 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLMEnt: A Suite for Analyzing Knowledge in Language Models from Pretraining Data to Representations
Sep 03, 2025



Language models (LMs) increasingly drive real-world applications that require world knowledge. However, the internal processes through which models turn data into representations of knowledge and beliefs about the world, are poorly understood. Insights into these processes could pave the way for developing LMs with knowledge representations that are more consistent, robust, and complete. To facilitate studying these questions, we present LMEnt, a suite for analyzing knowledge acquisition in LMs during pretraining. LMEnt introduces: (1) a knowledge-rich pretraining corpus, fully annotated with entity mentions, based on Wikipedia, (2) an entity-based retrieval method over pretraining data that outperforms previous approaches by as much as 80.4%, and (3) 12 pretrained models with up to 1B parameters and 4K intermediate checkpoints, with comparable performance to popular open-sourced models on knowledge benchmarks. Together, these resources provide a controlled environment for analyzing connections between entity mentions in pretraining and downstream performance, and the effects of causal interventions in pretraining data. We show the utility of LMEnt by studying knowledge acquisition across checkpoints, finding that fact frequency is key, but does not fully explain learning trends. We release LMEnt to support studies of knowledge in LMs, including knowledge representations, plasticity, editing, attribution, and learning dynamics.
The KoLMogorov Test: Compression by Code Generation
Mar 18, 2025Compression is at the heart of intelligence. A theoretically optimal way to compress any sequence of data is to find the shortest program that outputs that sequence and then halts. However, such 'Kolmogorov compression' is uncomputable, and code generating LLMs struggle to approximate this theoretical ideal, as it requires reasoning, planning and search capabilities beyond those of current models. In this work, we introduce the KoLMogorov-Test (KT), a compression-as-intelligence test for code generating LLMs. In KT a model is presented with a sequence of data at inference time, and asked to generate the shortest program that produces the sequence. We identify several benefits of KT for both evaluation and training: an essentially infinite number of problem instances of varying difficulty is readily available, strong baselines already exist, the evaluation metric (compression) cannot be gamed, and pretraining data contamination is highly unlikely. To evaluate current models, we use audio, text, and DNA data, as well as sequences produced by random synthetic programs. Current flagship models perform poorly - both GPT4-o and Llama-3.1-405B struggle on our natural and synthetic sequences. On our synthetic distribution, we are able to train code generation models with lower compression rates than previous approaches. Moreover, we show that gains on synthetic data generalize poorly to real data, suggesting that new innovations are necessary for additional gains on KT.
Preventing Rogue Agents Improves Multi-Agent Collaboration
Feb 09, 2025



Multi-agent systems, where specialized agents collaborate to solve a shared task hold great potential, from increased modularity to simulating complex environments. However, they also have a major caveat -- a single agent can cause the entire system to fail. Consider a simple game where the knowledge to solve the task is distributed between agents, which share information in a communication channel. At each round, any of the agents can terminate the game and make the final prediction, even if they are uncertain about the outcome of their action. Detection of such rogue agents $\textit{before they act}$ may prevent the system's failure. In this work, we propose to $\textit{monitor}$ agents during action prediction and $\textit{intervene}$ when a future error is likely to occur. To test our approach, we introduce WhoDunitEnv, a multi-agent collaboration environment that allows modular control over task complexity and communication structure. Experiments on two variants of WhoDunitEnv and the GovSim environment for resource sustainability show that our approach leads to substantial performance gains up to 17.4% and 20%, respectively. Moreover, a thorough analysis shows that our monitors successfully identify critical points of agent confusion and our interventions effectively stop agent errors from propagating.
The BrowserGym Ecosystem for Web Agent Research
Dec 10, 2024



The BrowserGym ecosystem addresses the growing need for efficient evaluation and benchmarking of web agents, particularly those leveraging automation and Large Language Models (LLMs) for web interaction tasks. Many existing benchmarks suffer from fragmentation and inconsistent evaluation methodologies, making it challenging to achieve reliable comparisons and reproducible results. BrowserGym aims to solve this by providing a unified, gym-like environment with well-defined observation and action spaces, facilitating standardized evaluation across diverse benchmarks. Combined with AgentLab, a complementary framework that aids in agent creation, testing, and analysis, BrowserGym offers flexibility for integrating new benchmarks while ensuring consistent evaluation and comprehensive experiment management. This standardized approach seeks to reduce the time and complexity of developing web agents, supporting more reliable comparisons and facilitating in-depth analysis of agent behaviors, and could result in more adaptable, capable agents, ultimately accelerating innovation in LLM-driven automation. As a supporting evidence, we conduct the first large-scale, multi-benchmark web agent experiment and compare the performance of 6 state-of-the-art LLMs across all benchmarks currently available in BrowserGym. Among other findings, our results highlight a large discrepancy between OpenAI and Anthropic's latests models, with Claude-3.5-Sonnet leading the way on almost all benchmarks, except on vision-related tasks where GPT-4o is superior. Despite these advancements, our results emphasize that building robust and efficient web agents remains a significant challenge, due to the inherent complexity of real-world web environments and the limitations of current models.
AssistantBench: Can Web Agents Solve Realistic and Time-Consuming Tasks?
Jul 22, 2024Language agents, built on top of language models (LMs), are systems that can interact with complex environments, such as the open web. In this work, we examine whether such agents can perform realistic and time-consuming tasks on the web, e.g., monitoring real-estate markets or locating relevant nearby businesses. We introduce AssistantBench, a challenging new benchmark consisting of 214 realistic tasks that can be automatically evaluated, covering different scenarios and domains. We find that AssistantBench exposes the limitations of current systems, including language models and retrieval-augmented language models, as no model reaches an accuracy of more than 25 points. While closed-book LMs perform well, they exhibit low precision since they tend to hallucinate facts. State-of-the-art web agents reach a score of near zero. Additionally, we introduce SeePlanAct (SPA), a new web agent that significantly outperforms previous agents, and an ensemble of SPA and closed-book models reaches the best overall performance. Moreover, we analyze failures of current systems and highlight that web navigation remains a major challenge.
From Loops to Oops: Fallback Behaviors of Language Models Under Uncertainty
Jul 08, 2024



Large language models (LLMs) often exhibit undesirable behaviors, such as hallucinations and sequence repetitions. We propose to view these behaviors as fallbacks that models exhibit under uncertainty, and investigate the connection between them. We categorize fallback behaviors -- sequence repetitions, degenerate text, and hallucinations -- and extensively analyze them in models from the same family that differ by the amount of pretraining tokens, parameter count, or the inclusion of instruction-following training. Our experiments reveal a clear and consistent ordering of fallback behaviors, across all these axes: the more advanced an LLM is (i.e., trained on more tokens, has more parameters, or instruction-tuned), its fallback behavior shifts from sequence repetitions, to degenerate text, and then to hallucinations. Moreover, the same ordering is observed throughout a single generation, even for the best-performing models; as uncertainty increases, models shift from generating hallucinations to producing degenerate text and then sequence repetitions. Lastly, we demonstrate that while common decoding techniques, such as random sampling, might alleviate some unwanted behaviors like sequence repetitions, they increase harder-to-detect hallucinations.
Making Retrieval-Augmented Language Models Robust to Irrelevant Context
Oct 02, 2023



Retrieval-augmented language models (RALMs) hold promise to produce language understanding systems that are are factual, efficient, and up-to-date. An important desideratum of RALMs, is that retrieved information helps model performance when it is relevant, and does not harm performance when it is not. This is particularly important in multi-hop reasoning scenarios, where misuse of irrelevant evidence can lead to cascading errors. However, recent work has shown that retrieval augmentation can sometimes have a negative effect on performance. In this work, we present a thorough analysis on five open-domain question answering benchmarks, characterizing cases when retrieval reduces accuracy. We then propose two methods to mitigate this issue. First, a simple baseline that filters out retrieved passages that do not entail question-answer pairs according to a natural language inference (NLI) model. This is effective in preventing performance reduction, but at a cost of also discarding relevant passages. Thus, we propose a method for automatically generating data to fine-tune the language model to properly leverage retrieved passages, using a mix of relevant and irrelevant contexts at training time. We empirically show that even 1,000 examples suffice to train the model to be robust to irrelevant contexts while maintaining high performance on examples with relevant ones.
Evaluating the Ripple Effects of Knowledge Editing in Language Models
Jul 24, 2023Modern language models capture a large body of factual knowledge. However, some facts can be incorrectly induced or become obsolete over time, resulting in factually incorrect generations. This has led to the development of various editing methods that allow updating facts encoded by the model. Evaluation of these methods has primarily focused on testing whether an individual fact has been successfully injected, and if similar predictions for other subjects have not changed. Here we argue that such evaluation is limited, since injecting one fact (e.g. ``Jack Depp is the son of Johnny Depp'') introduces a ``ripple effect'' in the form of additional facts that the model needs to update (e.g.``Jack Depp is the sibling of Lily-Rose Depp''). To address this issue, we propose a novel set of evaluation criteria that consider the implications of an edit on related facts. Using these criteria, we then construct \ripple{}, a diagnostic benchmark of 5K factual edits, capturing a variety of types of ripple effects. We evaluate prominent editing methods on \ripple{}, showing that current methods fail to introduce consistent changes in the model's knowledge. In addition, we find that a simple in-context editing baseline obtains the best scores on our benchmark, suggesting a promising research direction for model editing.
Answering Questions by Meta-Reasoning over Multiple Chains of Thought
Apr 25, 2023



Modern systems for multi-hop question answering (QA) typically break questions into a sequence of reasoning steps, termed chain-of-thought (CoT), before arriving at a final answer. Often, multiple chains are sampled and aggregated through a voting mechanism over the final answers, but the intermediate steps themselves are discarded. While such approaches improve performance, they do not consider the relations between intermediate steps across chains and do not provide a unified explanation for the predicted answer. We introduce Multi-Chain Reasoning (MCR), an approach which prompts large language models to meta-reason over multiple chains of thought, rather than aggregating their answers. MCR examines different reasoning chains, mixes information between them and selects the most relevant facts in generating an explanation and predicting the answer. MCR outperforms strong baselines on 7 multi-hop QA datasets. Moreover, our analysis reveals that MCR explanations exhibit high quality, enabling humans to verify its answers.
QAMPARI: : An Open-domain Question Answering Benchmark for Questions with Many Answers from Multiple Paragraphs
May 26, 2022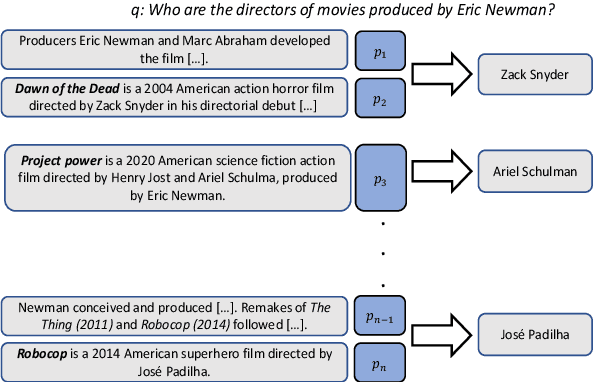

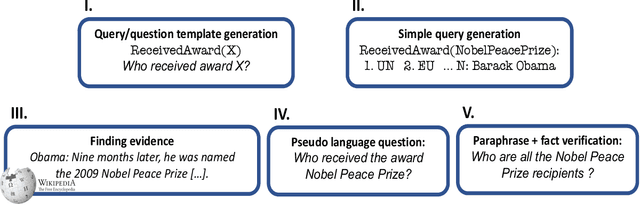
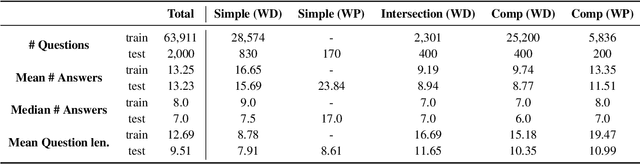
Existing benchmarks for open-domain question answering (ODQA) typically focus on questions whose answers can be extracted from a single paragraph. By contrast, many natural questions, such as "What players were drafted by the Brooklyn Nets?" have a list of answers. Answering such questions requires retrieving and reading from many passages, in a large corpus. We introduce QAMPARI, an ODQA benchmark, where question answers are lists of entities, spread across many paragraphs. We created QAMPARI by (a) generating questions with multiple answers from Wikipedia's knowledge graph and tables, (b) automatically pairing answers with supporting evidence in Wikipedia paragraphs, and (c) manually paraphrasing questions and validating each answer. We train ODQA models from the retrieve-and-read family and find that QAMPARI is challenging in terms of both passage retrieval and answer generation, reaching an F1 score of 26.6 at best. Our results highlight the need for developing ODQA models that handle a broad range of question types, including single and multi-answer questions.