 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging In-Context Learning for Language Model Agents
Jun 16, 2025In-context learning (ICL) with dynamically selected demonstrations combines the flexibility of prompting large language models (LLMs) with the ability to leverage training data to improve performance. While ICL has been highly successful for prediction and generation tasks, leveraging it for agentic tasks that require sequential decision making is challenging -- one must think not only about how to annotate long trajectories at scale and how to select demonstrations, but also what constitutes demonstrations, and when and where to show them. To address this, we first propose an algorithm that leverages an LLM with retries along with demonstrations to automatically and efficiently annotate agentic tasks with solution trajectories. We then show that set-selection of trajectories of similar tasks as demonstrations significantly improves performance, reliability, robustness, and efficiency of LLM agents. However, trajectory demonstrations have a large inference cost overhead. We show that this can be mitigated by using small trajectory snippets at every step instead of an additional trajectory. We find that demonstrations obtained from larger models (in the annotation phase) also improve smaller models, and that ICL agents can even rival costlier trained agents. Thus, our results reveal that ICL, with careful use, can be very powerful for agentic tasks as well.
DataDecide: How to Predict Best Pretraining Data with Small Experiments
Apr 15, 2025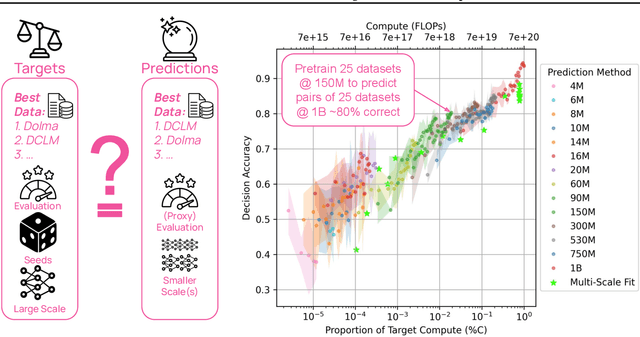
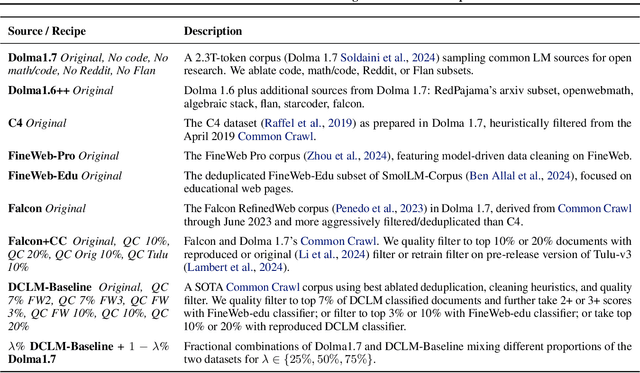
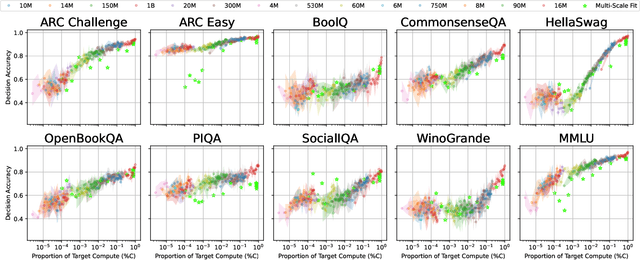
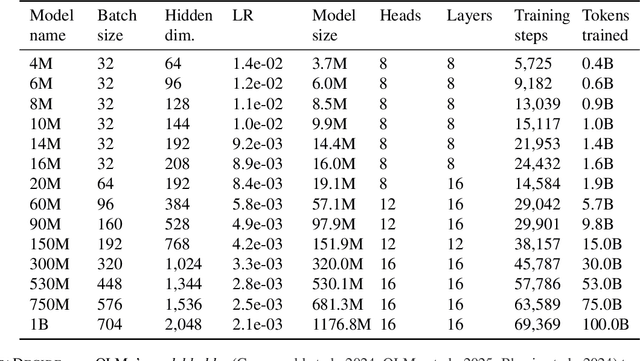
Because large language models are expensive to pretrain on different datasets, using smaller-scale experiments to decide on data is crucial for reducing costs. Which benchmarks and methods of making decisions from observed performance at small scale most accurately predict the datasets that yield the best large models? To empower open exploration of this question, we release models, data, and evaluations in DataDecide -- the most extensive open suite of models over differences in data and scale. We conduct controlled pretraining experiments across 25 corpora with differing sources, deduplication, and filtering up to 100B tokens, model sizes up to 1B parameters, and 3 random seeds. We find that the ranking of models at a single, small size (e.g., 150M parameters) is a strong baseline for predicting best models at our larger target scale (1B) (~80% of com parisons correct). No scaling law methods among 8 baselines exceed the compute-decision frontier of single-scale predictions, but DataDecide can measure improvement in future scaling laws. We also identify that using continuous likelihood metrics as proxies in small experiments makes benchmarks including MMLU, ARC, HellaSwag, MBPP, and HumanEval >80% predictable at the target 1B scale with just 0.01% of the compute.
SUPER: Evaluating Agents on Setting Up and Executing Tasks from Research Repositories
Sep 11, 2024Given that Large Language Models (LLMs) have made significant progress in writing code, can they now be used to autonomously reproduce results from research repositories? Such a capability would be a boon to the research community, helping researchers validate, understand, and extend prior work. To advance towards this goal, we introduce SUPER, the first benchmark designed to evaluate the capability of LLMs in setting up and executing tasks from research repositories. SUPERaims to capture the realistic challenges faced by researchers working with Machine Learning (ML) and Natural Language Processing (NLP) research repositories. Our benchmark comprises three distinct problem sets: 45 end-to-end problems with annotated expert solutions, 152 sub problems derived from the expert set that focus on specific challenges (e.g., configuring a trainer), and 602 automatically generated problems for larger-scale development. We introduce various evaluation measures to assess both task success and progress, utilizing gold solutions when available or approximations otherwise. We show that state-of-the-art approaches struggle to solve these problems with the best model (GPT-4o) solving only 16.3% of the end-to-end set, and 46.1% of the scenarios. This illustrates the challenge of this task, and suggests that SUPER can serve as a valuable resource for the community to make and measure progress.
AssistantBench: Can Web Agents Solve Realistic and Time-Consuming Tasks?
Jul 22, 2024Language agents, built on top of language models (LMs), are systems that can interact with complex environments, such as the open web. In this work, we examine whether such agents can perform realistic and time-consuming tasks on the web, e.g., monitoring real-estate markets or locating relevant nearby businesses. We introduce AssistantBench, a challenging new benchmark consisting of 214 realistic tasks that can be automatically evaluated, covering different scenarios and domains. We find that AssistantBench exposes the limitations of current systems, including language models and retrieval-augmented language models, as no model reaches an accuracy of more than 25 points. While closed-book LMs perform well, they exhibit low precision since they tend to hallucinate facts. State-of-the-art web agents reach a score of near zero. Additionally, we introduce SeePlanAct (SPA), a new web agent that significantly outperforms previous agents, and an ensemble of SPA and closed-book models reaches the best overall performance. Moreover, we analyze failures of current systems and highlight that web navigation remains a major challenge.
Aurora-M: The First Open Source Multilingual Language Model Red-teamed according to the U.S. Executive Order
Mar 30, 2024



Pretrained language models underpin several AI applications, but their high computational cost for training limits accessibility. Initiatives such as BLOOM and StarCoder aim to democratize access to pretrained models for collaborative community development. However, such existing models face challenges: limited multilingual capabilities, continual pretraining causing catastrophic forgetting, whereas pretraining from scratch is computationally expensive, and compliance with AI safety and development laws. This paper presents Aurora-M, a 15B parameter multilingual open-source model trained on English, Finnish, Hindi, Japanese, Vietnamese, and code. Continually pretrained from StarCoderPlus on 435 billion additional tokens, Aurora-M surpasses 2 trillion tokens in total training token count. It is the first open-source multilingual model fine-tuned on human-reviewed safety instructions, thus aligning its development not only with conventional red-teaming considerations, but also with the specific concerns articulated in the Biden-Harris Executive Order on the Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence. Aurora-M is rigorously evaluated across various tasks and languages, demonstrating robustness against catastrophic forgetting and outperforming alternatives in multilingual settings, particularly in safety evaluations. To promote responsible open-source LLM development, Aurora-M and its variants are released at https://huggingface.co/collections/aurora-m/aurora-m-models-65fdfdff62471e09812f5407 .
Dolma: an Open Corpus of Three Trillion Tokens for Language Model Pretraining Research
Jan 31, 2024



Language models have become a critical technology to tackling a wide range of natural language processing tasks, yet many details about how the best-performing language models were developed are not reported. In particular, information about their pretraining corpora is seldom discussed: commercial language models rarely provide any information about their data; even open models rarely release datasets they are trained on, or an exact recipe to reproduce them. As a result, it is challenging to conduct certain threads of language modeling research, such as understanding how training data impacts model capabilities and shapes their limitations. To facilitate open research on language model pretraining, we release Dolma, a three trillion tokens English corpus, built from a diverse mixture of web content, scientific papers, code, public-domain books, social media, and encyclopedic materials. In addition, we open source our data curation toolkit to enable further experimentation and reproduction of our work. In this report, we document Dolma, including its design principles, details about its construction, and a summary of its contents. We interleave this report with analyses and experimental results from training language models on intermediate states of Dolma to share what we have learned about important data curation practices, including the role of content or quality filters, deduplication, and multi-source mixing. Dolma has been used to train OLMo, a state-of-the-art, open language model and framework designed to build and study the science of language modeling.
Leveraging Code to Improve In-context Learning for Semantic Parsing
Nov 16, 2023



In-context learning (ICL) is an appealing approach for semantic parsing due to its few-shot nature and improved generalization. However, learning to parse to rare domain-specific languages (DSLs) from just a few demonstrations is challenging, limiting the performance of even the most capable LLMs. In this work, we improve the effectiveness of ICL for semantic parsing by (1) using general-purpose programming languages such as Python instead of DSLs, and (2) augmenting prompts with a structured domain description that includes, e.g., the available classes and functions. We show that both these changes significantly improve accuracy across three popular datasets. Combined, they lead to dramatic improvements (e.g. 7.9% to 66.5% on SMCalFlow compositional split), nearly closing the performance gap between easier i.i.d.\ and harder compositional splits when used with a strong model, and reducing the need for a large number of demonstrations. We find that the resemblance of the target parse language to general-purpose code is a more important factor than the language's popularity in pre-training corpora. Our findings provide an improved methodology for building semantic parsers in the modern context of ICL with LLMs.
Answering Questions by Meta-Reasoning over Multiple Chains of Thought
Apr 25, 2023



Modern systems for multi-hop question answering (QA) typically break questions into a sequence of reasoning steps, termed chain-of-thought (CoT), before arriving at a final answer. Often, multiple chains are sampled and aggregated through a voting mechanism over the final answers, but the intermediate steps themselves are discarded. While such approaches improve performance, they do not consider the relations between intermediate steps across chains and do not provide a unified explanation for the predicted answer. We introduce Multi-Chain Reasoning (MCR), an approach which prompts large language models to meta-reason over multiple chains of thought, rather than aggregating their answers. MCR examines different reasoning chains, mixes information between them and selects the most relevant facts in generating an explanation and predicting the answer. MCR outperforms strong baselines on 7 multi-hop QA datasets. Moreover, our analysis reveals that MCR explanations exhibit high quality, enabling humans to verify its answers.
Diverse Demonstrations Improve In-context Compositional Generalization
Dec 20, 2022In-context learning has shown great success in i.i.d semantic parsing splits, where the training and test sets are drawn from the same distribution. In this setup, models are typically prompted with demonstrations that are similar to the input question. However, in the setup of compositional generalization, where models are tested on outputs with structures that are absent from the training set, selecting similar demonstrations is insufficient, as often no example will be similar enough to the input. In this work, we propose a method to select diverse demonstrations that aims to collectively cover all of the structures required in the output program, in order to encourage the model to generalize to new structures from these demonstrations. We empirically show that combining diverse demonstrations with in-context learning substantially improves performance across three compositional generalization semantic parsing datasets in the pure in-context learning setup and when combined with finetuning.
Training Vision-Language Models with Less Bimodal Supervision
Nov 01, 2022Standard practice in pretraining multimodal models, such as vision-language models, is to rely on pairs of aligned inputs from both modalities, for example, aligned image-text pairs. However, such pairs can be difficult to obtain in low-resource settings and for some modality pairs (e.g., structured tables and images). In this work, we investigate the extent to which we can reduce the reliance on such parallel data, which we term \emph{bimodal supervision}, and use models that are pretrained on each modality independently. We experiment with a high-performing vision-language model, and analyze the effect of bimodal supervision on three vision-language tasks. We find that on simpler tasks, such as VQAv2 and GQA, one can eliminate bimodal supervision completely, suffering only a minor loss in performance. Conversely, for NLVR2, which requires more complex reasoning, training without bimodal supervision leads to random performance. Nevertheless, using only 5\% of the bimodal data (142K images along with their captions), or leveraging weak supervision in the form of a list of machine-generated labels for each image, leads to only a moderate degradation compared to using 3M image-text pairs: 74\%$\rightarrow$$\sim$70\%. Our code is available at https://github.com/eladsegal/less-bimodal-sup.