 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-range Language Modeling with Self-retrieval
Jun 23, 2023Retrieval-augmented language models (LMs) have received much attention recently. However, typically the retriever is not trained jointly as a native component of the LM, but added to an already-pretrained LM, which limits the ability of the LM and the retriever to adapt to one another. In this work, we propose the Retrieval-Pretrained Transformer (RPT), an architecture and training procedure for jointly training a retrieval-augmented LM from scratch for the task of modeling long texts. Given a recently generated text chunk in a long document, the LM computes query representations, which are then used to retrieve earlier chunks in the document, located potentially tens of thousands of tokens before. Information from retrieved chunks is fused into the LM representations to predict the next target chunk. We train the retriever component with a semantic objective, where the goal is to retrieve chunks that increase the probability of the next chunk, according to a reference LM. We evaluate RPT on four long-range language modeling tasks, spanning books, code, and mathematical writing, and demonstrate that RPT improves retrieval quality and subsequently perplexity across the board compared to strong baselines.
From Pixels to UI Actions: Learning to Follow Instructions via Graphical User Interfaces
May 31, 2023



Much of the previous work towards digital agents for graphical user interfaces (GUIs) has relied on text-based representations (derived from HTML or other structured data sources), which are not always readily available. These input representations have been often coupled with custom, task-specific action spaces. This paper focuses on creating agents that interact with the digital world using the same conceptual interface that humans commonly use -- via pixel-based screenshots and a generic action space corresponding to keyboard and mouse actions. Building upon recent progress in pixel-based pretraining, we show, for the first time, that it is possible for such agents to outperform human crowdworkers on the MiniWob++ benchmark of GUI-based instruction following tasks.
ZeroSCROLLS: A Zero-Shot Benchmark for Long Text Understanding
May 23, 2023



We introduce ZeroSCROLLS, a zero-shot benchmark for natural language understanding over long texts, which contains only test sets, without training or development data. We adapt six tasks from the SCROLLS benchmark, and add four new datasets, including two novel information fusing tasks, such as aggregating the percentage of positive reviews. Using ZeroSCROLLS, we conduct a comprehensive evaluation of both open-source and closed large language models, finding that Claude outperforms ChatGPT, and that GPT-4 achieves the highest average score. However, there is still room for improvement on multiple open challenges in ZeroSCROLLS, such as aggregation tasks, where models struggle to pass the naive baseline. As the state of the art is a moving target, we invite researchers to evaluate their ideas on the live ZeroSCROLLS leaderboard
Answering Questions by Meta-Reasoning over Multiple Chains of Thought
Apr 25, 2023



Modern systems for multi-hop question answering (QA) typically break questions into a sequence of reasoning steps, termed chain-of-thought (CoT), before arriving at a final answer. Often, multiple chains are sampled and aggregated through a voting mechanism over the final answers, but the intermediate steps themselves are discarded. While such approaches improve performance, they do not consider the relations between intermediate steps across chains and do not provide a unified explanation for the predicted answer. We introduce Multi-Chain Reasoning (MCR), an approach which prompts large language models to meta-reason over multiple chains of thought, rather than aggregating their answers. MCR examines different reasoning chains, mixes information between them and selects the most relevant facts in generating an explanation and predicting the answer. MCR outperforms strong baselines on 7 multi-hop QA datasets. Moreover, our analysis reveals that MCR explanations exhibit high quality, enabling humans to verify its answers.
Crawling the Internal Knowledge-Base of Language Models
Jan 30, 2023Language models are trained on large volumes of text, and as a result their parameters might contain a significant body of factual knowledge. Any downstream task performed by these models implicitly builds on these facts, and thus it is highly desirable to have means for representing this body of knowledge in an interpretable way. However, there is currently no mechanism for such a representation. Here, we propose to address this goal by extracting a knowledge-graph of facts from a given language model. We describe a procedure for ``crawling'' the internal knowledge-base of a language model. Specifically, given a seed entity, we expand a knowledge-graph around it. The crawling procedure is decomposed into sub-tasks, realized through specially designed prompts that control for both precision (i.e., that no wrong facts are generated) and recall (i.e., the number of facts generated). We evaluate our approach on graphs crawled starting from dozens of seed entities, and show it yields high precision graphs (82-92%), while emitting a reasonable number of facts per entity.
What Are You Token About? Dense Retrieval as Distributions Over the Vocabulary
Dec 20, 2022



Dual encoders are now the dominant architecture for dense retrieval. Yet, we have little understanding of how they represent text, and why this leads to good performance. In this work, we shed light on this question via distributions over the vocabulary. We propose to interpret the vector representations produced by dual encoders by projecting them into the model's vocabulary space. We show that the resulting distributions over vocabulary tokens are intuitive and contain rich semantic information. We find that this view can explain some of the failure cases of dense retrievers. For example, the inability of models to handle tail entities can be explained via a tendency of the token distributions to forget some of the tokens of those entities. We leverage this insight and propose a simple way to enrich query and passage representations with lexical information at inference time, and show that this significantly improves performance compared to the original model in out-of-domain settings.
Diverse Demonstrations Improve In-context Compositional Generalization
Dec 20, 2022In-context learning has shown great success in i.i.d semantic parsing splits, where the training and test sets are drawn from the same distribution. In this setup, models are typically prompted with demonstrations that are similar to the input question. However, in the setup of compositional generalization, where models are tested on outputs with structures that are absent from the training set, selecting similar demonstrations is insufficient, as often no example will be similar enough to the input. In this work, we propose a method to select diverse demonstrations that aims to collectively cover all of the structures required in the output program, in order to encourage the model to generalize to new structures from these demonstrations. We empirically show that combining diverse demonstrations with in-context learning substantially improves performance across three compositional generalization semantic parsing datasets in the pure in-context learning setup and when combined with finetuning.
Simplifying and Understanding State Space Models with Diagonal Linear RNNs
Dec 07, 2022



Sequence models based on linear state spaces (SSMs) have recently emerged as a promising choice of architecture for modeling long range dependencies across various modalities. However, they invariably rely on discretization of a continuous state space, which complicates their presentation and understanding. In this work, we dispose of the discretization step, and propose a model based on vanilla Diagonal Linear RNNs ($\mathrm{DLR}$). We empirically show that $\mathrm{DLR}$ is as performant as previously-proposed SSMs in the presence of strong supervision, despite being conceptually much simpler. Moreover, we characterize the expressivity of SSMs (including $\mathrm{DLR}$) and attention-based models via a suite of $13$ synthetic sequence-to-sequence tasks involving interactions over tens of thousands of tokens, ranging from simple operations, such as shifting an input sequence, to detecting co-dependent visual features over long spatial ranges in flattened images. We find that while SSMs report near-perfect performance on tasks that can be modeled via $\textit{few}$ convolutional kernels, they struggle on tasks requiring $\textit{many}$ such kernels and especially when the desired sequence manipulation is $\textit{context-dependent}$. For example, $\mathrm{DLR}$ learns to perfectly shift a $0.5M$-long input by an arbitrary number of positions but fails when the shift size depends on context. Despite these limitations, $\mathrm{DLR}$ reaches high performance on two higher-order reasoning tasks $\mathrm{ListOpsSubTrees}$ and $\mathrm{PathfinderSegmentation}\text{-}\mathrm{256}$ with input lengths $8K$ and $65K$ respectively, and gives encouraging performance on $\mathrm{PathfinderSegmentation}\text{-}\mathrm{512}$ with input length $262K$ for which attention is not a viable choice.
Training Vision-Language Models with Less Bimodal Supervision
Nov 01, 2022Standard practice in pretraining multimodal models, such as vision-language models, is to rely on pairs of aligned inputs from both modalities, for example, aligned image-text pairs. However, such pairs can be difficult to obtain in low-resource settings and for some modality pairs (e.g., structured tables and images). In this work, we investigate the extent to which we can reduce the reliance on such parallel data, which we term \emph{bimodal supervision}, and use models that are pretrained on each modality independently. We experiment with a high-performing vision-language model, and analyze the effect of bimodal supervision on three vision-language tasks. We find that on simpler tasks, such as VQAv2 and GQA, one can eliminate bimodal supervision completely, suffering only a minor loss in performance. Conversely, for NLVR2, which requires more complex reasoning, training without bimodal supervision leads to random performance. Nevertheless, using only 5\% of the bimodal data (142K images along with their captions), or leveraging weak supervision in the form of a list of machine-generated labels for each image, leads to only a moderate degradation compared to using 3M image-text pairs: 74\%$\rightarrow$$\sim$70\%. Our code is available at https://github.com/eladsegal/less-bimodal-sup.
Analyzing Transformers in Embedding Space
Sep 06, 2022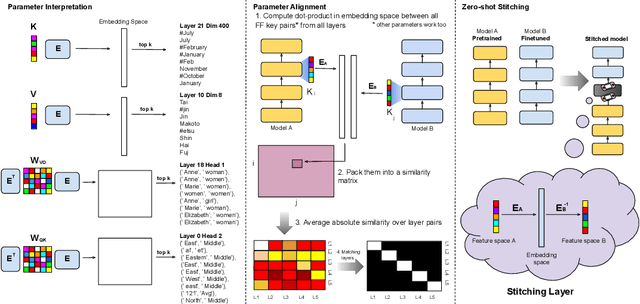
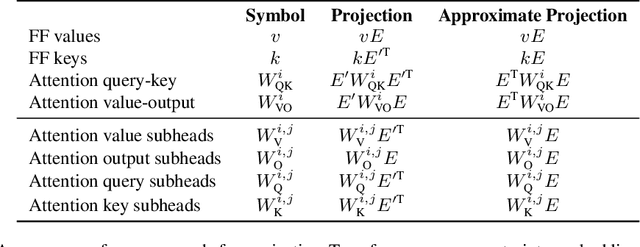
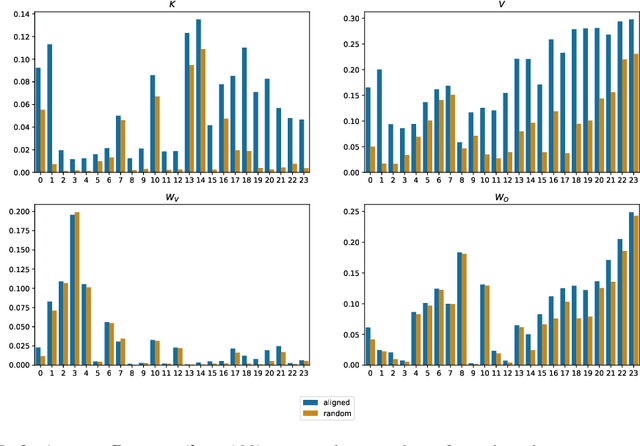
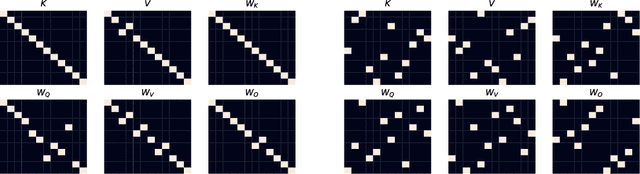
Understanding Transformer-based models has attracted significant attention, as they lie at the heart of recent technological advances across machine learning. While most interpretability methods rely on running models over inputs, recent work has shown that a zero-pass approach, where parameters are interpreted directly without a forward/backward pass is feasible for some Transformer parameters, and for two-layer attention networks. In this work, we present a theoretical analysis where all parameters of a trained Transformer are interpreted by projecting them into the embedding space, that is, the space of vocabulary items they operate on. We derive a simple theoretical framework to support our arguments and provide ample evidence for its validity. First, an empirical analysis showing that parameters of both pretrained and fine-tuned models can be interpreted in embedding space. Second, we present two applications of our framework: (a) aligning the parameters of different models that share a vocabulary, and (b) constructing a classifier without training by ``translating'' the parameters of a fine-tuned classifier to parameters of a different model that was only pretrained. Overall, our findings open the door to interpretation methods that, at least in part, abstract away from model specifics and operate in the embedding space only.