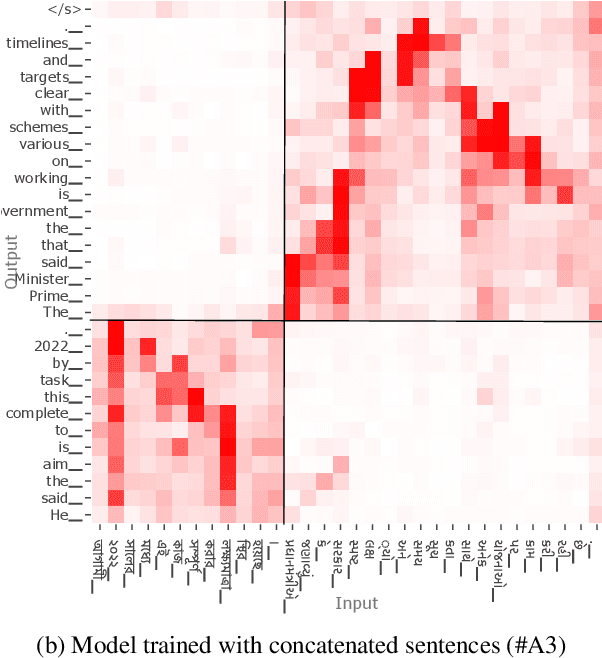
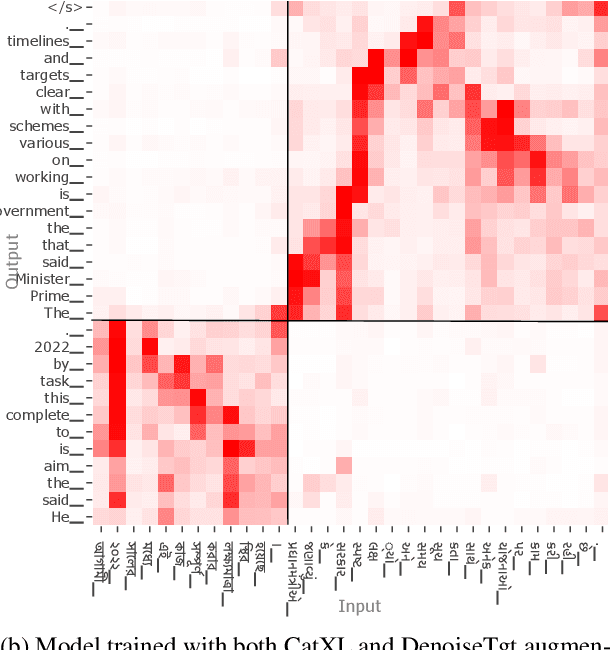
Code-switching is a common phenomenon among multilingual speakers, where alternation between two or more languages occurs within the context of a single conversation. While multilingual humans can seamlessly switch back and forth between languages, multilingual neural machine translation (NMT) models are not robust to such sudden changes in input. This work explores multilingual NMT models' ability to handle code-switched text. First, we propose checks to measure switching capability. Second, we investigate simple and effective data augmentation methods that can enhance an NMT model's ability to support code-switching. Finally, by using a glass-box analysis of attention modules, we demonstrate the effectiveness of these methods in improving robustness.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Know Where You're Going: Meta-Learning for Parameter-Efficient Fine-tuning
May 25, 2022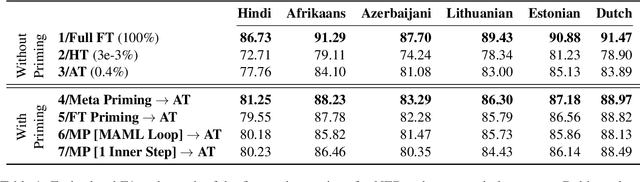
A recent family of techniques, dubbed as lightweight fine-tuning methods, facilitates parameter-efficient transfer learning by updating only a small set of additional parameters while keeping the parameters of the pretrained language model frozen. While proven to be an effective method, there are no existing studies on if and how such knowledge of the downstream fine-tuning approach should affect the pretraining stage. In this work, we show that taking the ultimate choice of fine-tuning method into consideration boosts the performance of parameter-efficient fine-tuning. By relying on optimization-based meta-learning using MAML with certain modifications for our distinct purpose, we prime the pretrained model specifically for parameter-efficient fine-tuning, resulting in gains of up to 1.7 points on cross-lingual NER fine-tuning. Our ablation settings and analyses further reveal that the tweaks we introduce in MAML are crucial for the attained gains.
On the Strengths of Cross-Attention in Pretrained Transformers for Machine Translation
Apr 18, 2021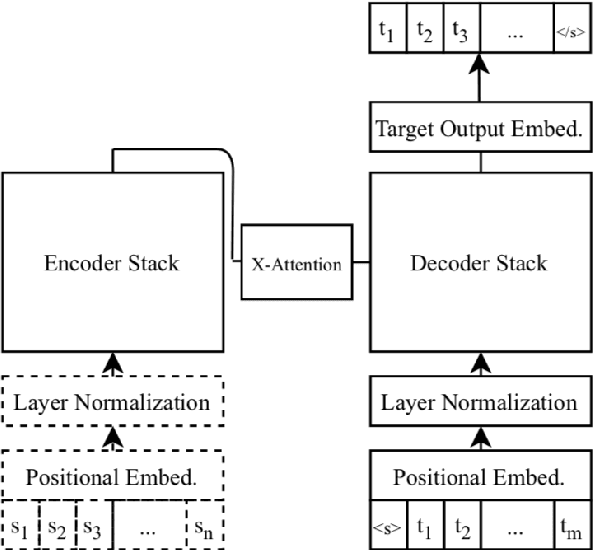
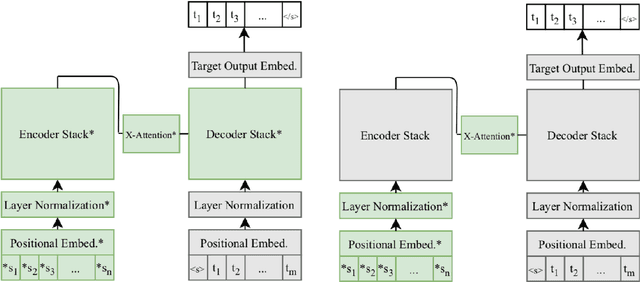
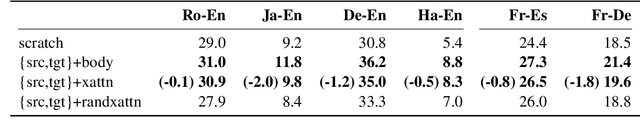
We study the power of cross-attention in the Transformer architecture within the context of machine translation. In transfer learning experiments, where we fine-tune a translation model on a dataset with one new language, we find that, apart from the new language's embeddings, only the cross-attention parameters need to be fine-tuned to obtain competitive BLEU performance. We provide insights into why this is the case and further find that limiting fine-tuning in this manner yields cross-lingually aligned type embeddings. The implications of this finding include a mitigation of catastrophic forgetting in the network and the potential for zero-shot translation.
ParsiNLU: A Suite of Language Understanding Challenges for Persian
Dec 11, 2020
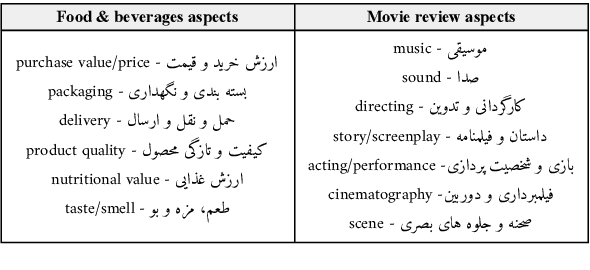
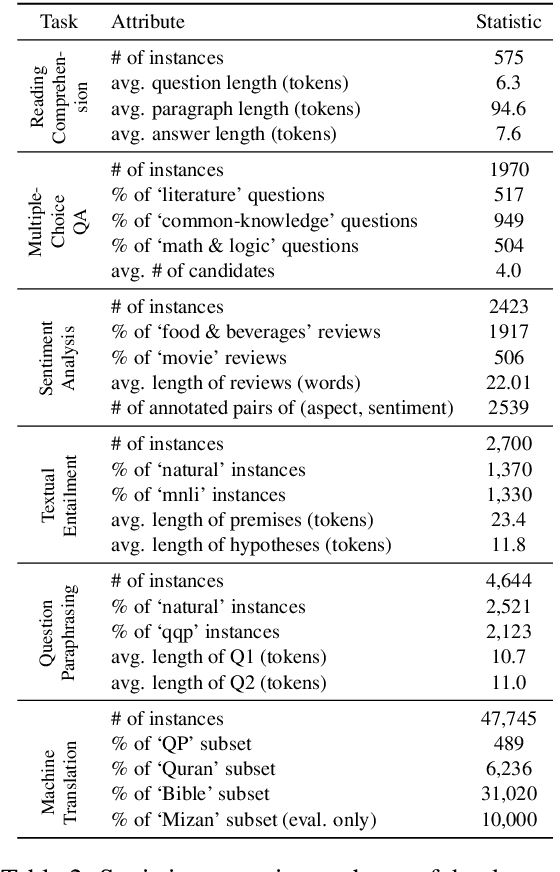
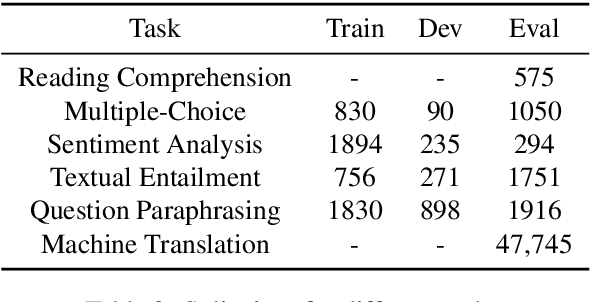
Despite the progress made in recent years in addressing natural language understanding (NLU) challenges, the majority of this progress remains to be concentrated on resource-rich languages like English. This work focuses on Persian language, one of the widely spoken languages in the world, and yet there are few NLU datasets available for this rich language. The availability of high-quality evaluation datasets is a necessity for reliable assessment of the progress on different NLU tasks and domains. We introduce ParsiNLU, the first benchmark in Persian language that includes a range of high-level tasks -- Reading Comprehension, Textual Entailment, etc. These datasets are collected in a multitude of ways, often involving manual annotations by native speakers. This results in over 14.5$k$ new instances across 6 distinct NLU tasks. Besides, we present the first results on state-of-the-art monolingual and multi-lingual pre-trained language-models on this benchmark and compare them with human performance, which provides valuable insights into our ability to tackle natural language understanding challenges in Persian. We hope ParsiNLU fosters further research and advances in Persian language understanding.
A Universal Parent Model for Low-Resource Neural Machine Translation Transfer
Sep 20, 2019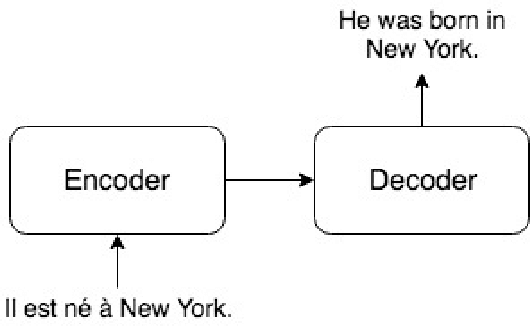
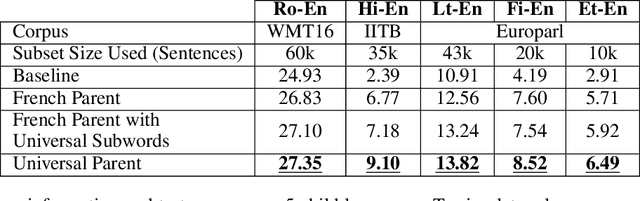
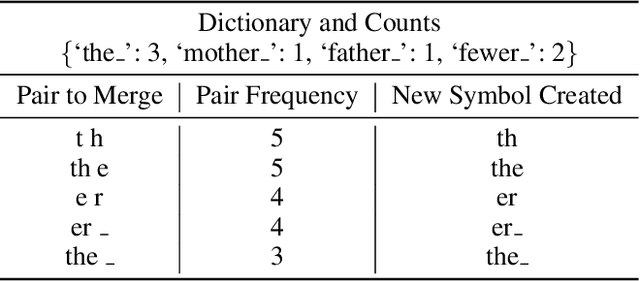
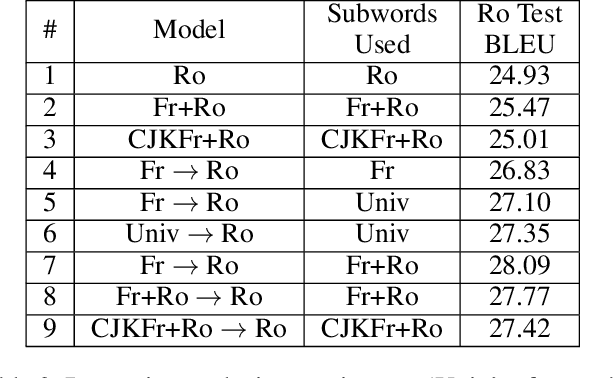
Transfer learning from a high-resource language pair `parent' has been proven to be an effective way to improve neural machine translation quality for low-resource language pairs `children.' However, previous approaches build a custom parent model or at least update an existing parent model's vocabulary for each child language pair they wish to train, in an effort to align parent and child vocabularies. This is not a practical solution. It is wasteful to devote the majority of training time for new language pairs to optimizing parameters on an unrelated data set. Further, this overhead reduces the utility of neural machine translation for deployment in humanitarian assistance scenarios, where extra time to deploy a new language pair can mean the difference between life and death. In this work, we present a `universal' pre-trained neural parent model with constant vocabulary that can be used as a starting point for training practically any new low-resource language to a fixed target language. We demonstrate that our approach, which leverages orthography unification and a broad-coverage approach to subword identification, generalizes well to several languages from a variety of families, and that translation systems built with our approach can be built more quickly than competing methods and with better quality as well.